
解密得物Trace2.0:日PB级数据量下的计算与存储性能优化实战
目录
一、背景
二、客户端多通道协议
1. 采集多通道协议
三、计算模型
四、数据压缩
五、存储方案
六、升级 JDK21
1. 升级后效果
七、结语
一
背景
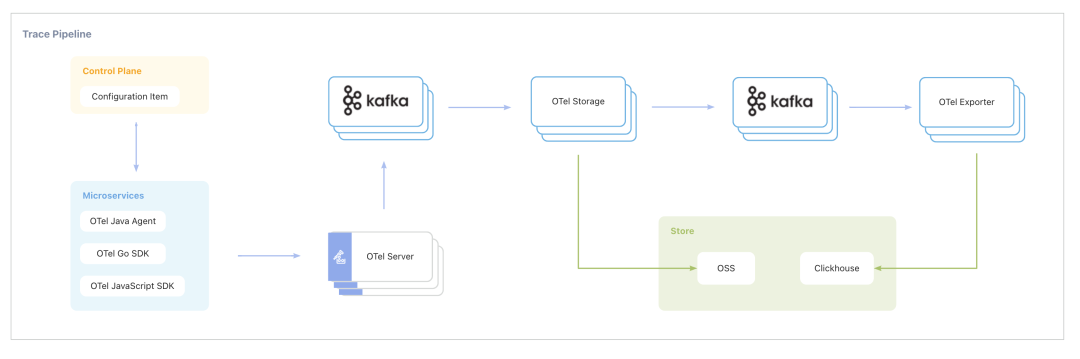
Trace2.0 是得物监控团队引入 OpenTelemetry 协议并落地的全新应用监控系统,从 2021 年底正式开始使用。在过去的两年里,我们面临着数据量呈爆炸式增长的巨大挑战。然而,通过对计算和存储的不断优化,我们成功地控制了机器数量的指数级增加。我们每天处理的日增数据量数 PB(相比去年增长了 4 倍),每天产生的 Span 数超过了数万亿条。系统面对的峰值流量可达到每秒几千万行 Span,每秒上报的带宽压缩后高达数十 GB。我们所使用的存储引擎 Clickhouse 单机支持每秒近百万行的写入量。这些数据成为 Trace2.0 作为一款强大的应用监控系统的标志,为监控团队提供了全方位的监控数据分析能力。Trace2.0 使得我们能够及时发现和解决潜在的系统问题,确保我们的服务能够始终稳定可靠地运行。
下面是整体的架构:
二
客户端多通道协议
在 OpenTelemetry 中,客户端会生成调用链信息并将其推送到远程服务器。 传输数据的请求协议通常包括 HTTP 和 gRPC。 gRPC 是基于 Google 开发的高性能开源 RPC 框架,使用二进制格式传输数据。 它具有较高的性能和较低的网络开销,适用于大规模应用和高并发场景。 gRPC 还提供自动化的数据序列化和反序列化,以及强类型的接口定义。
在 OpenTelemetry 中,默认使用的是 gRPC 协议进行上报。在 gRPC 中,使用长连接进行通信。然而,长时间的连接可能会导致一些问题,如服务器上的资源泄漏、连接状态不稳定或服务端单机负载过高。通过设置 maxConnectionAge 参数,可以限制连接的持续时间,确保不会因为长时间的连接而出现这些问题。
NettyServerBuilder.forPort(8081)
.maxConnectionAge(grpcConfig.getMaxConnectionAgeInSeconds(), TimeUnit.SECONDS)
.build();
