
NAS: One-Shot方法总结

极市导读
在NAS过程中,最为耗时的其实就是对于候选模型的训练,本文主要详细介绍了One-Shot Architecture Search方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
NAS概述
当前使用的网络结构大部分是由人手工设计的,但是手工设计网络是耗时的且容易出错。因此,neural architecture search(NAS)变的流行起来。
NAS的工作可以根据三个方面进行划分:search space(搜索空间)、search strategy(搜索策略)、performance estimation strategy(性能评估策略)。
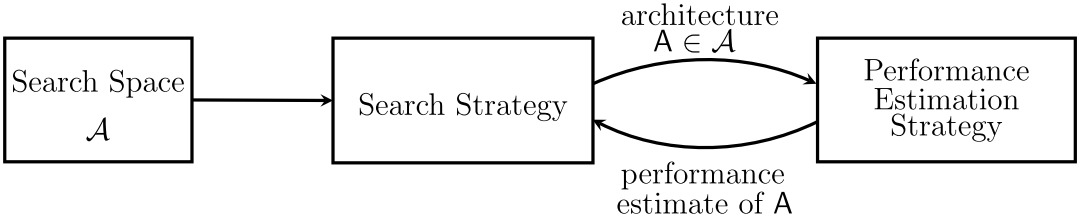
Search Space:搜索空间定义为在一定原则下可以表示的结构。引入适合任务的先验知识能够减少搜索空间并且简化搜索。然而,这也会引入人为偏差,阻碍寻找到新颖的超出当前人类知识的结构构建模块。
Search Strategy:搜索策略详细说明如何探索搜索空间。它包含了典型的探索-开发的权衡,一方面,希望能够快速找到优良的结构,另一方面,希望避免提前收敛到结构次优的区域。
Performance Estimation Strategy:NAS典型目标是找到在未知数据上能够得到高性能的结构。性能评估是涉及评估性能的过程:最简单的方式是在数据上执行标准的训练和验证,不幸的是该过程计算昂贵并且能够探索的结构数量受限制。
Search Strategy目前有三种流行的搜索方法:Reinforcement Learning(RL)、Evolutionary Algorithm(EA)、Gradient Based(GB)
列一下相关论文,不具体细讲了。
RL
EA
GB
DARTS: Differentiable Architecture Search
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
在NAS过程中,最为耗时的其实就是对于候选模型的训练。而初版的NAS因为对每个候选模型都是从头训练的,因此会相当耗时。一个直观的想法是有没有办法让训练好的网络尽可能重用。
一种思路是利用网络态射从小网络开始,然后做加法。
另一种思路是从大网络开始做减法,如One-Shot Architecture Search方法。
本文主要讲一下最近比较火的One-Shot(主要涉及到的论文有:SMASH、ENAS、One-Shot、DARTS、ProxylessNAS、FBNet、SPOS、Single-Path NAS、FairNAS)。
One-Shot
Example
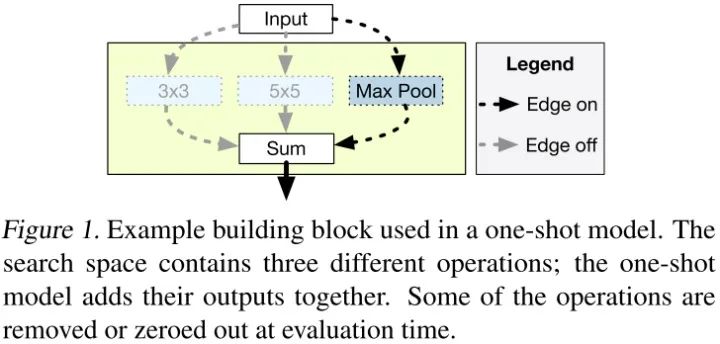
One-Shot模型的一个例子如图所示,我们可以在网络的特定位置使用3x3卷积、5x5卷积或最大池层三种操作的一种。不同于训练三个单独的模型,one-shot方法可以训练包含三种操作的单个模型。在评估时,可以选择将其中两种操作进行置零来确定哪种操作的预测精度最高。
1.SMASH
SMASH的目标是根据每个配置的验证性能来对一组神经网路配置进行相对排序,这个过程通过一个辅助网络产生的权值来完成。在每个训练阶段,我们随机采样一个网络架构(权值由HyperNet产生),并且通过BP端到端训练。当模型完成训练时,我们采样一些随机架构(权值由HyperNet产生)并且在验证集上评估性能。我们随后选择性能最佳的架构并且训练它的权值。伪码如下:

