
万人连麦的幕后技术详解
#01
01
直连
直连,也叫对等网络(P2P)。这种结构中,每个客户端在启动的时候,都需要注册到注册服务器,便于其他人能找到自己,正常情况下,在建立音视频通讯的时候不需要媒体服务器的介入,每个客户端相互连接,直接进行音视频通讯。但当一个或多个客户端在 NAT 之后(甚至多层NAT之后)时,直连会变得比较困难,有时候甚至无法联通。这个时候需要通过 STUN 进行“打洞”来穿越 NAT 进行通讯,如果“打洞”失败,还需要引入服务器中继才能通讯。具体的NAT打洞,或服务中继的细节可以参考拍乐云的系列文章《穿越防火墙的奥秘:ICE协议详解》。
02
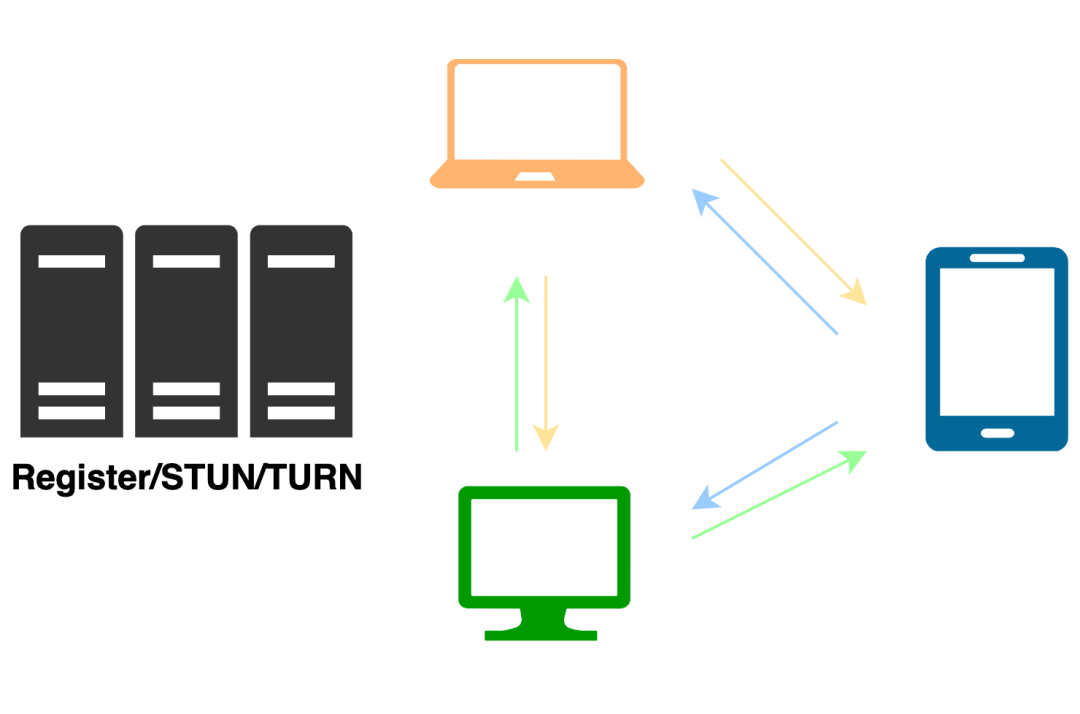
MCU