随着数据量的快速增长,我们采用了基于负载均衡器(SLB)的方式 来实现后端机器的负载均衡。 然而,随着全量 Trace下超高流量需求的增加,单个 SLB 的带宽已经无法满足要求。 为解决这个问题,我们决定增加 SLB 数量,每个后端服务器开启多个端口,并使每个 SLB 实例绑定一个端口。 这样通过水平扩展 SLB,可以改善负载分担。
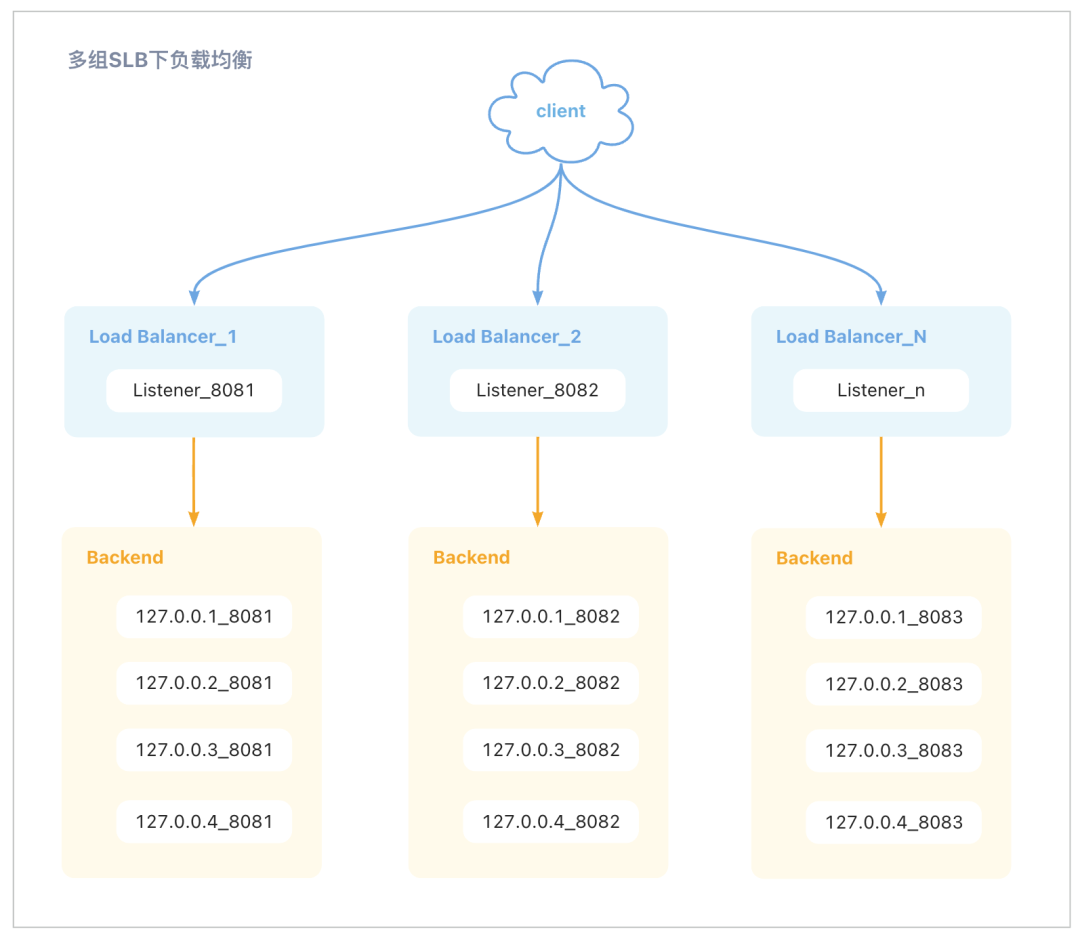
然而,随着 SLB 数量的增加,维护成本也随之增加,并且仍然可能导致某个后端服务器负载较高,形成热点问题。为了解决这个问题,我们做出了一个决定——去除 SLB,直接将流量分担到后端服务器上。这样做不仅可以简化系统架构,还可以更均衡地分配负载,提高整体性能。
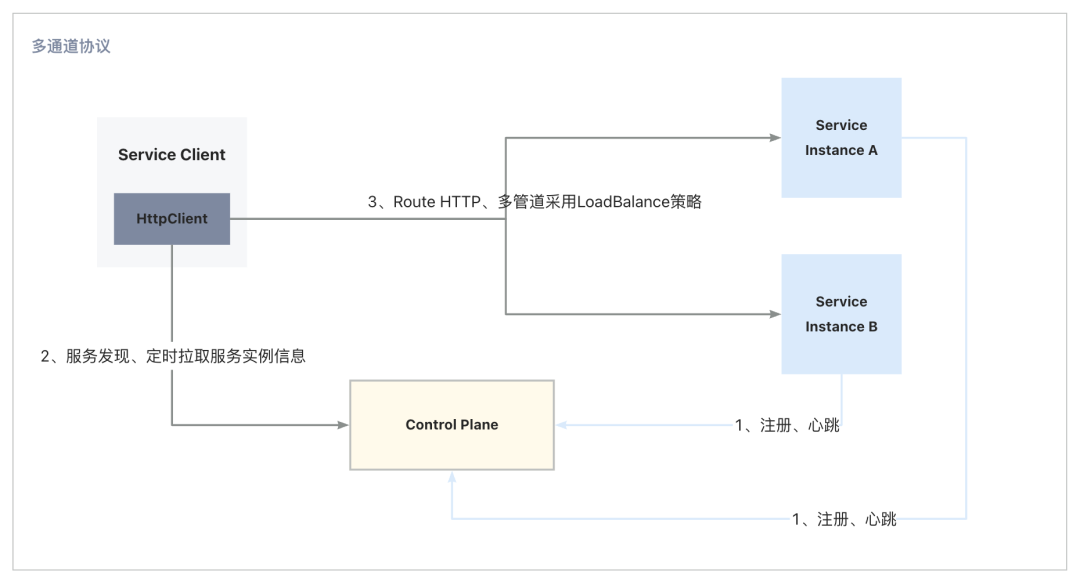
采集多通道协议
-
服务注册和心跳:服务端启动后,会向控制平面注册服务信息,并定时发送心跳来进行健康检查。如果服务端在一定时间内没有进行心跳上报,控制平面将把其剔除。
-
定时拉取服务列表:客户端通过和控制平面进行通信,定时获取最新的服务端实例信息。通过这种方式,客户端可以获得最新的服务端列表,以保证与可靠的后端实例进行通信。
-
多通道协议:在多通道协议中,不再使用负载均衡器,而是直接将请求发送到多个后端服务器上。每个后端服务器都可以独立处理请求,实现流量的均衡负载,提高系统性能,并且减轻热点问题的影响。
-
提高系统性能:通过直连后端服务器,可以充分利用每个服务器的计算能力和带宽,从而提高整个系统的性能和吞吐量。
-
减少维护成本:去除了负载均衡器,减少了系统的维护成本,避免了负载均衡器成为性能瓶颈的问题。
-
避免热点问题:直连后端服务器并分担流量的方式可以减轻系统中可能出现的热点问题,提高系统的稳定性和可靠性。
三
计算模型
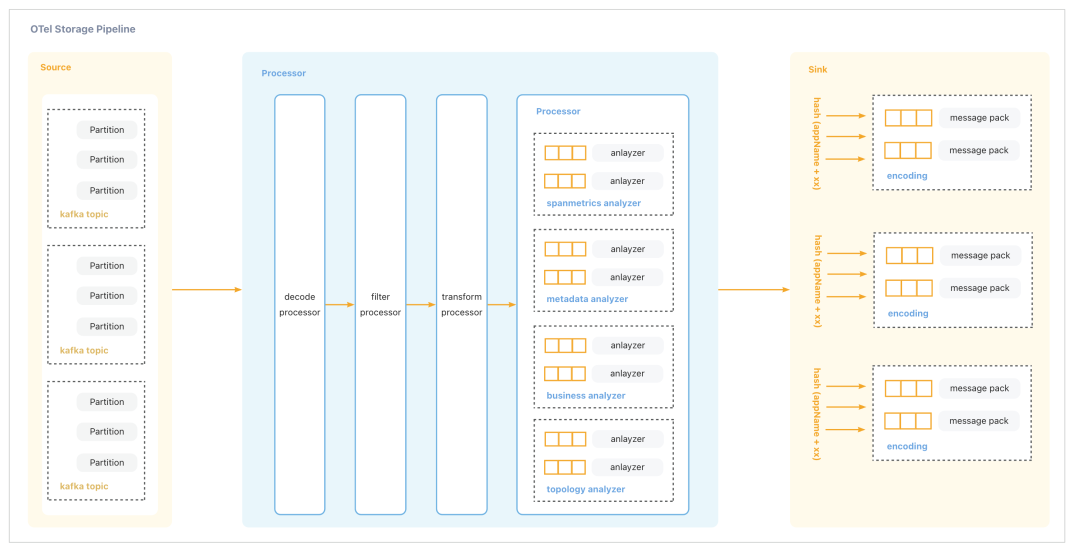
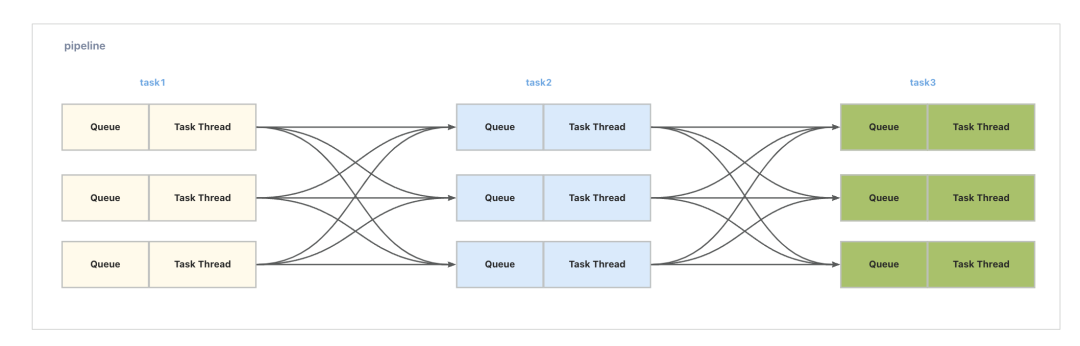
Trace2.0 后端的整体架构参考 Pipeline 架构。 在这个架构中,消息的采集会被放到队列里进行处理,处理之后再进行存储。 整个计算程序采用 Source、Processor、Sink 多管道多任务处理方式,下面是详细的流程:
component:
source:
kafka:
- name: "otelTraceKafkaConsumer" ## Trace消费
