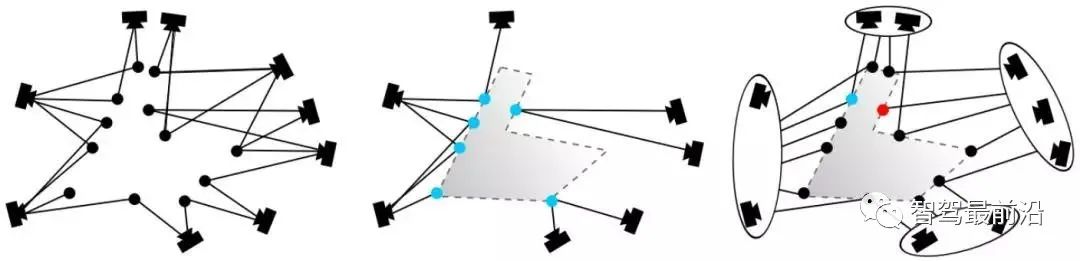
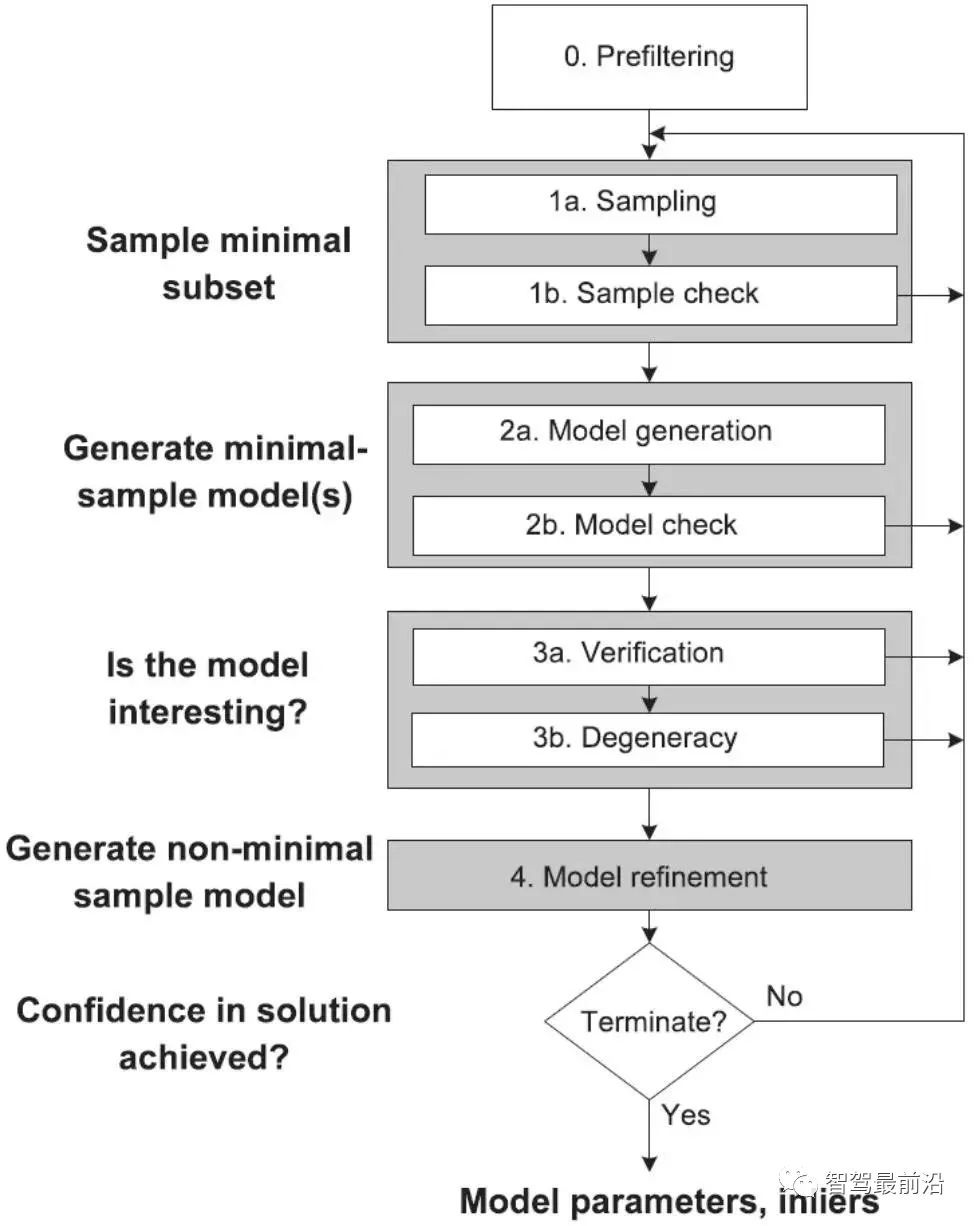
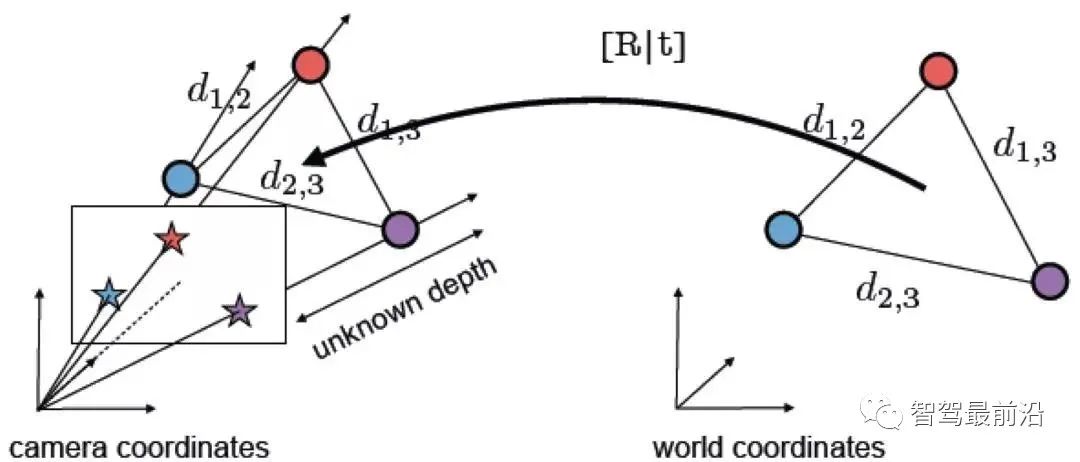
Figure 14: (上)原始特征匹配;(下)经过 RANSAC 算法优化后的匹配其中,初始候选匹配是根据描述子之间的距离产生的,但重投影误差则只和关键点的空间位置有关, 与描述子本身无关。具体投影矩阵方法请参考“2.4 位姿计算”。需要指出的是,RANSAC 算法受到原始匹 配误差和参数选择的影响,只能保证算法有足够高的概率合理,不一定得到最优的结果。算法参数主要包括阈值和迭代次数。RANSAC 得到可信模型的概率与迭代次数成正比,所得到的匹配数量和阈值成反比。因此实际使用时,可能需要反复尝试不同的参数设置才能得到较优的结果。 学者们对经典 RANSAC 算法进行了很多改进,如 Fig. 15所示,提出了全局 RANSAC(Universal- RANSAC)[17] 的结构图,形成了具有普适性的 RANSAC 架构,涵盖了几乎所有的 RANSAC 的改进方 面,如预滤波、最小子集采样、由最小子集生成可靠模型、参数校验、模型精化。Figure 15: Universal-RANSAC 通用算法框架可微分 RANSAC由于手工描述子在定位领域依然表现出较高的性能,所以一些学者开始探索使用深度学习代替算法框架中的某些部分,而不是直接使用端到端的位姿估计模型完全代替传统方法。可微分 RANSAC(Differentiable RANSAC,DSAC)[18] 旨在用概率假说选择代替确定性假说选择,使得 RANSAC 过程可以被求导,流程如 Fig. 16所示,其中“Scoring”步骤依然采用重投影误差作为指标,所不同的是,误差是基于整张图像而不是特征点,而原先筛选特征点匹配的过程被换为了直接以概率筛选相机位姿假设 h 的过程。虽然目 前方法局限性比较大,但 DSAC 为如何在当前无监督为主的定位算法框架中加入先验知识,提供了一种可行的思路。Figure 16: 差分 RANSAC 算法框架位姿计算对于已获得的正确匹配点对,需要通过几何约束计算相应的变换矩阵 (Transformation matrix) 。由于数据库中的点坐标,采样时的相机位姿已知,所以可以通过匹配点对于地图点的变换矩阵,得到当前相机的位姿。此处定义一些基本符号。相机内参为 ,变换矩 的齐次形式为:其中, 为旋转矩阵, 为平移矩阵。2.4.1 2D-2D 变换矩阵计算Figure 17: 2D-2D 变换矩阵计算中的对极几何对于两张二维图像中的已匹配好的特征点对 () ,它们在归一化平面上的坐标为 (),需要通过对极约束计算出相应的变换矩阵。如 Fig. 17所示,其几何意义是 三者共面,这个面也被称为极平面, 称为基线, 称为极线。