
14种轻量级网络综述 — 主干网络篇

极市导读
早期的卷积神经很少考虑参数量和计算量的问题,由此轻量级网络诞生,其旨在保持模型精度基础上近一步减少模型参数量和复杂度。本文对主要的轻量级网络进行了简述,让大家对轻量级网络的发展历程以及种类有更加清晰的了解。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
轻量级网络的核心是在尽量保持精度的前提下,从体积和速度两方面对网络进行轻量化改造,本文对轻量级网络进行简述,主要涉及以下网络:
SqueezeNet系列 ShuffleNet系列 MnasNet MobileNet系列 CondenseNet ESPNet系列 ChannelNets PeleeNet IGC系列 FBNet系列 EfficientNet GhostNet WeightNet MicroNet
SqueezeNet系列
SqueezeNet系列是比较早期且经典的轻量级网络,SqueezeNet使用Fire模块进行参数压缩,而SqueezeNext则在此基础上加入分离卷积进行改进。虽然SqueezeNet系列不如MobieNet使用广泛,但其架构思想和实验结论还是可以值得借鉴的。
SqueezeNet
SqueezeNet是早期开始关注轻量化网络的研究之一,使用Fire模块进行参数压缩。
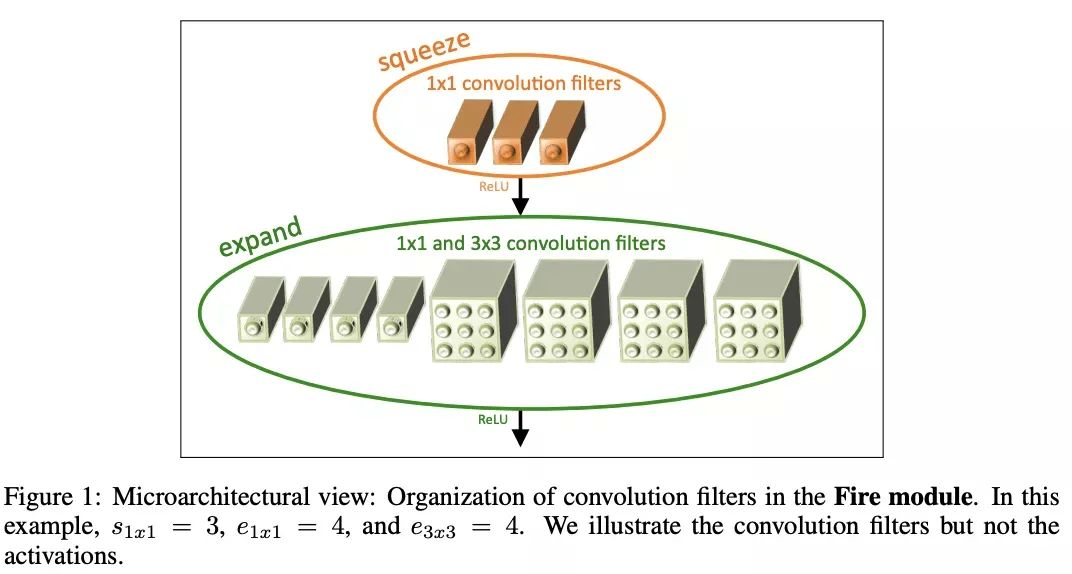
SqueezeNext
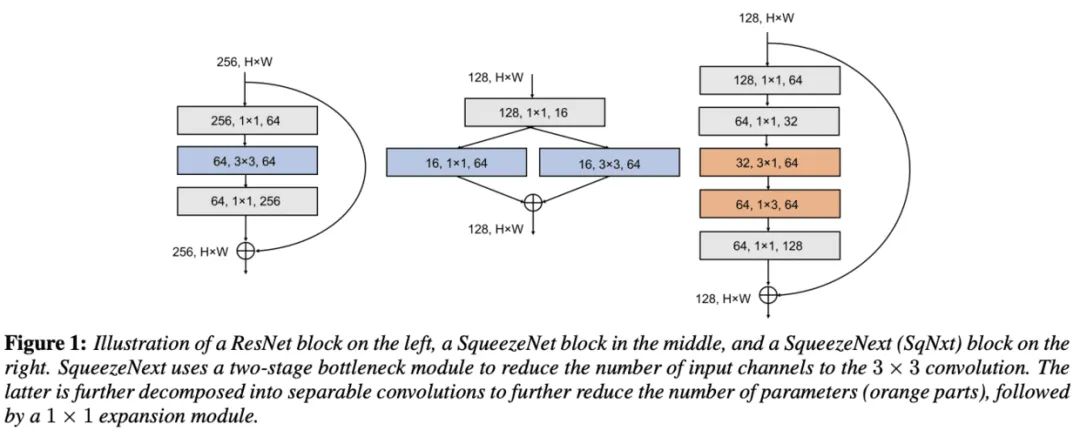
Low Rank Filters 低秩分解的核心思想就是将大矩阵分解成多个小矩阵,这里使用CP分解(Canonical Polyadic Decomposition), 将 卷积分解成 和 的分离卷积, 参数量能从 降为 。 