Defining Variable Network Configuration
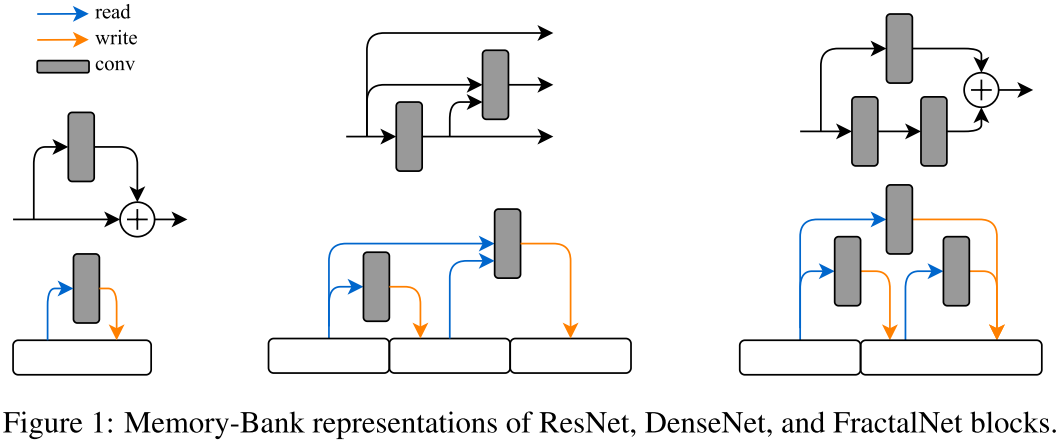
不同于将网络看作一系列应用于前向传播信号的操作,我们将网络看作一系列可读可写的存储体(初始张量用0填充)。每层可以看成一个从存储子集中读取数据,修改数据,并且将结果写到另一个存储子集的操作。
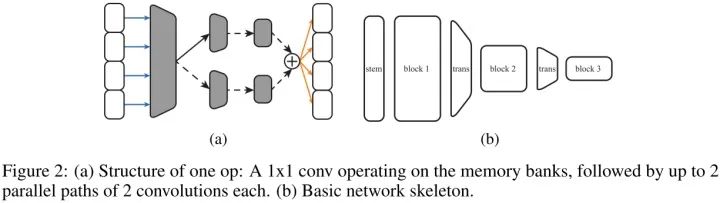
我们基础网络结构由多个模块组成,对于给定的空间分辨率下每个模块有一系列存储体,与大多数CNN架构一样,空间分辨率不断减半。下采样通过一个1x1卷积和平均池化完成,1x1卷积和全连接输出层的权值自由学习。
当下采样一个架构时,每个模块中,存储体的数量和每个存储体通道数是随机采样的。当定义模块的每层时,我们随机选择读写模式并且在读取数据时执行OP。当从多个存储体中读取时,我们沿着通道维度concat读取的张量,当写入存储体时,我们把当前每个存储体的张量加起来。
每个OP由1x1卷积(减少输入通道数)和数量不等带非线性的卷积组成,如图2(a)。我们随机选择四个卷积哪个是激活的,以及它们的滤波器大小、膨胀因子、组数和输出单元数(即层大小)。1x1 conv的输出通道数是op输出通道数的“瓶颈比”。
Learning to map architectures to weights
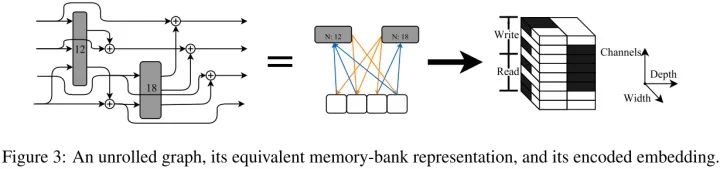
我们提出一个Dynamic Hypernet的变体,能基于主要网络结构 编码的张量产生权值 。我们的目标是去学习一个映射 ,对于任何给定的输入该映射合理的接近最优 ,因此我们能够基于验证误差排序每个 。因此,我们采用了一种 的排布策略,以便能够对拓扑结构进行采样,并与标准库中的工具箱兼容,并使 的维度尽可能具有可解释性。
我们的HyperNet是全卷积的,以至于输出张量 的维度随着输入 的维度变化,我们得到标准格式BCHW的4D张量,批量大小为1,这样没有输出元素是完全独立的。这允许我们通过增加c的高度或宽度来改变主要网络的深度和宽度。根据这一策略, 的每一片空间维度对应于 的一个特定子集。OP的信息通过 子集嵌入在通道维度相应的 片来描述的。
2.ENAS
参考:王佐:ENAS的原理和代码解析
神经网络架构的搜索空间可以表示成有向无环图(DAG),一个神经网络架构可以表示成DAG的一个子图。

上图是节点数为5的搜索空间,红色箭头连接的子图表示一个神经网络架构。图中节点表示计算,边表示信息流。**ENAS使用一个RNN(称为controller)决定每个节点的计算类型和选择激活哪些边。**ENAS中使用节点数为12的搜索空间,计算类型为tanh,relu,identity,sigmoid四种激活函数。
controller工作流程:
以节点数为4的搜索空间为例。
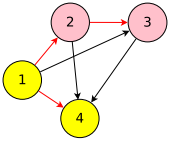
controller选择节点1的计算类型为tanh(节点1的前置节点是输入);选择节点2的前置节点为1,计算类型为ReLU;选择节点3的前置节点为2,计算类型为ReLU;选择节点4的前置节点为1,计算类型为tanh。