对极约束中同时包含了平移和旋转,定义为:其中, 是 在归一化平面上的坐标,∧ 是外积运算符。将公式中间部分计为基础矩阵 和本质矩阵 ,则有:由于本质矩阵 不具有尺度信息,所以 E 乘以任意非零常数后对极约束依然成立。 可以通过经典的 8 点法求解(Eight-point-algorithm),然后分解得到 , 。因此可以看出 2D-2D 的变换矩阵求解方式有两个缺点,首先单目视觉具有尺度不确定性,尺度信息需要在初始化中由 提供。相应地,单目初始化不能只有纯旋转,必须要有足够程度的平移,否则会导致 为零。2D-3D 变换矩阵计算2D-3D 匹配是位姿估计中重要的一种方法。一般使用 PnP 法,即已知 对 2D-3D 匹配点,求解变换矩阵,以获得相机位姿。我们将 3D 点 P(X, Y, Z) 投影到相机成像平面 () 上:其中, 为尺度, 。这个等式的求解可以化为一个线性方程问题,每个特征可以提供两个线性约束:这样,最少可以通过 6 对匹配点进行求解,而匹配数大于 6 时可以使用 SVD 等方法通过构造最小二乘 求解。P3P 法可以看作是 PnP 法的特殊解法,如 Fig. 18所示,利用三角形相似性质增加更多约束,只需要 3 对点就可以求解。其它解法还有直接线性变换法 (Direct linear transformation,DLT),EPnP(Efficient PnP) 法,和 UPnP(Uncalibrated PnP)等。相对于以上线性优化方法,非线性优化方法如Bundle Adjustment(BA) 也有着广泛的应用。BA 方法在视觉 SLAM 中是一种“万金油”的存在,可以同时优化多个变量,这样可以一定程度缓解局部误差带来的系统不鲁棒,感兴趣的同学可以翻阅相关资料更深入地进行了解。Figure 18: 2D-3D 变换矩阵计算中的 P3P 方法3D-3D 变换矩阵计算3D 点之间的变换矩阵可以用迭代最近点(Iterative closet point, ICP)算法求解。假设点对匹配 () 结果正确,则求得的转换矩阵应当尽量减少重投影误差 。可以使用 SVD 求解最小二乘问题:或者使用建立在李代数上的非线性优化方法 Bundle Adjustment 求解其中, 表示相机位姿。这里的优化目标与 2D-3D 匹配中的 Bundle Adjustment 的类似,但是不需要考虑相机内参 ,因为通过双目相机或者 RGB-D 深度相机,已经把原本图像上的 2D 点从相机成像平面投影到 3D 世界中。ICP 问题已经被证明存在唯一解和无穷多解的情况。因此,在存在唯一解的情况下,优化函数相当于是一个凸函数,极小值即是全局最优解,无论采取何种初始化,都可以求得这一唯解。这是 ICP 方法的一大优点。本文从图像描述、建图查询、特征匹配,位姿计算四个方面介绍了基于特征点的位姿估计算法。