topics: "otel-span"
consumerGroup: "otel_storage_trace"
parallel: 1 # 消费的线程数
servers: "otel-kafka.com:9092"
targets: "decodeProcessor"
processor:
- name: "decodeProcessor"
clazz: "org.poizon.apm.component.processor.DecodeProcessor"
parallel: 4
targets: "filterProcessor"
- name: "filterProcessor"
clazz: "org.poizon.apm.component.processor.FilterProcessor"
parallel: 2
targets: "spanMetricExtractor,metadataExtractor,topologyExtractor"
- name: "spanMetricExtractor"
clazz: "org.poizon.apm.component.processor.SpanMetricExtractor"
parallel: 2
props:
topic: "otel-spanMetric"
targets: "otel_kafka"
- name: "metadataExtractor"
clazz: "org.poizon.apm.component.processor.MetadataExtractor"
parallel: 2
props:
topic: "otel-metadata"
targets: "otel_kafka"
- name: "topologyExtractor"
clazz: "org.poizon.apm.component.processor.MetadataExtractor"
parallel: 2
props:
topic: "otel-topology"
targets: "otel_kafka"
sink:
kafka:
- name: "otel_kafka"
topics: "otel-spanMetric,otel-metadata,otel-topology"
props:
bootstrap.servers: otel-kafka.com:9092