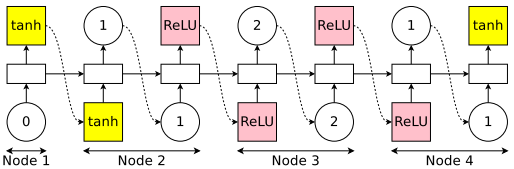
便得到如下的RNN神经网络架构:节点3和节点4是叶子节点,他们输出的平均值作为RNN神经网络架构的输出。该神经网络架构的参数由组成,其中 是节点 和节点 之间的参数。
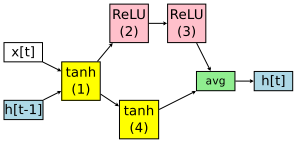
在NAS中, **都是随机初始化,并在每个神经网络架构中从头开始训练的。在ENAS,这些参数是所有神经网络架构共享的。**如果下一次controller得到的神经网络架构如下,它参数由 组成,其中 与上面神经网络架构相同的。
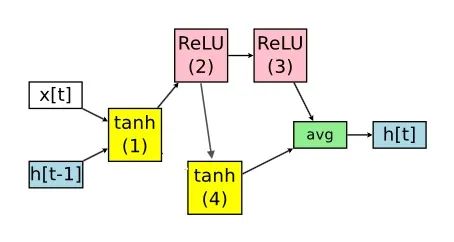
通过参数共享,ENAS解决了NAS算力成本巨大的缺陷。
ENAS工作流程:
loop
loop
controller固定参数 ,采样一个神经网络架构,在训练集中训练该神经网络架构,并通过SGD调整神经网络架构的参数 。
end loop
loop
controller采样一组神经网络架构,在验证集上计算ppl,并根据ppl和controller的交叉熵计算reward,通过Adam调整controller的参数。
end loop
end loop
3.One-Shot
参考:认真学习的陆同学:2018.07.11- One-Shot -ICML 2018
作者总结One-Shot模型的方法为4步:使用One-Shot模型设计搜索空间-训练-评估-选出有潜力的模型从头训练再评估。
1.设计搜索空间
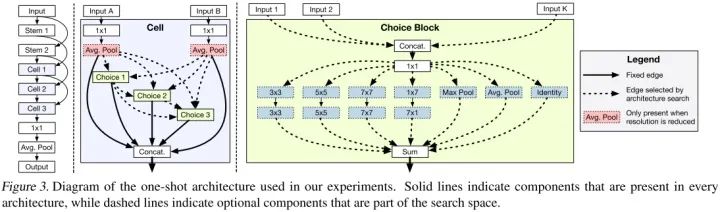
中间的三个Cell是相同的,每个Cell的构造如上图第二部分所示,但是在本文的实验中作者设定的Choice Block为4,图中少画了一个。每个Choice Block的构造如上图第三部分所示,设定每个Choice Block只能接受最多两个最近Cell 的输入,或者同一个Cell中其他Choice Block的输入,所以每个Choice Block可接受最少1个输入,最多7个输入。每个Choice Block中有7个可选操作,最多每次选2个操作,最少每次选1个操作。
2.使用SGD-M训练One-Shot模型:
(1)考虑模型的鲁棒性:因为评估的时候会去掉大量的分支,只留下所选择的路径,所以模型需要具备去掉分支后进行评估的鲁棒性,在训练的过程中使用Dropout来解决这一问题。
(2)稳定模型的训练:因为One-Shot模型的训练在早期是非常不稳定的,同时还在训练中引入了Dropout,所以训练很困难。作者引入了**“A variant of ghost batch normalization (Hoffer et al., 2017)”**来解决这一问题。
(3)防止过度正则化:让L2正则化只对当前模型的部分起作用。
4.DARTS
DARTS 思想是直接把整个搜索空间看成supernet,学习如何sample出一个最优的subnet。这里存在的问题是子操作选择的过程是离散不可导,故DARTS 将单一操作子选择松弛软化为 softmax 的所有操作子权值叠加。
1.搜索空间
DARTS搜索示意图如下所示:
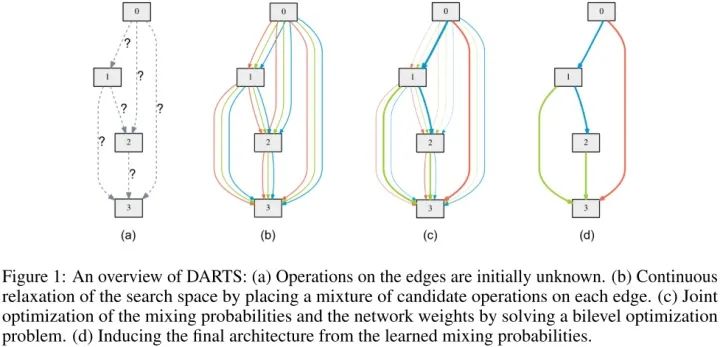
(a) 定义的一个cell单元,可看成有向无环图,里面4个node,node之间的edge代表可能的操作(如:3x3 sep 卷积),初始化时unknown