虽然传统视觉全局定位方法目前依然是实际应用中的首选,但是,传统方法是建立在特征点被正确定义、正确提取、正确匹配、正确观测的前提下进行的,这一前提对于视觉本身而言就是巨大的挑战。其次,由于传统方法是 multi-stage 框架,而非 end-to-end,所以中间每个环节,环节之间的交互,都需要众多参数调整,每个环节的技术都可以作为一个单独的研究方向。实际应用时,也需要加入对应具体场景的大量tricks,工程上比较复杂。而人们对 end-to-end 方法的期望催生出了如 PoseNet,VLocNet,HourglassNet 等网络,在 benchmark上取得了不错的成绩。笔者认为目前 end-to-end 的方法还存在很多问题,主要有 loss function 缺少几何 约束,建图时位姿的 6 自由度空间并不连续,与输入空间难以形成良好映射,而且缺少相应的位姿回归、 精化机制等。不能否认,作为非线性空间最有力的建模工具,深度学习在未来会更多地出现在定位领域中。回归到视觉定位本身,由于视觉最重要的优势就是成本低、语意丰富、使用场景限制少。因此,以视觉为主,其它低成本传感器为辅的定位融合方案在未来也将会是一个重要的课题。参考资料[1] Dalal, N., and B. Triggs. ”Histograms of oriented gradients for human detection.” CVPR, 2005.[2] Lowe, David G. ”Distinctive Image Features from Scale-Invariant Keypoints.” IJCV, 2004.[3] Bay, Herbert, T. Tuytelaars, and L. V. Gool. ”SURF: Speeded Up Robust Features.” ECCV, 2006.[4] P.F.Alcantarilla,J.Nuevo,andA.Bartoli.Fast explicit diffusion for accelerated features in nonlinear scale spaces. BMVC, 2013.[5] Ojala, Timo. ”Gray Scale and Rotation Invariant Texture Classification with Local Binary Patterns.” ECCV, 2000.[6] Rublee, Ethan , et al. ”ORB: An efficient alternative to SIFT or SURF.” ICCV, 2011.[7] Leutenegger, Stefan , M. Chli , and R. Y. Siegwart . ”BRISK: Binary Robust invariant scalable keypoints.” ICCV, 2011[8] Alahi, Alexandre , R. Ortiz , and P. Vandergheynst . ”FREAK: Fast retina keypoint.” CVPR, 2012.