
爬虫案例:26行代码完成某表情包网站爬取
零基础学习zhenguo老师python课程到今天刚好有一个月时间了,时间过得真快,以前知道简单知道变量,列表但是解决不了需求。刚好这两天有朋友让我爬取表情包网站,我就自己整理思路。这样不仅仅可以学以致用,还能检验自己的学习成果。顺便投稿zhenguo老师还能挣一个饭钱50元钱。
开发思路介绍
1.连接网站,返回页面的html结果。
2.用到lxml的etree方法下的解析获取的网页。提取想要的内容
3.提取得到title和表情包图片的下载地址并保存到变量list中。
4.拼接字符串,将图片的名字进行重新命名并保存到本地。
核心问题分析
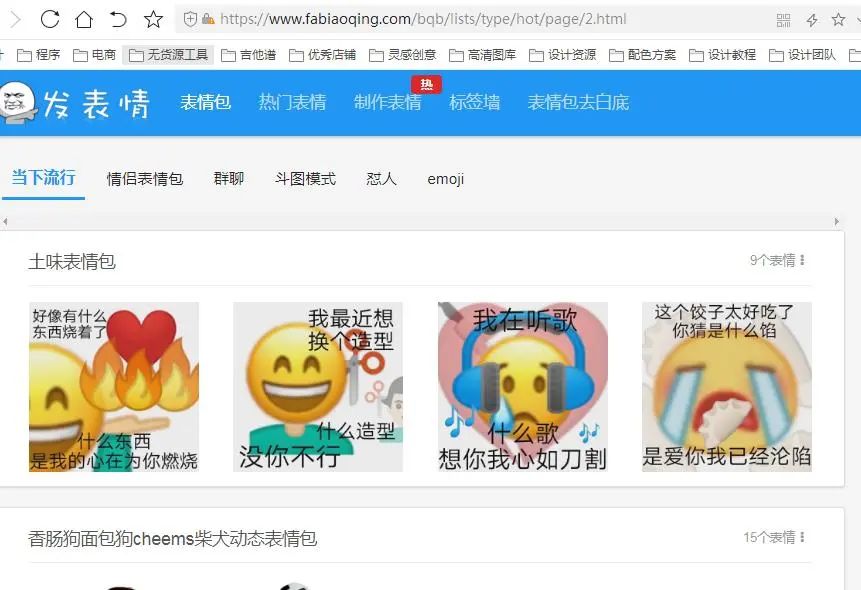
分析网页代码,我们可以看到最后的数字2对应分页,如2表示第二页。同理3表示第三页。以此类推。所以我们可以将2用变量表示。依次遍历就可以爬取对应的页面。
page_n = int(input('请输入你需要爬取的网页数量'))
for i in range(page_n):
url_bqb =f'https://www.fabiaoqing.com/bqb/lists/type/hot/page/{i}.html'
#用request模块获取得到url
response = requests.get(url_bqb)
#用到了lxml中的HTMLParser()解析器调整解析html结构自动补全语法错误
html_parser = lxml.etree.HTMLParser()
#获取html为分析html做准备
html = lxml.etree.fromstring(response.text,parser = html_parser)
#得到标题和图片并打印
bqb_title = html.xpath("//div[@class ='bqppdiv']/p/text()")
bqb_pic = html.xpath("//div[@class ='bqppdiv']/img/@data-original")
print(bqb_pic)
print(bqb_title)
结果如下: 因为我们最终保存到桌面,我们需要一个文件来保存我们的图片。所以用到python的内置模块os
因为我们最终保存到桌面,我们需要一个文件来保存我们的图片。所以用到python的内置模块os
if not os.path.exists('bqb_pic'):
os.mkdir('bqb_pic')
结果如下:
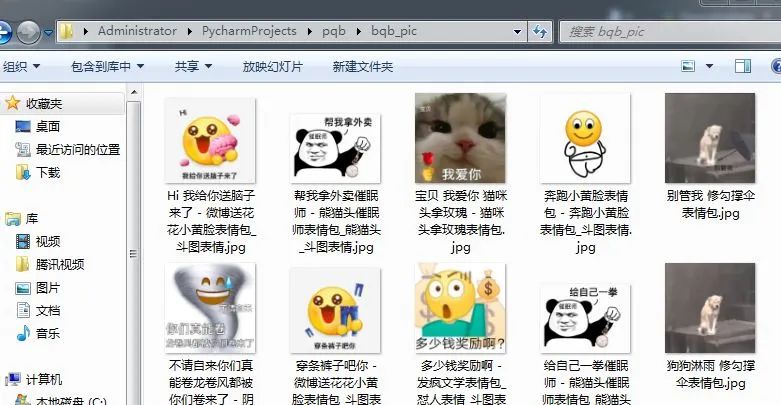 这里就是说如果不存在bqb_pic文件夹,那么我们就新建一个bqb_pic文件夹。用于保存我们的图片。
这里就是说如果不存在bqb_pic文件夹,那么我们就新建一个bqb_pic文件夹。用于保存我们的图片。
核心注意点
这里需要注意的是我们的文件命名的时候,如?、/等这些字符是不能去命名文件的名称的,我们需要将这些字符去掉,我们需要将这些字符进行清洗。