(b) 把搜索空间连续松弛化,每个edge看成是所有子操作的混合(softmax权值叠加)
(c) 联合优化,更新子操作混合概率上的edge超参(即架构搜索任务)和 架构无关的网络参数
(d) 优化完毕后,inference 直接取概率最大的子操作即可
cell中每个结点的值都是由其之前所有结点值计算而来的,具体计算公式为:
$$x^{(i)}=\sum_{j搜索算法搜索的结果是某种特定结构的cell,比如cell中哪些结点之间有连线,连线上的操作是什么。但是到目前为止的搜索空间还是离散的。所以为了使搜索空间连续,作者为连线上的每一种操作赋上一个权重,所以对于连线上操作对于结点的操作可以表示为:
代表有向图中连线上操作的集合, 代表连接结点 的连线上操作 的权值。所以公式的含义就是使用连线上每个操作对结点进行操作,然后按照一定的权值将结果组合起来作为连线的输出。由于引入了参数权值 ,搜索空间变成连续空间的,而且 也可以通过反向传播算法学习更新。在结构搜索结束之后,也就是 学到之后,通过取每条连线上权值最大的操作作为连线的操作将结构离散化。数学表达式为:
3,近似优化
在优化过程中,除了需要优化更新结构参数 之外,还需要优化更新模型参数 。如果同时进行优化的话,可能不太行。因为只要 改变了,就需要重新计算 。所以作者采用了迭代近似优化的方法,即分开优化 和 。优化算法如下图所示:

首先,在给定模型 时,通过最小化训练集损失 获得更新后参数 。之后固定住 ,通过最小化验证集损失
获得更新后的结构参数 。
4,离散网络结构的获取
对于cell中的每个中间结点,从它的所有前结点中选择k个连线权重最大的结点作为它的前结点。其中连线权重是连线上不同操作权重中最大的那个权重。通常对于CNN结构,k取2,对于RNN结构,k取1。得到每个中间结点的前结点之后,选区操作权重最大的操作作为两个结点间的操作。
5.ProxylessNAS
参考:认真学习的陆同学:2018.12.02-ProxylessNAS-ICLR 2019
1、针对Darts和One-Shot只能在小型数据集如CIFAR-10上进行搜索,而在大型数据集会出现显存爆炸的问题,提出了无代理的架构搜索,即可直接在大型数据集如ImageNet上完成搜索任务。
2、通过对不同硬件平台的时延进行建模,实现可搜索满足特定时延的神经网络,同时首次提出应针对不同的硬件平台搜索不同的网络架构。
Method
1、建立搜索空间:
(1)主要借鉴Darts和One-Shot的思想,首先仍然建立超参数化网络,即每一条路径依然包含所有可能的操作:

(2)二值化所有路径使得在训练时只有一条路径被激活,并且每条路径的激活概率设定为p,在训练中每个操作的概率p会被不断调整(第一个公式代表以概率p二值化所有操作,第二个公式代表以概率p二值化后一条边的输出):
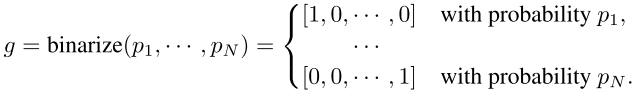
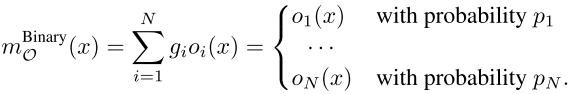
2、训练二值化网络:
首先固定架构参数在训练集训练网络权重(此时只有一条路被激活,所以占用显存低),然后固定网络权重在验证集训练架构参数,二者交替进行,类似于Darts中的训练方法(同样是一个双优化问题)。
在对架构参数进行梯度反传时,作者使用了近似估计的方法,如下公式所示。由于最右边的第一项偏导和候选操作数N有关系,为了避免显存爆炸,本文提出在更新架构参数时,取样两条路径,然后使用梯度反传更新这两条路径的架构参数,之后将二者参数乘一个比例系数从而保持其他未被采样的架构参数所占比重不变。