MCU(Multipoint Conferencing Unit)方案出现得比较早,相应的技术也非常成熟,该方案由一个服务器和多个客户端组成一个星形结构,各个端都将音视频数据发送给服务端,服务端会把所有客户端的音视频数据经过解码,同步,重采样,布局,混流,编码等,最后把媒体数据推送给所有的客户端。实际上服务器端就是一个音视频混合器,这种方案服务器的计算压力会非常大。一般情况下,在音频数据混流之前,服务端会把目标用户自己的音频数据移除,避免客户端听到自己的回声。在视频数据混流前,服务端可能检测每个目标用户是否有自定义的布局,否则就按系统默认的布局混流编码。在一些网络比较复杂的环境下,MCU 也可以按目标用户的带宽对视频数据的编码码率做一些自适应的调整。
03
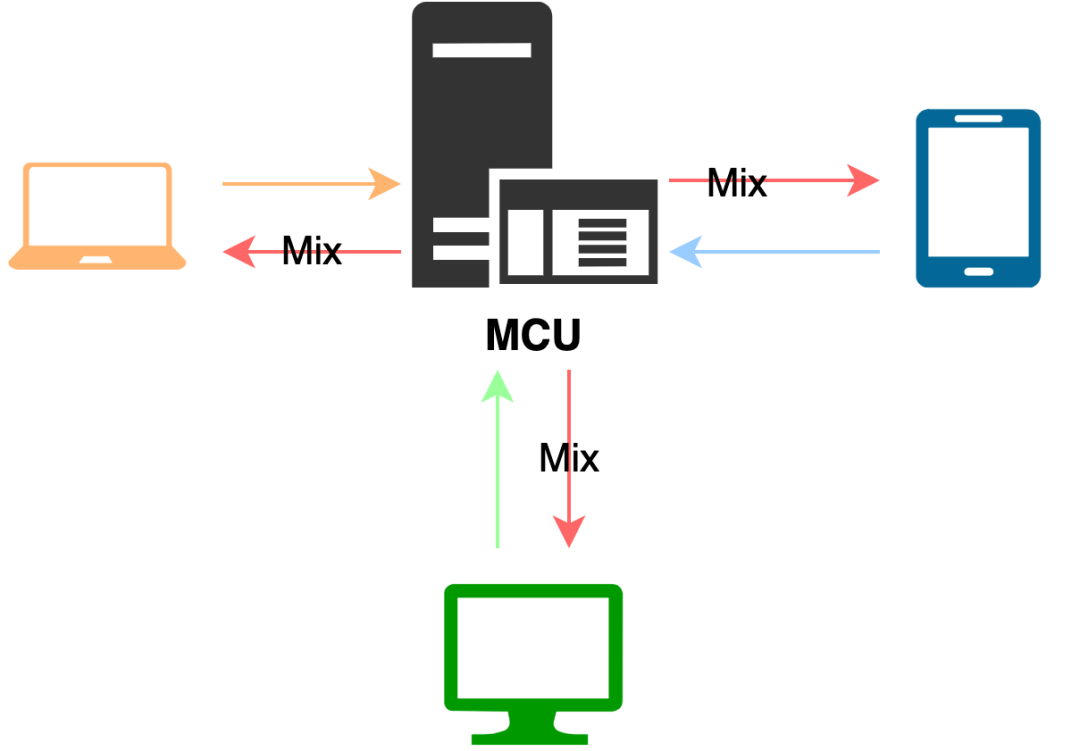
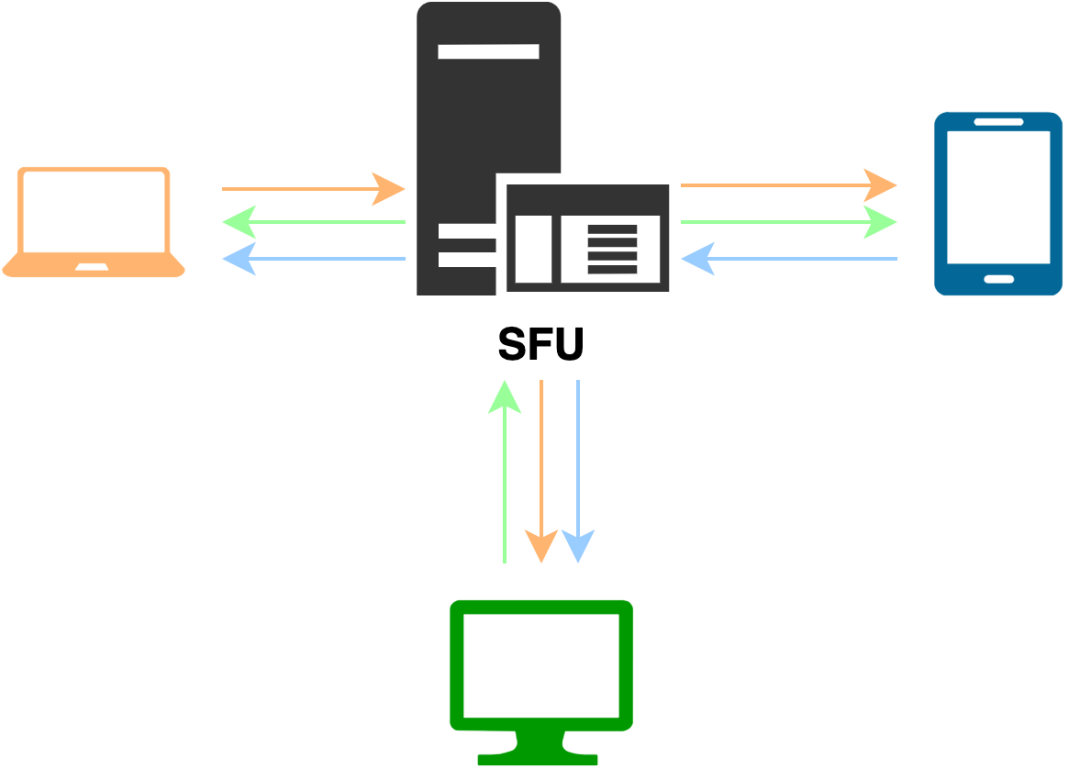