key.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
value.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
compression.type: zstd
-
客户端的 Trace 数据发送到服务端 OTel Server 后,根据应用的 AppName 发送到不同的 Kafka Topic 中。
-
接收到数据后,数据会经过反序列化、清洗、转换等模块的处理。
-
为了实现更高效的任务处理,系统选择了使用 Disruptor 缓冲队列。这个缓冲队列采用了多生产者单消费者的模式,可以有效地减少线程之间的竞争,提高系统的并发处理能力。
-
采用多任务多管道方式进行处理,通过缓冲队列将各个任务之间进行解耦。
-
每个任务都会采用特定的路由策略,例如轮询或哈希等,来确定该任务应该处理的数据。
通过以上架构和流程,系统能够实现高效的任务处理,减少线程竞争,并提高系统的并发处理能力。同时,任务间的解耦和路由策略的应用,使得系统能够根据具体需求对数据进行灵活的处理和分发。
四
数据压缩
为了提高数据的合并压缩比,我们采用了增加时间窗口并使用 keyBy 对数据进行分组的方法,将 Span 转换为 SpanList,并进行批量合并操作。 这样的流程中,我们无需事先将所有原始数据加载到内存中,而是逐个或者分块地将其写入到 ZstdOutputStream 中进行实时压缩处理。 压缩后的数据也不会一次性保存在内存中,而是通过 OutputStream 逐个或者分块地写入到 Kafka(或其他存储介质)中。 这种采用 OutputStream 和 Zstd 进行数据流式压缩的方式,有效地提升了数据的压缩率。
以下是压缩核心代码的示例:
private FixedByteArrayOutputStream baos;
private OutputStream out;
public void write(byte[] body) {
out.write(Bytes.toBytes(body.length));
out.write(body);
}
public byte[] flush() throws IOException {
out.close();
baos.flush();
byte[] data = baos.toByteArray();