3、提出两种方法解决不可微的硬件指标:
(1)使时延可微:
对每个操作进行建模预测其时延,那么每条边的时延可表示为如下公式1,每条边时延的偏导为公式2,整个网络的时延为公式3,时延可微后直接放入损失函数如下公式4:
(2)强化学习方法:
作为二进制连接的一种替代方法,我们也可以利用强化学习来训练二进制权重。考虑网络关键参数 ,更新关键参数的目标是找到最优二进制门 来最大化奖励 。这里,为了便于说明,我们假设网络只有一个混合操作。我们对二值化参数的更新如下:
其中 表示第 个采样的二进制门, 表示采样 的概率。
6.FBNet
参考:雨宫夏一:CVPR2019 NAS 文章 (5)
DARTS有一个很严重的问题,那就是内存消耗,内存消耗导致了一系列速度很慢的问题,所以作者打算直接从搜索空间中采样,然后进行梯度更新,但是“采样”这个过程必然导致不可导的问题,所以FBNE采用了Gumbel function去代替求导的过程。
DARTS直接对权重值求softmax 下一层的输入为之前一层所有操作空间的加权求和。
在超级网络的推理过程中,只对一个候选块进行采样并执行,采样概率为:
包含了决定每个块在第 层采样概率的所有参数。同样,第 层的输出可以表示为:
其中 为{0,1}中的一个随机变量,如果对块 进行采样,则 的值为1。
而FBNet直接利用Gumbel softmax 来进行一次采样,然后直接求导。具体的来说:
Gumbel softmax 可以产生近似于one hot向量的输出。因此可以直接进行求导。
7.SPOS
参考:认真学习的陆同学:2019.03.31-Single Path One-Shot-arXiv 2019
1、本文的主要思想是将权重优化和架构参数搜索这一双优化问题解耦分成两个步骤来进行。首先对超网络不断进行均匀采样优化网络权重,然后通过进化算法可选择出满足不同约束的优秀网络架构。相对于之前的NAS方法,该文主要避免了在训练的过程中学习网络架构参数
,保证了在训练的过程中只有单一路径被激活(相比之前的ProxylessNAS,优化权重时单一路径激活,优化网络架构参数时需要两条路径被激活)。
2、由于在训练时不再同时优化网络权重和架构参数,所以在使用进化算法选择网络架构时可以精准满足不同的约束(如FLOPs和Latency等)。
3、基础的搜索块参照ShuffleNet v2设计,作者还提出可以搜索卷积层的输出通道数,同时还将本文方法应用于混合精度量化。
Method
1、单一路径的超网络和均匀采样:
之前的超网络训练是交替优化网络权重w和架构参数 :
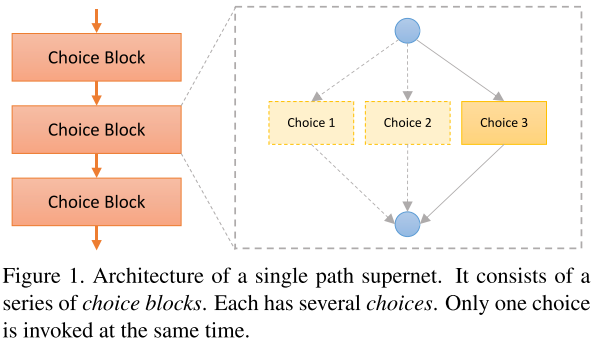
本文提出的方法只优化权重,每次网络架构都是被均匀采样:
2、通道搜索:
在训练时,让网络随机选择卷积的输出通道,权重训练好了以后使用进化算法选择表现优异的架构,此时选择出来的网络架构的通道就可理解为训练时网络随机搜索的。
3、进化算法搜索网络架构:

8.Single-Path NAS
参考:灵魂机器:论文解读:Single-Path NAS
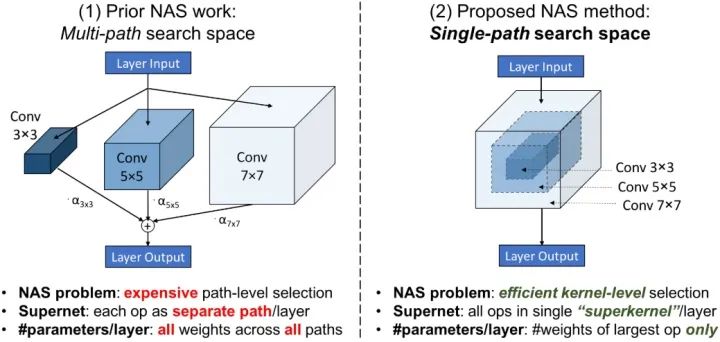