Bottleneck Module 参数量与输入输出维度有关,虽然可以使用深度分离卷积来减少计算量,但是深度分离卷积在终端系统的计算并不高效。因此采用SqueezeNet的squeeze层进行输入维度的压缩,每个block的开头使用连续两个squeeze层,每层降低1/2维度。 Fully Connected Layers 在AlexNet中,全连接层的参数占总模型的96%,SqueezeNext使用bottleneck层来降低全连接层的输入维度,从而降低网络参数量。
ShuffleNet系列
ShuffleNet V1
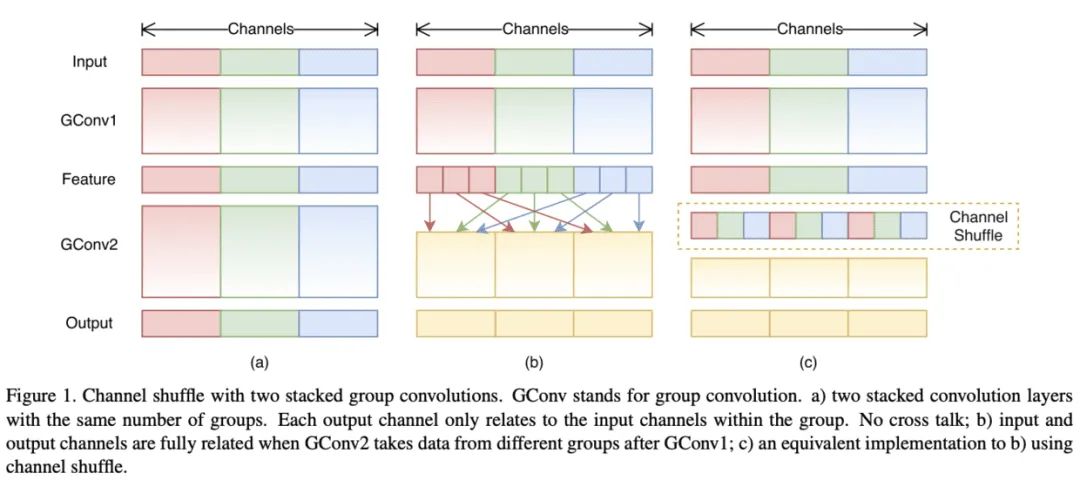
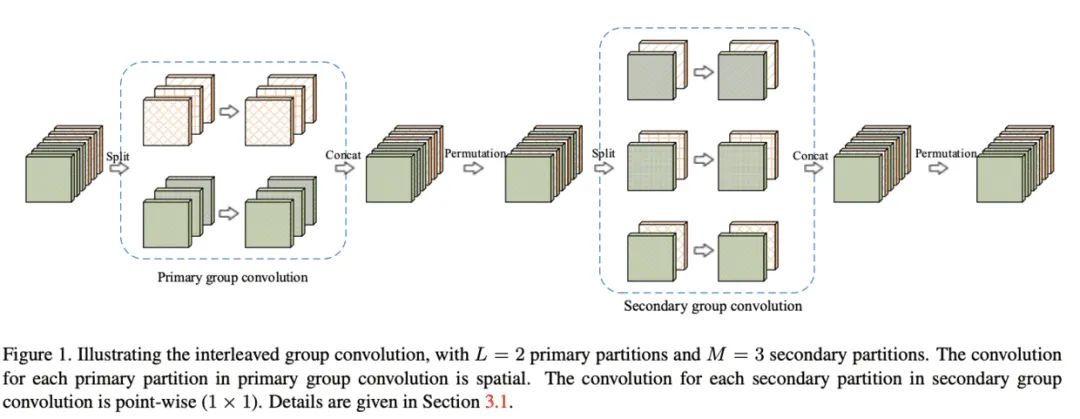