baos.reset();
out = new ZstdOutputStream(baos);
return data;
}
public void initOutputStream() throws IOException {
this.baos = new FixedByteArrayOutputStream(4096);
this.out = new ZstdOutputStream(this.baos, 3);
}
通过线上数据观察,我们发现 Trace 索引数据的压缩比提高了 5 倍,而 Trace 明细数据(使用ZSTD Level 3)的压缩比更是提高了 17 倍。这意味着我们能以更低的存储成本和更高的存储效率来处理大量的监控数据。
五
存储方案
面对如此大的数据量(全量 Trace),平衡成本并确保存储系统如何支持如此高的 TPS 写入是业界关注的热门话题。以下是一些优化存储方案的关键策略:
-
优化存储引擎配置,包括缓冲区大小、日志刷新策略等,以提高性能。
-
水平扩展,采用分区和分片等技术对数据进行分布式存储,以及采用分布式存储引擎,如 Cassandra、HBase 等,来实现水平扩展,提高写入吞吐量。
-
异步写入,采用消息队列或异步处理来缓解写入压力,提高系统的写入并发能力。
-
批量写入,通过批量写入来减少写入操作的次数,减少对存储层的压力。
-
数据压缩和索引优化,采用高效的数据压缩算法和合理的索引策略,以减少存储空间占用和提高写入性能。
-
负载均衡和故障恢复,合理设计负载均衡策略,并实施有效的故障恢复机制,以确保系统在写入压力大时能够保持稳定和可靠。
-
监控和性能调优,持续监控系统的性能指标,进行性能调优,及时发现和解决性能瓶颈。
来看看我们的架构图:
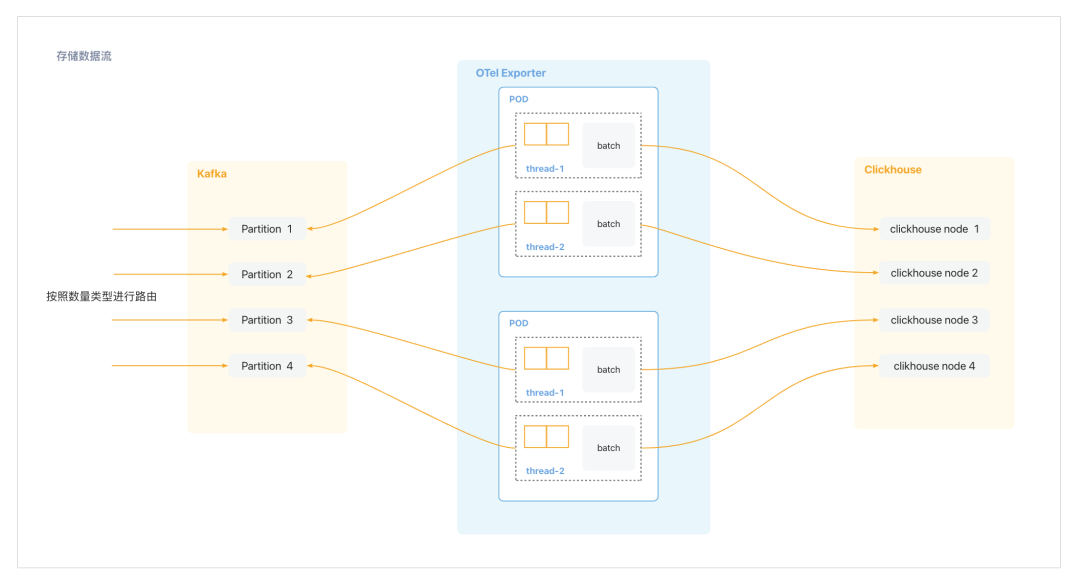
为了充分利用批量写入的优势,数据在流入 Kafka 之前使用预定的路由策略将数据写入相应的 Kafka 分区,从而提高了写入 Kafka 的压缩率。这样做不仅可以减少网络传输的开销,还可以进一步提升存储效率。
同时,存储服务 OTel-Exporter 充分利用内存进行数据的“攒批”操作。他们将一个 POD 专门处理两个 Kafka 分区的数据(实际根据各场景确定),这样每个 POD 可以独占一个线程处理数据,减少了线程之间的上下文切换和竞争。当内存中的数据达到一定阈值时,这部分数据会被刷写到远端的存储 ClickHouse 中。