主要思想是用一个7x7的大卷积,来代表3x3,5x5,7x7的三种卷积,把外边一圈mask清零掉就变成了3x3或5x5,这个大的卷积表示为 superkernel,这样整个网络就只有一种卷积,看起来是一个直筒结构。这个操作相当于weight sharing,比如3x3的weights是和5x5,7x7的卷积共享的。
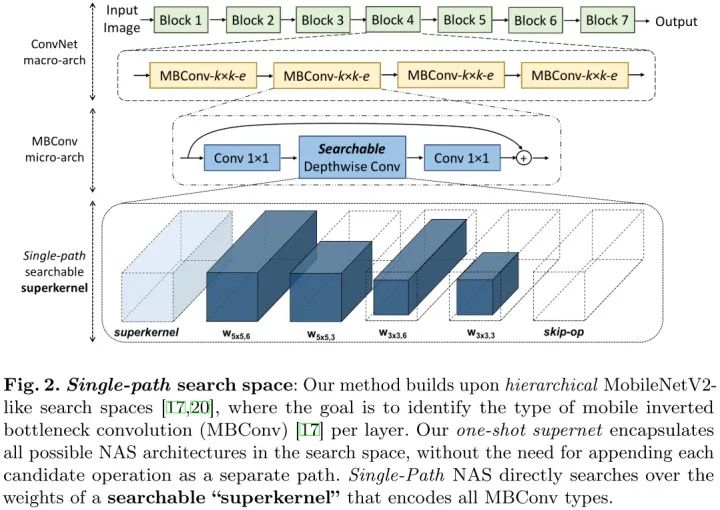
搜索空间
基于block的直筒结构,跟 ProxylessNAS, FBNet一样,都采用了Inverted Bottleneck 作为cell, 层数跟MobileNetV2都是22层。每层只有两个参数 expansion rate, kernel size 是需要搜索的。
superkernel
NAS中不同候选卷积操作可以看作一个参数过多的“超核”权值的子集。这样就可以把NAS看成一个寻找每个MBConv layer的核权值子集的组合问题,不同的MBConv结构选择共享核参数。
Single-Path NAS formulation
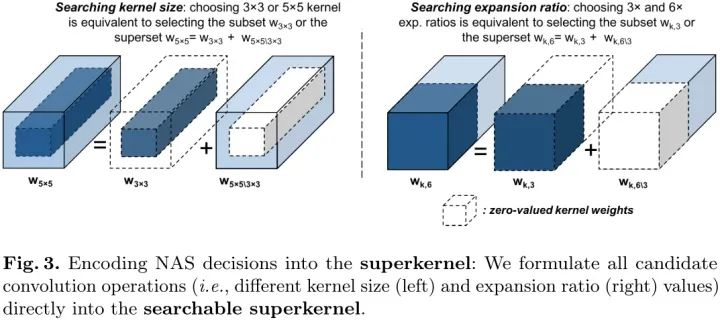
如图3(左)所示,我们观察到,3×3核的权值可以看作是5×5核的权值的内核,而将“外层”的权值“归零”。我们将这个(外部)权值子集表示为 。因此,使用5×5卷积的NAS架构选择既对应于使用内部 权值,也对应于使用外壳,即 (图3,左)。
因此,我们可以将NAS决策直接编码到一个MBConv层作为内核权值的函数如下:
其中 是对架构NAS选择进行编码的指示函数。
对于一个表示是否使用权值子集的指标函数,它的条件应该是权值子集的一个函数。因此,我们的目标是定义权值子集的“重要性”信号,该信号能够得到权值子集对总体损失的贡献。函数如下:
其中tk=5是一个潜在的变量,它控制选择5×5核的决定(例如阈值)。阈值将与Lasso项进行比较,以确定是否将外部 权值用于整个卷积。
由于基于核的NAS决策 的结果本身就是卷积核,因此我们可以将我们的公式应用于编码 的膨胀比的NAS决策。如图3所示(右),一个膨胀率为3的MBConv-k×k3层的通道数可以视为一个膨胀率为6的MBConv-k×k-6层通道数的一半,而置零的第二部分通道为 。如果同时置零第一项输出过滤器,那么添加到MBConv layer的残差连接时,整个超核将没有贡献(相当于skip-op)。通过确定e是否等于3,我们可以编码NAS只使用或不使用“skip-op”路径的决策。对于两个 核的决定,可以定义成:
因此,对于输入 ,网络第 个MBConv层的输出为:
9.FairNAS
参考:机器之心:超越MnasNet、Proxyless:小米开源全新神经架构搜索算法FairNAS
张俊:深度解读:小米AI实验室AutoML团队最新成果FairNAS
根据模型真实能力进行排序的能力是神经架构搜索(NAS)的关键。传统方法采用不完整的训练来实现这一目的,但成本依然很高。而通过重复使用同一组权重,one-shot 方法可以降低成本。但是,我们无法确定共享权重是否真的有效。同样不明确的一点是,挑选出的模型具备更好的性能是因为其强大的表征能力,还是仅仅因为训练过度。
为了消除这种疑问,作者提出了一种全新方法——Fair Neural Architecture Search (FairNAS),出于公平继承和训练的目的,该方法遵循严格的公平性约束。使用该方法,超网络训练收敛效果很好,且具备极高的训练准确率。与超网络共享权重的采样模型,在充分训练下的性能与独立模型(stand-alone model)的性能呈现出强烈的正相关。