SFU
SFU(Selective Forwarding Unit)是最近几年流行的新架构,SFU 的方案跟 MCU 类似,每个客户端都把音视频数据发给服务端,然后由服务端转发给不同的客户端。跟 MCU 不同的地方,SFU 不对音视频进行混流,收到某个客户端的音视频数据后,按需(目标客户端是否订阅)将音视频数据原封不动的转发给目标客户端。它实际上就是一个音视频路由转发器。在这种方案里,所有的混流都是在客户端做的,对服务端的计算要求大大降低。在一些复杂的网络环境,视频的数据源端会使用 Simulcast 或 SVC 发送多层不同分辨率的视频流数据,服务端根据目标客户端的不同网络带宽和网络状况转发最合适的分辨率给目标客户端,使每个客户端的体验达到最佳。
04
对比和总结
从上面的对比,我们可以看到,直连方案基本不大适合大会场景,而且无法对网络内容进行审核,直连方案目前市场上基本只有在免费场景中看到。而随着计算成本和带宽成本的大幅度下降,及超大并发的需求,SFU方案的优势变得非常明显,而MCU方案在一些企业内基于音视频终端的通讯等传统应用场景目前还是比较常见的。
#02
01
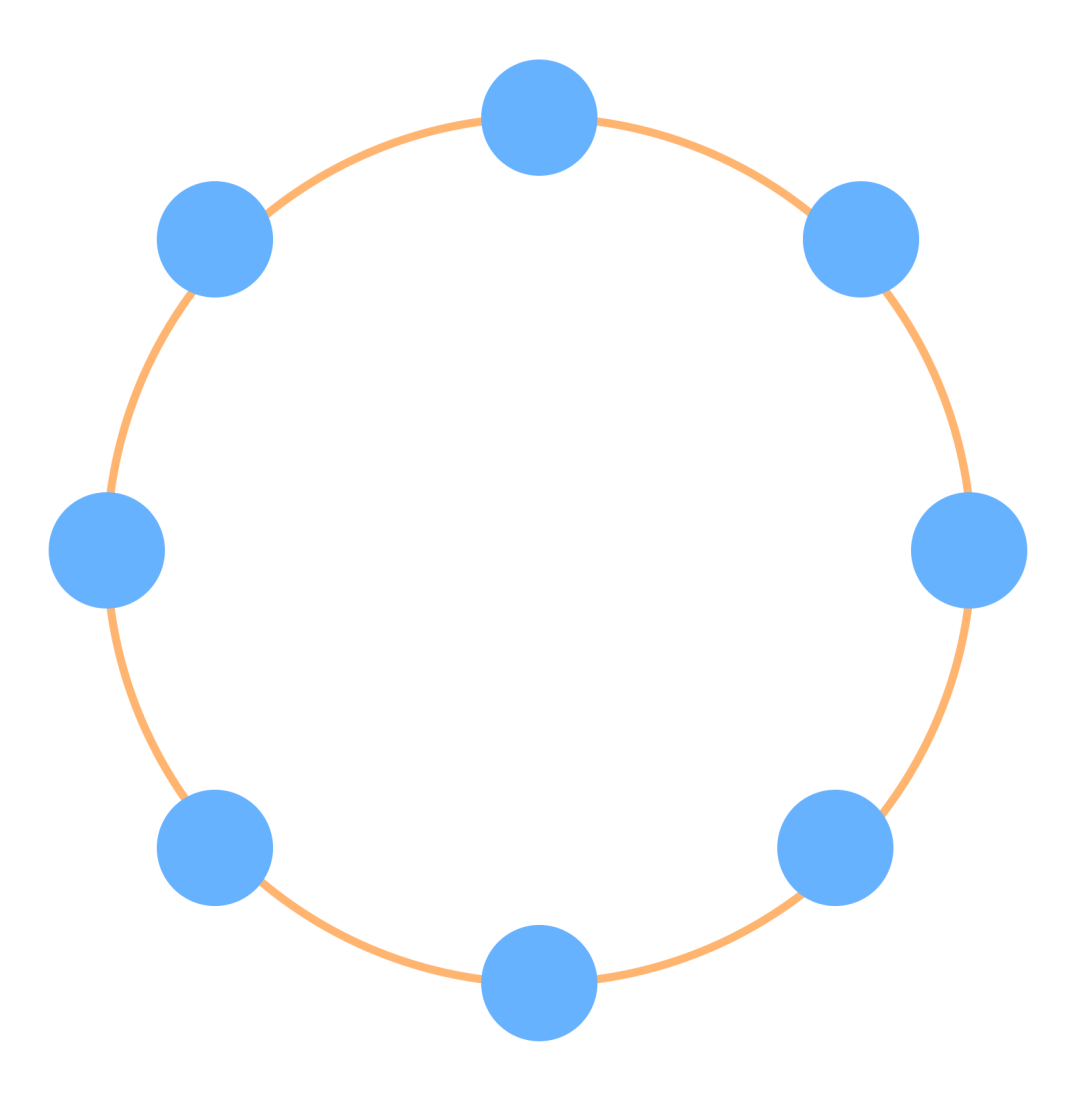
环状网络结构
环型结构由网络中若干节点通过点到点的链路首尾相连形成一个闭合的环,这种结构通过公共传输链路组成环型连接,数据在环路中沿着一个方向在各个节点间传输,信息从一个节点传到另一个节点。
02
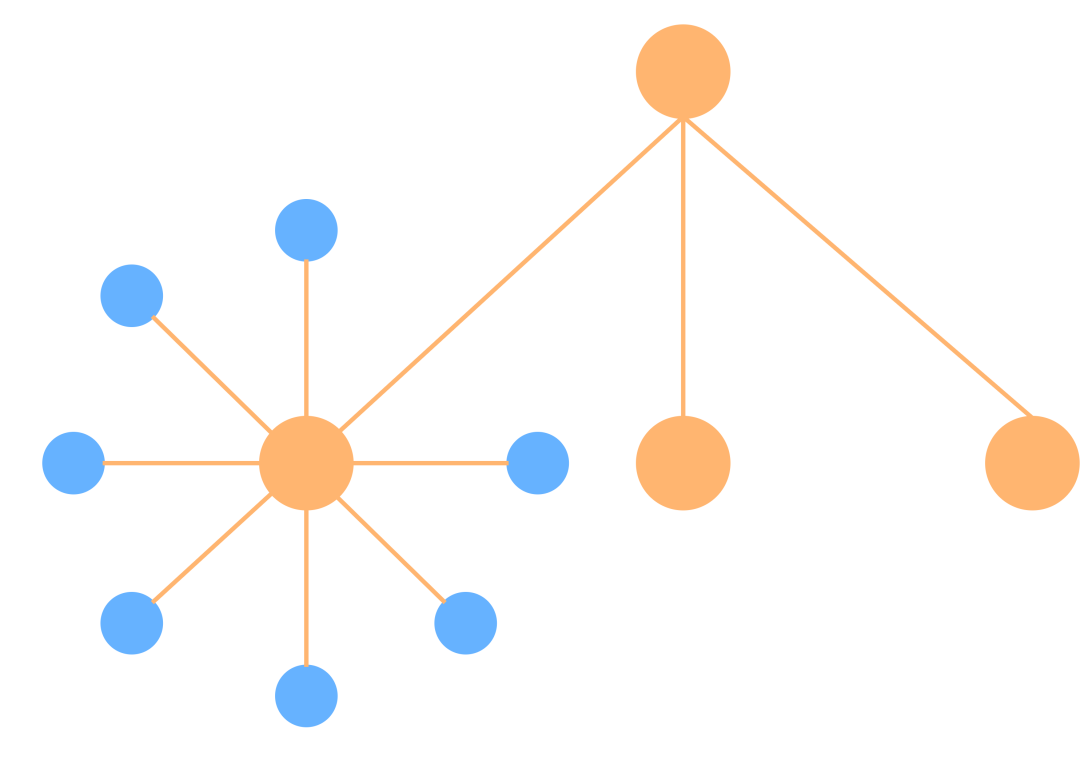
星型/树型网络结构
