
终于有人把降维讲明白了

导读:本文为大家介绍了降维的概念及降维技术主成分分析(PCA)在特征工程中的应用。

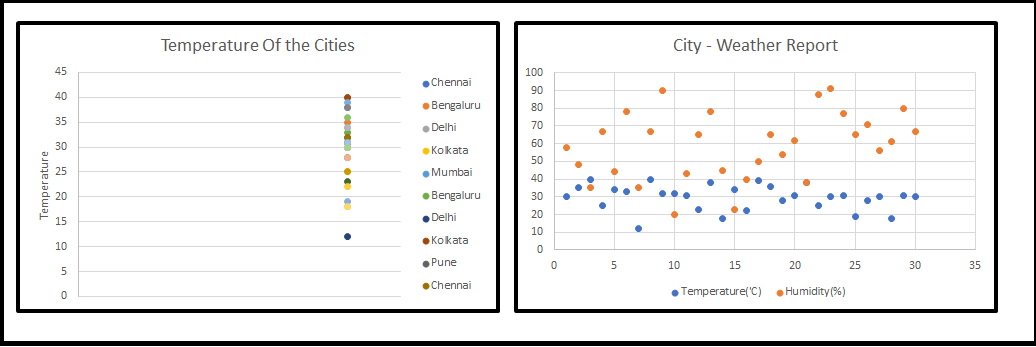
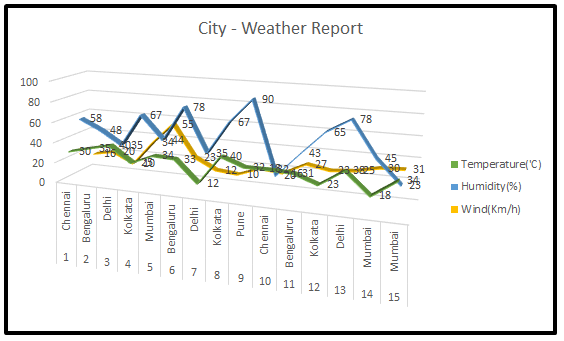
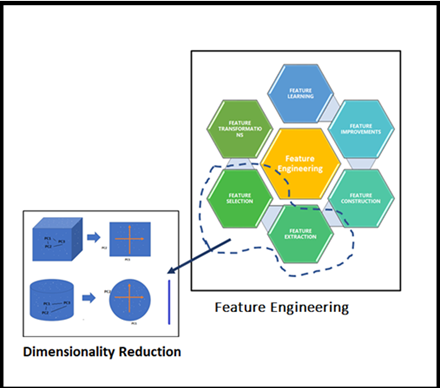
Sr. DS继续他的讲座,所有这些示例图片都是显著的特征,我们可以在实时场景中使用它们,许多机器学习问题涉及数以千计的特征,所以我们最终训练这些模型的速度会变得非常慢,以至于不能很好地解决业务问题,并且这时候我们不能冻结模型,这种情况就是所谓的“维度灾难”引起的。然后,我们开始思考一个问题,我们应该如何处理这个“维度灾难”问题。

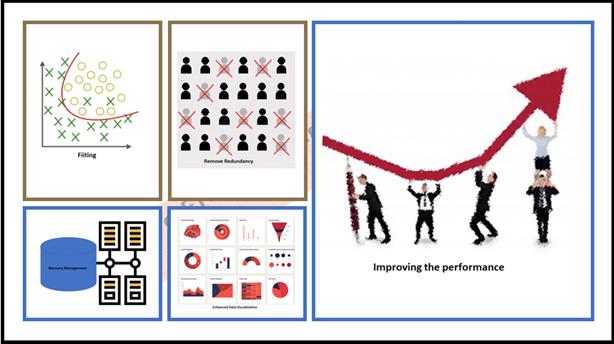
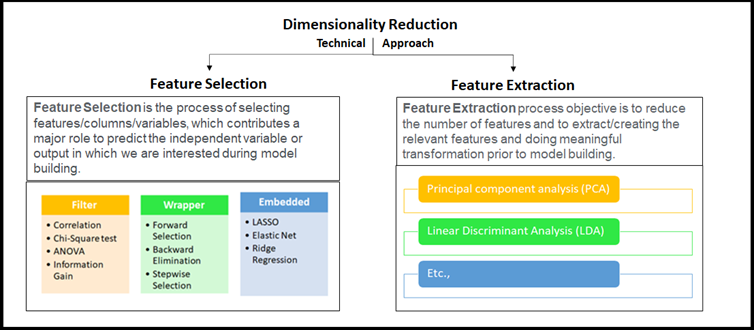
它有助于消除冗余的特征和噪声误差因素,最终增强给定数据集的可视化。 由于降低了维度,可以表现出优秀的内存管理。 通过从数据集中删除不必要的特征列表来选择正确的特征,从而提高模型的性能。 当然,更少的维度(强制性的维度列表)需要更少的计算效率,更快地训练模型,提高模型的准确性。 大大降低了整个模型及其性能的复杂性和过拟合。

# Import all the necessary packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn import metrics
%matplotlib inline
import matplotlib.pyplot as plt
%matplotlib inline
wq_dataset = pd.read_csv('winequality.csv')wq_dataset.head(5) 
wq_dataset.describe() 
wq_dataset.isnull().any()

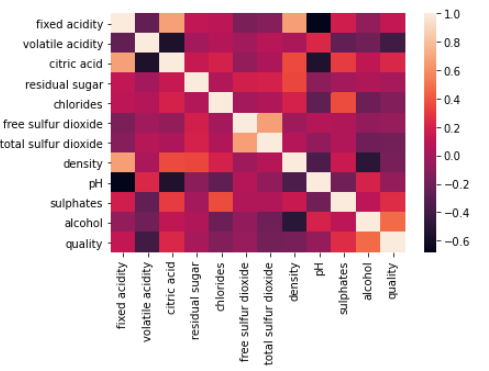
correlations = wq_dataset.corr()['quality'].drop('quality')
print(correlations)

sns.heatmap(wq_dataset.corr())
plt.show()
x = wq_dataset[features]
y = wq_dataset['quality']
[‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘alcohol’]x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=3)print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)
Traning data shape: (1199, 8)
Testing data shape: (400, 8)from sklearn.decomposition import PCA
pca_wins = PCA(n_components=2)
principalComponents_wins = pca_wins.fit_transform(x)命名为第1主成分,第2主成分。
pcs_wins_df = pd.DataFrame(data = principalComponents_wins, columns = ['principal component 1', 'principal component 2'])pcs_wins_df.head() 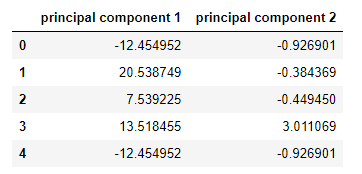
print('Explained variation per principal component: {}'.format(pca_wins.explained_variance_ratio_))
Explained variation per principal component: [0.99615166 0.00278501]逻辑回归 随机森林 KNN 朴素贝叶斯


直播主题:企业数据价值现状及数据分析师的价值提升
直播时间:4月24日19:00-20:00
主讲人:宋天龙,大数据技术专家,触脉咨询合伙人兼副总裁,擅长数据挖掘、建模、分析与运营,《Python数据分析与数据化运营》作者。
直播介绍:
数据在企业中的真实定位
是什么导致了数据价值没有产生理想效果
数据分析师改善客观因素的6种途径
数据分析师改善主观因素的6个要素
数据分析师如何有效管理“有效建议”
评论