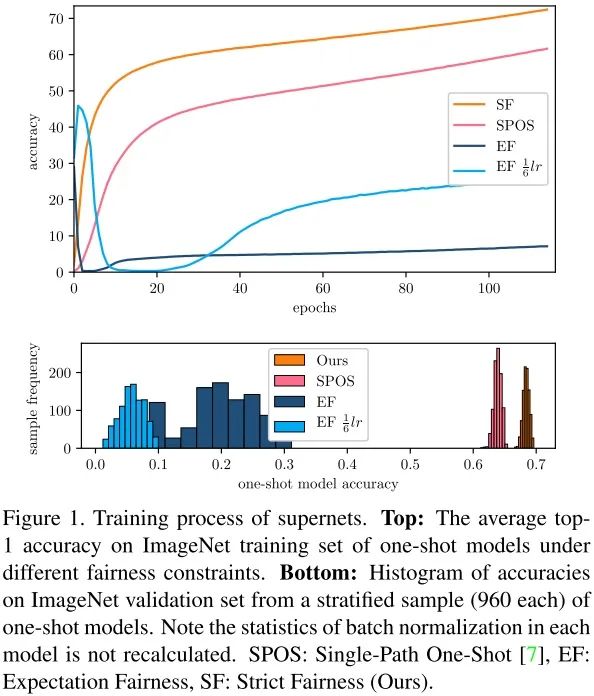
如上图所示,实验结果表明,在严格的公平性约束下,one-shot 模型在 ImageNet 训练集上的平均准确率稳步提升,没有出现振荡。与 EF相比,one-shot 模型的分层样本的准确率范围大大缩小。这是一个重大进展,研究者在快速评估模型的同时也能保证准确性。
FairNAS 解决了两个基础问题:
使用one-shot 超网络和采样技术得到不同子模型的方法真的公平吗? 如何根据模型性能进行快速排序,且排序结果具备较强的置信度?
具体而言,该研究具备以下贡献:
遵循严格公平性(strict fairness),强化 one-shot 方法; 在严格公平性条件下,实验结果表明平均准确率呈稳步上升,没有出现振荡(见图 1); 尽管 one-shot 方法极大地加速了估计,但研究人员仍然面对多个现实约束以及广阔的搜索空间,于是研究人员选择多目标 NAS 方法来解决这个需求; 使用该研究提出的 pipeline,可在 ImageNet 数据集上生成一组新的 SOTA 架构。
Strict Fairness
在某种程度上,所有 one-shot 方法都是预定义搜索空间中任意单路径模型的不同性能预测器代理(proxies for performance predictor)。好的代理不能过度高估或低估模型得分。而目前还没有人对该主题进行深入的研究,并且以往多数研究仅仅侧重于搜索得分较好的几个模型。
为了减少超网络训练过程中的先验偏置(prior bias),研究人员定义了基本和直接的要求,如下所示:

不难看出,只有单路径 one-shot 方法符合上述定义。
在超网络训练的每个步骤中,只有相应激活选择块(choice block)的参数能够得到更新。笼统来说,参数更新的目的是减少模型在小批量数据上的损失,因此它虽然能够帮助激活选择块得到比未激活选择块更高的分数,但同时也产生了偏差。
研究人员将这种减少此类偏差的直接和基本要求称之为 Expectation Fairness,其定义如下:

研究人员提出了用于公平采样和训练的更严格要求,称之为 Strict Fairness,其定义如下:
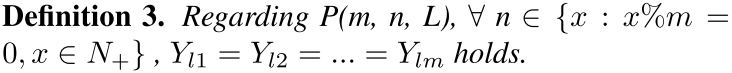
定义 3 施加了比定义 2 更严格的约束。定义 3 确保每个选择块的参数在任何阶段的更新次数相同,即 p(Y_l1 = Y_l2 = ... = Y_lm) = 1 在任何时候均成立。
Method
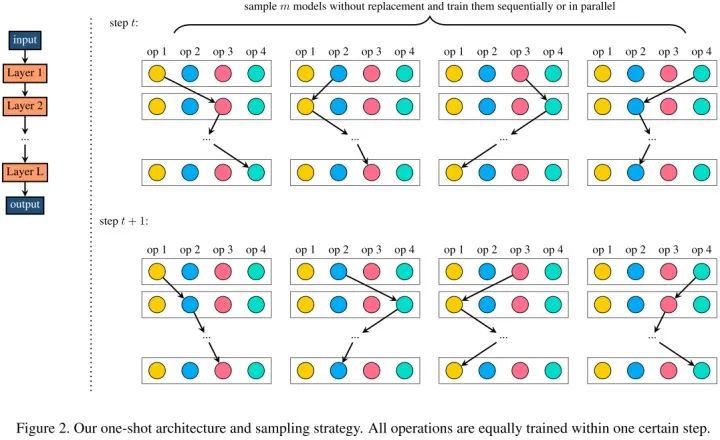
作者在严格遵循定义 3 的前提下,提出一种公平采样和训练算法(见 Algorithm 1)。使用没有替换的均匀采样,在一步中采样 m 个模型,使得每个选择块在每次更新时都被激活,参见下图 2:
算法 1 如下图所示:

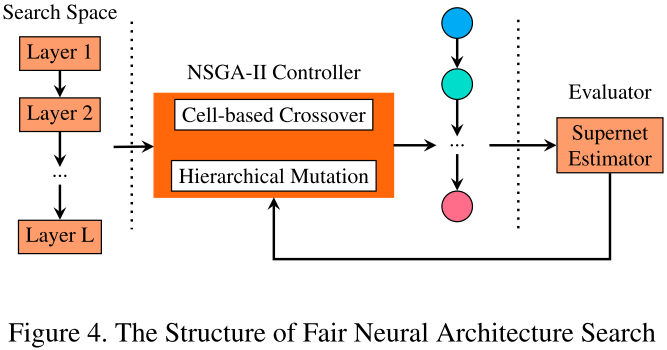
FairNAS 架构
提出的 FairNAS 架构如下图 4 所示:
总结
SMASH设计独立的hypernet来产生搜索空间中所有可能结构的权值,然而,hypernet的设计需要精细的专业知识,才能在采样模型的真实性能和生成的权值之间强相关。
ENAS其核心思想是让搜索中所有的子模型重用权重。它将NAS的过程看作是在一张大图中找子图,图中的边代表算子操作,基于LSTM的控制器产生候选网络结构(决定大图中的哪些边激活,以及使用什么样的操作),这个LSTM控制器的参数和模型参数交替优化。