星型拓扑结构是一个中心,多个分节点。它结构简单,连接方便,管理和维护都相对容易,而且扩展性强,网络延迟小。中心节点是瓶颈,一旦失效,整个网络就瘫痪,单叶子结点互相独立,互不影响。
03
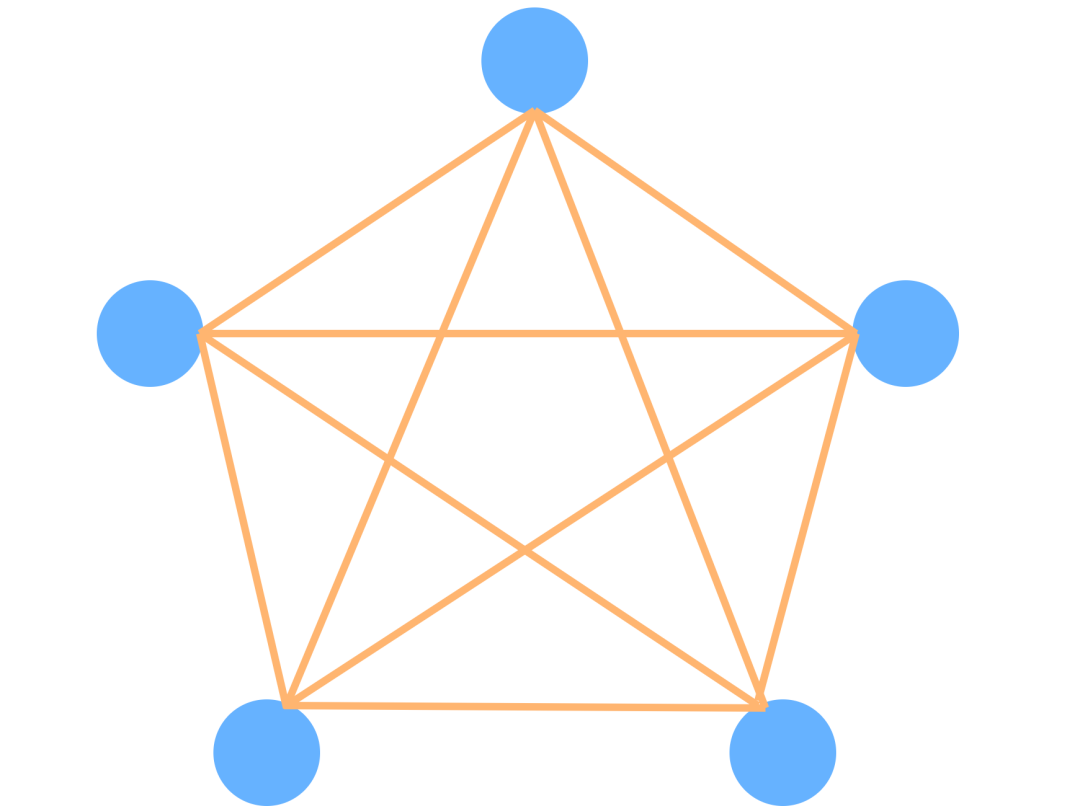
网状网络结构
在网状拓扑结构中,网络的每台设备之间均有点到点的链路连接,网状拓扑结构是应用最广泛的。它的优点是没有中心节点,可靠性高,容错能力强,延迟低,但结构复杂,因有多条传输路径,选路和流量控制比较复杂,消息的时序一致性无法保证。
在音视频服务架构中,我们的设计目标是:极低的延迟,传输高效,吞吐量大,但对不同用户来的媒体数据的时序性一致性并没有要求。因此网状结构一般是音视频服务架构中主DC服务控制节点间组网的首选拓扑结构。
#03
01
网络接入的多样性
