
什么是数据湖?有什么用?终于有人讲明白了……

导读:数据湖概念的诞生,源自企业面临的一些挑战,如数据应该以何种方式处理和存储。最开始,企业对种类庞杂的应用程序的管理都经历了一个比较自然的演化周期。
最开始的时候,每个应用程序会产生、存储大量数据,而这些数据并不能被其他应用程序使用,这种状况导致数据孤岛的产生。随后数据集市应运而生,应用程序产生的数据存储在一个集中式的数据仓库中,可根据需要导出相关数据传输给企业内需要该数据的部门或个人。
然而数据集市只解决了部分问题。剩余问题,包括数据管理、数据所有权与访问控制等都亟须解决,因为企业寻求获得更高的使用有效数据的能力。
为了解决前面提及的各种问题,企业有很强烈的诉求搭建自己的数据湖,数据湖不但能存储传统类型数据,也能存储任意其他类型数据,并且能在它们之上做进一步的处理与分析,产生最终输出供各类程序消费。
在本文中,将介绍数据湖的一些主要方面,帮助读者理解为什么它对企业非常重要。
作者:汤姆斯·约翰 潘卡·米斯拉
来源:大数据DT(ID:hzdashuju)

数据湖与企业的关系

一个实体在企业中可能有多种表示形式,因此可能不存在某个完备的模型来统一表示实体。 不同的企业应用程序可能会基于特定的商业目标来处理实体,这意味着处理实体时会采用或排斥某些企业流程。 不同应用程序可能会对每个实体采用不同的访问模式及存储结构。

数据湖的优点
实现数据治理(data governance)与数据世系。 通过应用机器学习与人工智能技术实现商业智能。 预测分析,如领域特定的推荐引擎。 信息追踪与一致性保障。 根据对历史的分析生成新的数据维度。 有一个集中式的能存储所有企业数据的数据中心,有利于实现一个针对数据传输优化的数据服务。 帮助组织或企业做出更多灵活的关于企业增长的决策。

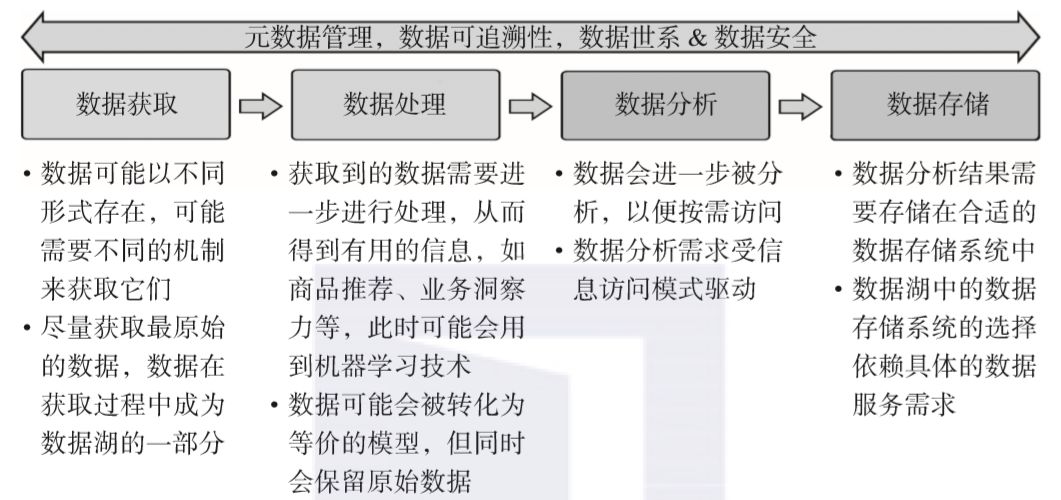
数据世系被定义为数据的生命周期,包括数据的起源以及数据是如何随时间移动的。它描述了数据在各种处理过程中发生了哪些变化,有助于提供数据分析流水线的可见性,并简化了错误溯源。 可追溯性是通过标识记录来验证数据项的历史、位置或应用的能力。 ——维基百科

只有当这些组织重新开始构建其信息系统时,这种方法才可行。 这种方法解决不了与现存系统相关的问题。 即使组织决定用这种方法构建数据湖,也缺乏明确的责任和关注点隔离(responsibility and separation of concerns)。 这样的系统通常尝试一次性完成所有的工作,但是最终会随着数据事务、分析和处理需求的增加而分崩离析。

延伸阅读《企业数据湖》
点击上图了解及购买
转载请联系微信:DoctorData

干货直达👇
评论