One–Shot进一步构建one-shot模型,覆盖搜索空间中的所有操作。在评估阶段,一个子网络通过drop-connect其它连接来进行模拟。不幸的是,它依赖于超参数(如drop-out率和每个block的操作可选数量),这使得该方法的鲁棒性较差,必须采取特定的措施来稳定训练和防止过度正则化。另外,这样一个one-shot模型由于包含了所有的架构而存在内存爆炸的问题,当搜索空间增长时,内存变得太大而无法训练。
DARTS中最关键的是将候选操作使用softmax函数进行混合。这样就将搜索空间变成了连续空间,目标函数成为了可微函数。这样就可以用基于梯度的优化方法找寻最优结构了。搜索结束后,这些混合的操作会被权重最大的操作替代,形成最终的结果网络。
ProxylessNAS沿用了DARTS中连续松弛的方法和双优化的训练策略,将路径上的 arch parameter 二值化,在搜索时仅有一条路径处于激活状态。这样一来 GPU 显存就从 O(N) 降到了 O(1),解决了显存占用和 search candidates 线性增长的问题。对于不同的硬件平台,通过 latency estimation model,将延迟建模为关于神经网络的连续函数,并提出了 Gradient 和 RL 两种方法在搜索过程对其优化。
FBNet通过Gumbel function来替代求导过程,解决了直接从搜索空间采样无法梯度更新的问题,减少了内存消耗。
SPOS将权重优化和架构参数搜索这一双优化问题解耦分成两个步骤来进行,避免了在训练的过程中学习网络架构参数,保证了在训练的过程中只有单一路径被激活。由于在训练时不再同时优化网络权重和架构参数,所以在使用进化算法选择网络架构时可以精准满足不同的约束(如FLOPs和Latency等)。
Single-Path NAS用superkenel统一3x3和5x5两种卷积,把网络结构变成了single path,使得在search method上可以选择更加快速的优化方法。
FairNAS提出了要满足 Strict Fairness,这个约束条件是超网的每单次迭代让每一层可选择运算模块的参数都要得到训练。FairNAS 与 SPOS 的均匀采样不同,采取了不放回采样方式和多步训练一次参数更新的方式,这带来了one-shot 分布和 supernet 训练的整体提升。
总体趋势:搜索空间越来越小,计算效率越来越高,训练速度越来越快,不同子模型的训练越来越公平。
NAS应用
目标检测
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
DetNAS: Backbone Search for Object Detection
语义分割
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
实例分割
InstaNAS: Instance-aware Neural Architecture Search
ReID
Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification
视频动作识别
Video Action Recognition Via Neural Architecture Searching
References
欢迎交流指正~~