这种方式与面向列存储引擎 ClickHouse 的低 TPS(每秒事务处理次数)和高吞吐量写入特性非常契合。目前,他们的单机 ClickHouse 每秒可支持超过 90 万行的写入吞吐量,这远远超过了 HBase 和 ES 的写入能力。
这种高效的数据写入与存储策略不仅可以保证数据的快速处理和存储,还能够节约成本并提高整体系统的性能。
六
升级 JDK21
2023 年,公司内部多个系统成功升级至 JDK 17,并且收获了显著的好处。相对于使用 JDK 8,JDK 17 在性能方面表现更高效。它能够利用更少的内存和 CPU 资源,从而提高系统性能并降低运行成本。JDK 17 中包含了许多性能优化的功能,包括改进的 JIT 编译器和垃圾回收器等。这些优化措施明显提高了应用程序的性能。仅仅从 Java 8 升级到 Java 17,即使没有其他改动,性能就直接提升了 10%。这主要得益于对 NIO 底层的重写。在升级过程中,JVM 也伴随着一系列相关的优化措施,进一步提升了系统性能。
同时,JDK 19 推出了虚拟线程(也称为协程),以解决读写操作系统中线程依赖内核线程实现时带来的额外开销问题。最终,我们选择升级到 JDK 21。
以 Trace2.0 后端计算程序为例,其采用的是基础库,比如 Guava、Lombok、Jackson、Netty 和 Maven 进行构建。整个升级流程也相对简单,仅需以下四步:
第一步:指定 JDK 版本
<properties>
<java.version>21</java.version>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
</properties>
第二步:引入 javax.annotation 程序包、升级 lombok
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>jsr250-api</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
</dependency>
第三步:JVM 参数设置
-Xms22g -Xmx22g
#开启ZGC
-XX:+UseZGC
-XX:MaxMetaspaceSize=512m
-XX:+UseStringDeduplication