[9] Witkin, A P, M. Baudin, and R. O. Duda. ”Uniqueness of the Gaussian Kernel for Scale-Space Filtering.” TPAMI, 1986.[10] Jegou, Herve , et al. ”Aggregating local descriptors into a compact image representation.” CVPR, 2010.[11] Torii, Akihiko , et al. ”24/7 place recognition by view synthesis.” CVPR, 2015.[12] Arandjelovic, Relja, et al. ”NetVLAD: CNN architecture for weakly supervised place recognition.” TPAMI, 2017.[13] Li, Fei Fei . ”A Bayesian Hierarchical Model for Learning Natural Scene Categories. CVPR, 2005.[14] Galvez-Lopez, D. , and J. D. Tardos . ”Bags of Binary Words for Fast Place Recognition in Image Sequences.” TRO, 2012.[15] Sattler, Torsten , B. Leibe , and L. Kobbelt . ”Efficient & Effective Prioritized Matching for Large- Scale Image-Based Localization.” TPAMI, 2016.[16] Fischler, Martin A., and R. C. Bolles. ”Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.” Communications of the ACM, 1981.[17] Raguram, Rahul , et al. ”USAC: A Universal Framework for Random Sample Consensus.” TPAMI, 2013.[18] Brachmann, Eric, et al. ”DSAC —Differentiable RANSAC for Camera Localization.” CVPR, 2017.