title = title.replace("/","-").replace(":","").replace("?","")
最终的代码展示如下
import random
import time
from bs4 import BeautifulSoup
import requests
import lxml.etree
import os
page_n = int(input('请输入你需要爬取的网页数量'))
for i in range(page_n):
url_bqb =f'https://www.fabiaoqing.com/bqb/lists/type/hot/page/{i}.html'
response = requests.get(url_bqb)
html_parser = lxml.etree.HTMLParser()
html = lxml.etree.fromstring(response.text,parser = html_parser)
#将返回的字符串类型返回html进行解析
bqb_title = html.xpath("//div[@class ='bqppdiv']/p/text()")
bqb_pic = html.xpath("//div[@class ='bqppdiv']/img/@data-original")
print(bqb_pic)
print(bqb_title)
if not os.path.exists('bqb_pic'):
os.mkdir('bqb_pic')
for title,pic in zip(bqb_title,bqb_pic):
title = title.replace("/","-").replace(":","").replace("?","")
pic_stream = requests.get(pic,stream=True)
with open(os.path.join('bqb_pic',title + '.jpg'),'wb+') as writer:
writer.write(pic_stream.raw.read())
print(f'info{title}.jpg下载成功')
time.sleep(random.uniform(0.1,0.4))
取得的的表情包效果如下: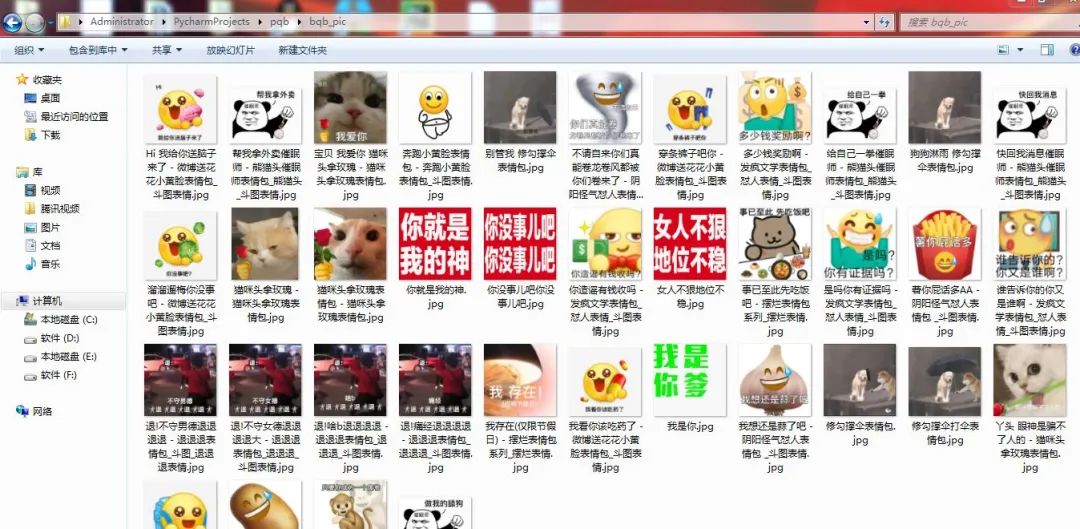 是不是很简单和简洁,最终也只是用到了26行代码
是不是很简单和简洁,最终也只是用到了26行代码
学习python以后发现有时候,编程也没有想象中的那么复制。让我们这种零基础的小伙伴快速入门python并且完成自己的需求。也是要感谢zhenguo老师的。通过这次的实践我也对request模块和xpath方法访问html的文本和标签的属性有了更加深入的认识。
今天的投稿费用50元有着落了,想想一个多月的不放弃。赶紧买点东西犒劳下自己。
评论