图1a是最直接的方法,将所有的操作进行了绝对的维度隔离,但这会导致特定的输出仅关联了很小一部分的输入,阻隔了组间的信息流,降低了表达能力。 图1b对输出的维度进行重新分配,首先将每个组的输出分成多个子组,然后将每个子组输入到不同的组中,能够很好地保留组间的信息流。
ShuffleNet V2
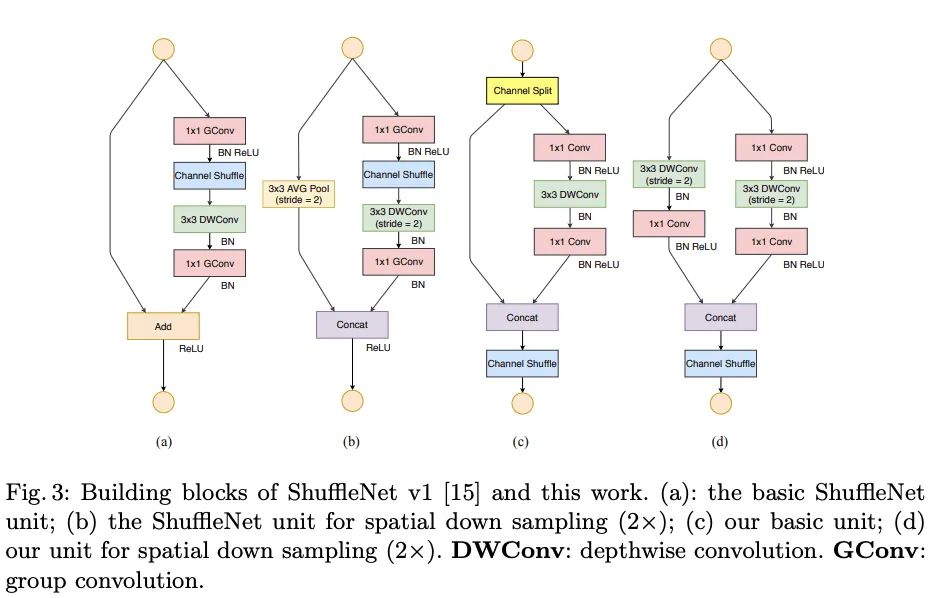
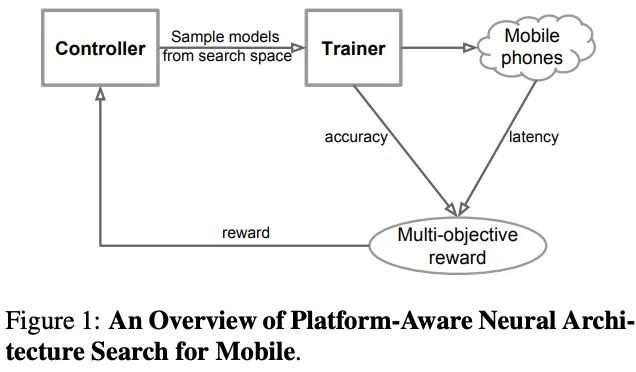
MnasNet
MobileNet系列
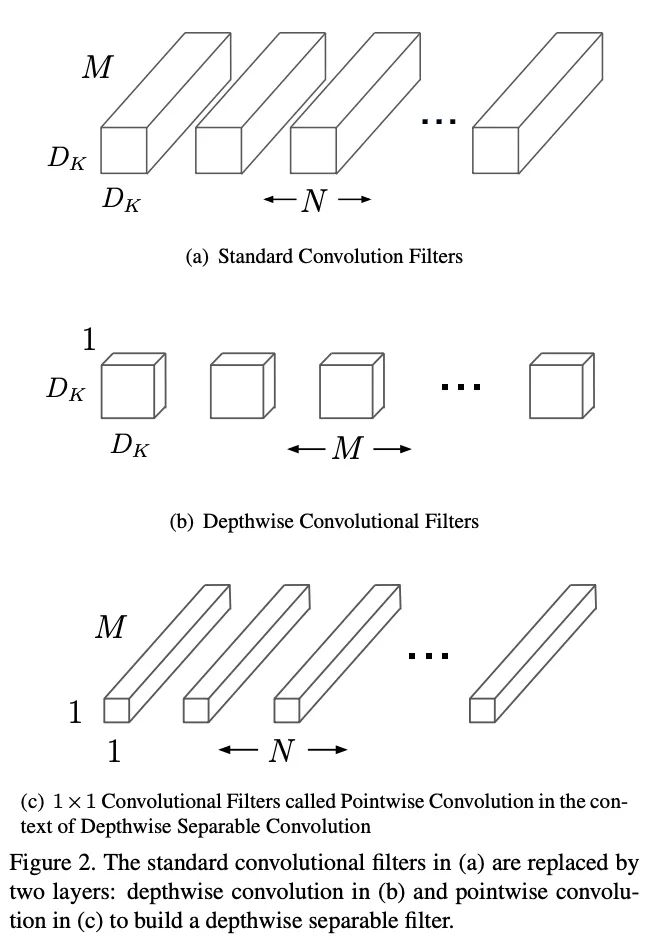
MobileNetV1
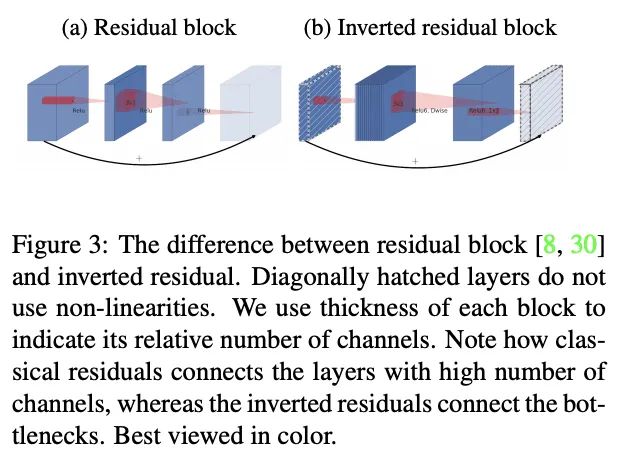
MobileNetV2
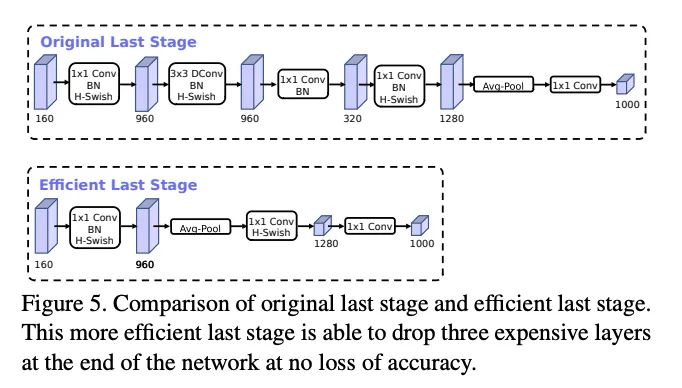
MobileNetV3
CondenseNet
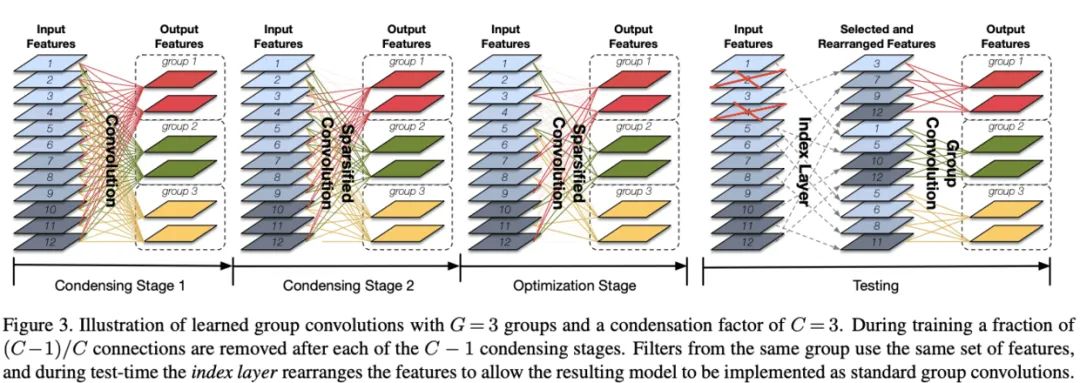