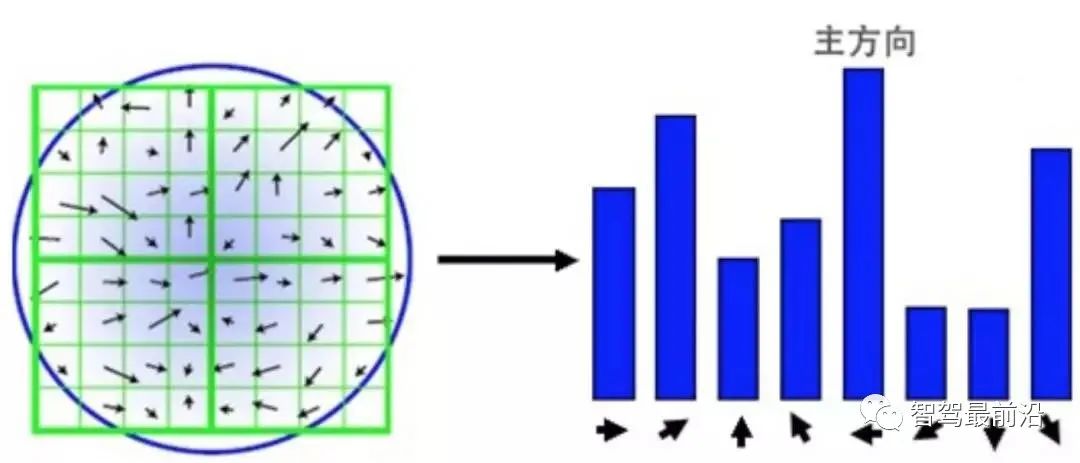
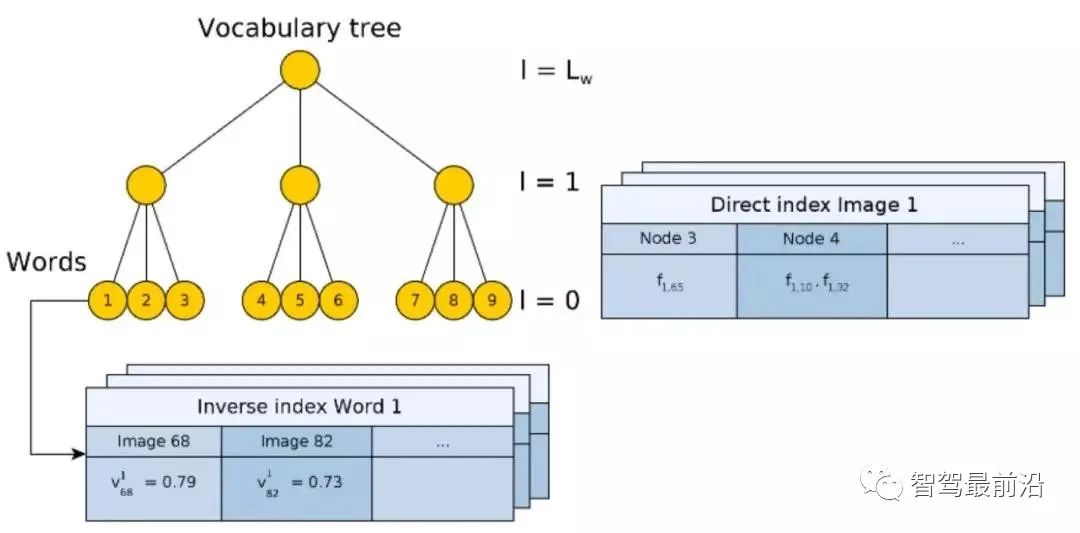
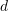 维描述子
维描述子  通过
通过 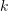 个码词的码本进行编码,可以形成一个
个码词的码本进行编码,可以形成一个  维的描述向量,向量中的值是描述子与第
维的描述向量,向量中的值是描述子与第  归一化,形成最后的 VLAD 向量。
归一化,形成最后的 VLAD 向量。
 张图的权重
张图的权重 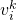 (Fig.10)。这里权重使用 TF-IDF(Term frequency–inverse document frequency) 计算。即如果一个词
(Fig.10)。这里权重使用 TF-IDF(Term frequency–inverse document frequency) 计算。即如果一个词 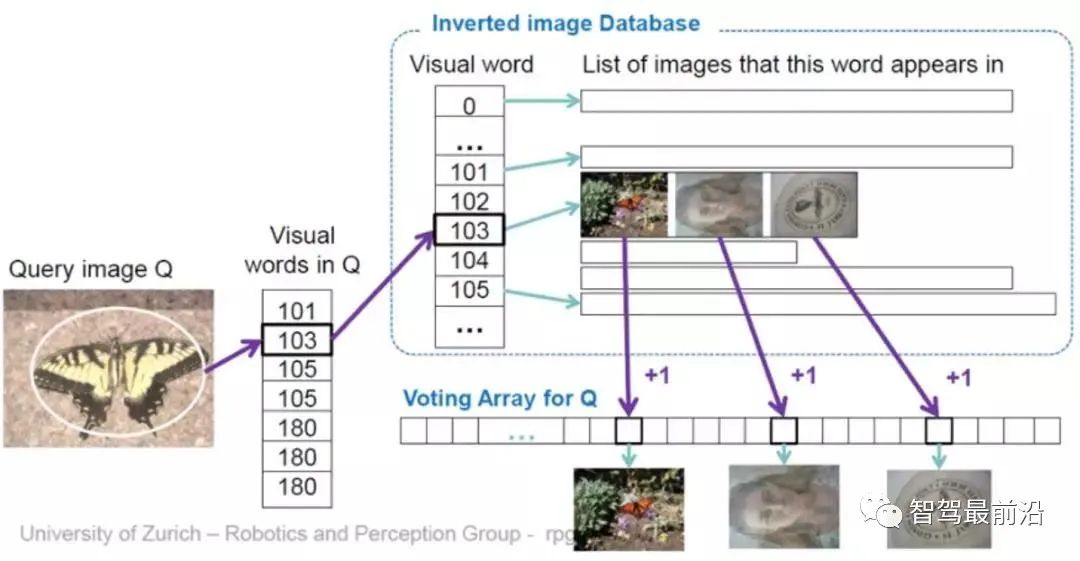


 ,变换矩
,变换矩  的齐次形式为:
的齐次形式为: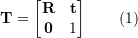
 为旋转矩阵,
为旋转矩阵, 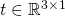 为平移矩阵。
为平移矩阵。
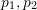 ) ,它们在归一化平面上的坐标为 (
) ,它们在归一化平面上的坐标为 ( ),需要通过对极约束计算出相应的变换矩阵。如 Fig. 17所示,其几何意义是
),需要通过对极约束计算出相应的变换矩阵。如 Fig. 17所示,其几何意义是  三者共面,这个面也被称为极平面,
三者共面,这个面也被称为极平面, 称为基线,
称为基线, 称为极线。对极约束中同时包含了平移和旋转,定义为:
称为极线。对极约束中同时包含了平移和旋转,定义为:
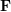 和本质矩阵
和本质矩阵  ,则有:
,则有:
 ,
, 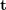 。因此可以看出 2D-2D 的变换矩阵求解方式有两个缺点,首先单目视觉具有尺度不确定性,尺度信息需要在初始化中由
。因此可以看出 2D-2D 的变换矩阵求解方式有两个缺点,首先单目视觉具有尺度不确定性,尺度信息需要在初始化中由  对 2D-3D 匹配点,求解变换矩阵,以获得相机位姿。我们将 3D 点 P(X, Y, Z) 投影到相机成像平面 (
对 2D-3D 匹配点,求解变换矩阵,以获得相机位姿。我们将 3D 点 P(X, Y, Z) 投影到相机成像平面 ( ) 上:
) 上: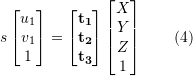
 为尺度,
为尺度, 。这个等式的求解可以化为一个线性方程问题,每个特征可以提供两个线性约束:
。这个等式的求解可以化为一个线性方程问题,每个特征可以提供两个线性约束:
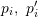 ) 结果正确,则求得的转换矩阵应当尽量减少重投影误差
) 结果正确,则求得的转换矩阵应当尽量减少重投影误差 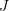 。可以使用 SVD 求解最小二乘问题:
。可以使用 SVD 求解最小二乘问题:
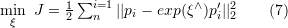
 表示相机位姿。这里的优化目标与 2D-3D 匹配中的 Bundle Adjustment 的类似,但是不需要考虑相机内参
表示相机位姿。这里的优化目标与 2D-3D 匹配中的 Bundle Adjustment 的类似,但是不需要考虑相机内参 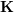 ,因为通过双目相机或者 RGB-D 深度相机,已经把原本图像上的 2D 点从相机成像平面投影到 3D 世界中。
,因为通过双目相机或者 RGB-D 深度相机,已经把原本图像上的 2D 点从相机成像平面投影到 3D 世界中。