#GC周期之间的最大间隔(单位秒)
-XX:ZCollectionInterval=120
-XX:ReservedCodeCacheSize=256m
-XX:InitialCodeCacheSize=256m
-XX:ConcGCThreads=2
-XX:ParallelGCThreads=6
#官方的解释是 ZGC 的分配尖峰容忍度,数值越大越早触发GC
-XX:ZAllocationSpikeTolerance=5
-XX:+UnlockDiagnosticVMOptions
#关闭主动GC周期,在主动回收模式下,ZGC 会在系统空闲时自动执行垃圾回收,以减少垃圾回收在应用程序忙碌时所造成的影响。如果未指定此参数(默认情况),ZGC 会在需要时(即堆内存不足以满足分配请求时)执行垃圾回收。
-XX:-ZProactive
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50m
第四步:采用虚拟线程处理计算任务伪代码如下
// 只需要更改ExecutorService的实现类
ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
List<CompletableFuture<Void>> completableFutureList = combinerList.stream()
.map(task -> CompletableFuture.runAsync(() -> {
// xxx 业务逻辑
}, executorService))
.toList();
completableFutureList.stream()
.map(CompletableFuture::join) //用join阻塞获取结果
.toList();
仅需 30 分钟即可完成 JDK 升级,现在让我们一起来看看线上升级后的效果吧。
升级后效果
备注:由于容器限制,同配置的容器升级到 JDK21 后 JVM 堆内存容量比升级前少 20%。
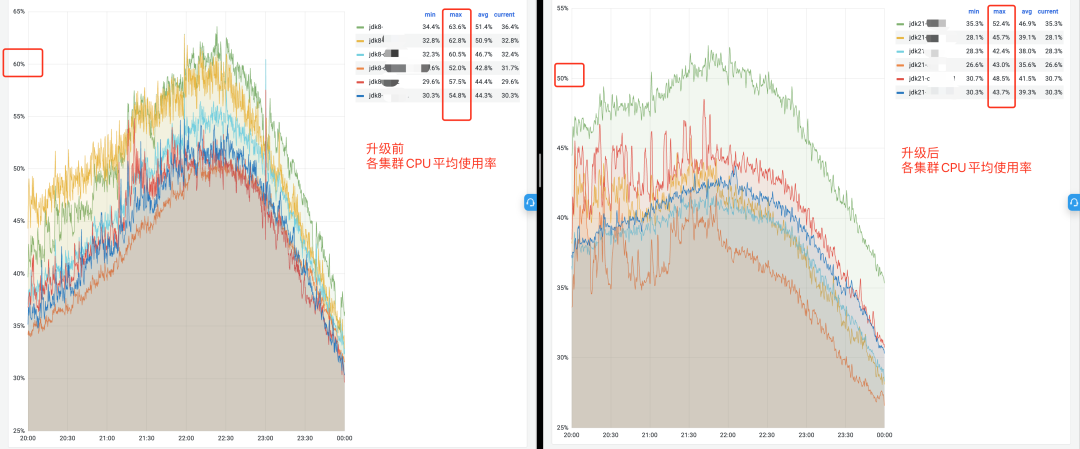
先给出结论:
-
JDK21 配合使用 ZGC 性能提升非常明显,虽然 GC 次数出现翻倍现象但 ZGC 的停顿时间达到微妙级别,吞吐量提高了不少。
-
8c32g 机器使用 ZGC 后,各集群平均 CPU 利用率下降 10+%。
七
结语