ESPNet系列
ESPNet
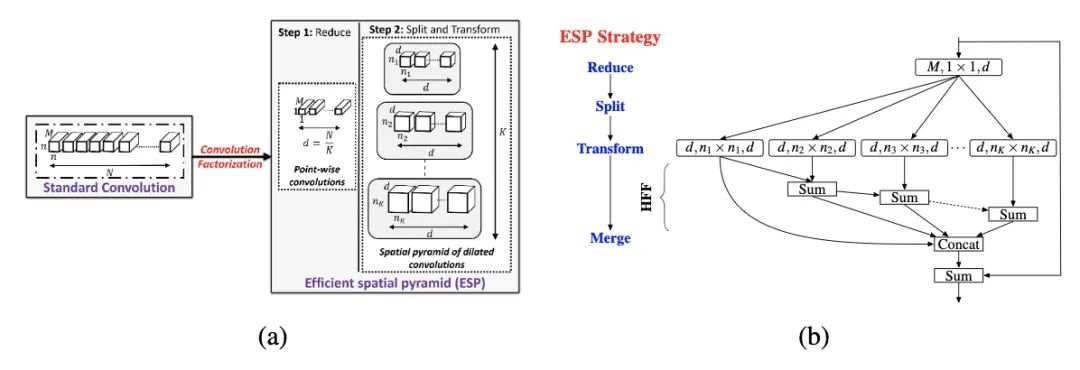
ESPNetV2

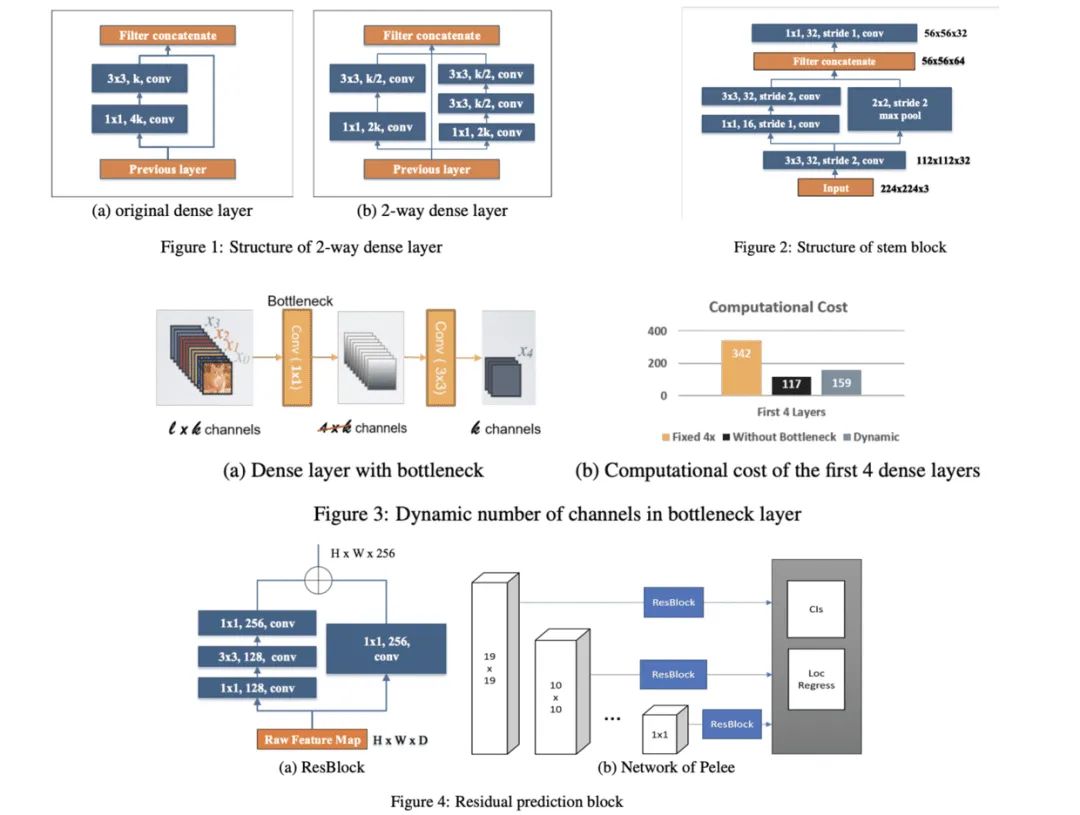
ChannelNets

PeleeNet
IGC系列
IGCV1
IGCV2

IGCV3

FBNet系列
FBNet
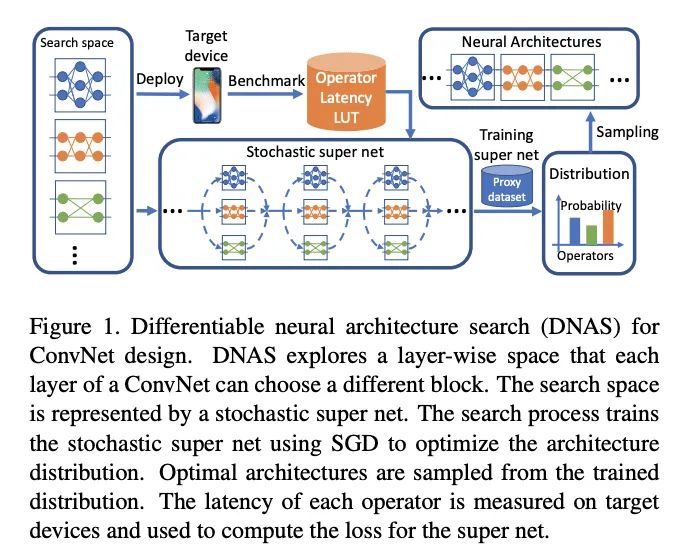
FBNetV2

FBNetV3

EfficientNet

GhostNet

训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,相似的特征图类似于对方的ghost。但冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,于是提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图数量,Ghost模块的整体的参数量和计算量就已经降低了。
WeightNet

论文提出了一种简单且高效的动态生成网络WeightNet,该结构在权值空间上集成了SENet和CondConv的特点,在激活向量后面添加一层分组全连接,直接产生卷积核的权值,在计算上十分高效,并且可通过超参数的设置来进行准确率和速度上的trade-off。
MicroNet
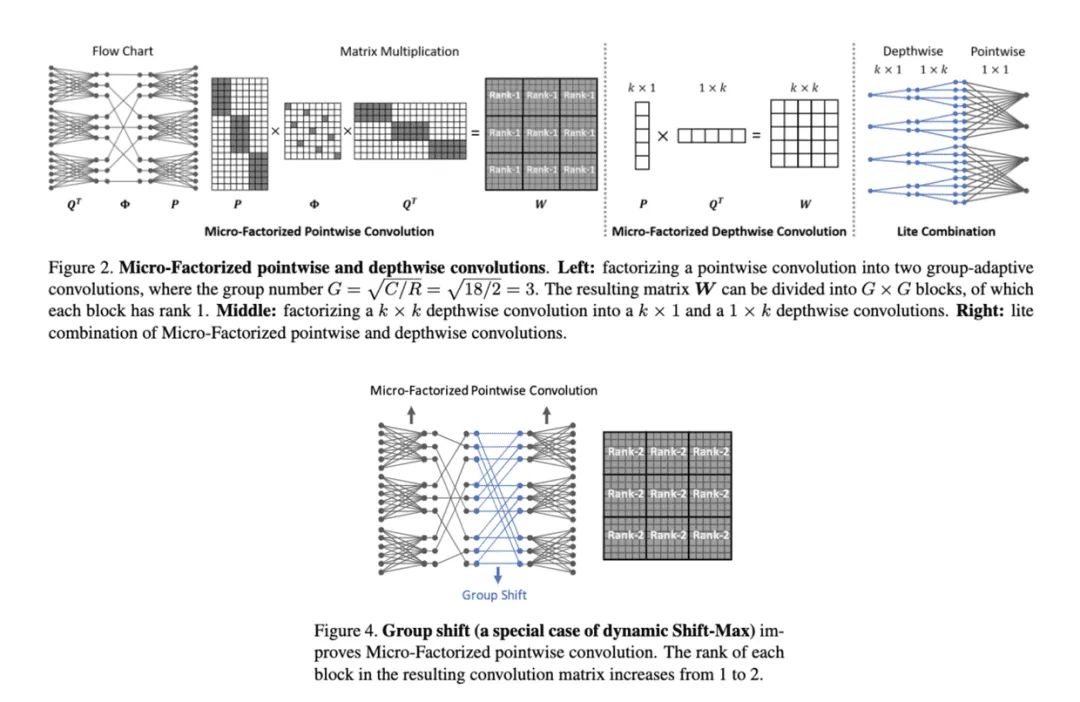
论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“ICCV2021”获取最新论文合集~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