移动网络:3G/4G/5G的接入带宽各不相同(3G:<2Mbps;4G:10~ 100Mbps;5G:~10Gbps),并且信号强弱,接入基站随移动变化。
无线接入:主流路由器 < 150Mbps (2.4G频段最大300Mbps,5G频段最大867Mbps)。
02
传输路径上设备的多样性
03
终端设备的多样性
04
服务端接入的多样性
BGP(Border Gateway Protocol)机房实现单IP多线接入,具备智能路由选择,线路备份,故障后自动切换到可用线路等。多运营商专线接入,需要从应用层处理选路,故障时线路切换等。单运营商专线接入,无法解决不同运营商之间的互联互通的问题。
#04
架构演进和拍乐云实践
01
服务的高并发,高可用
要做到服务高并发,高可用,主要涉及到下面几项技术:
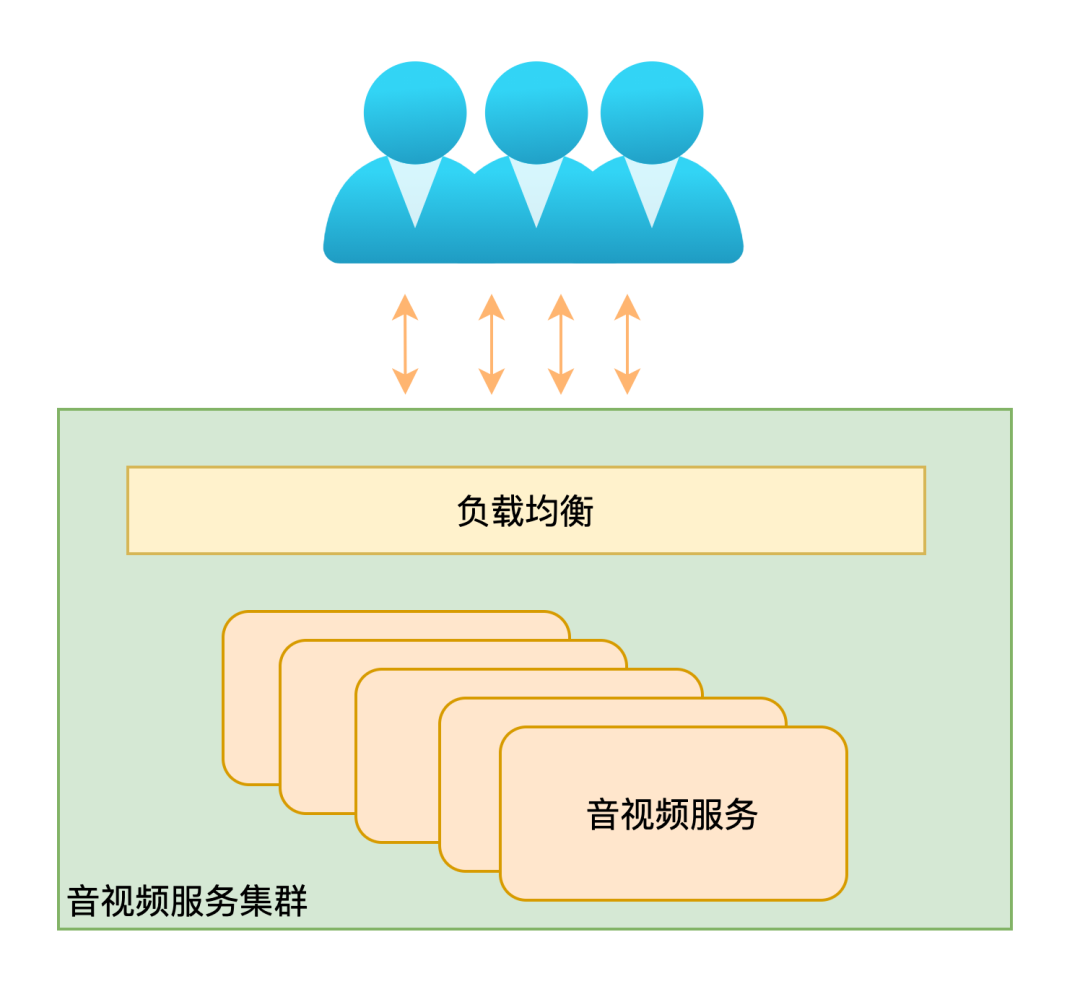
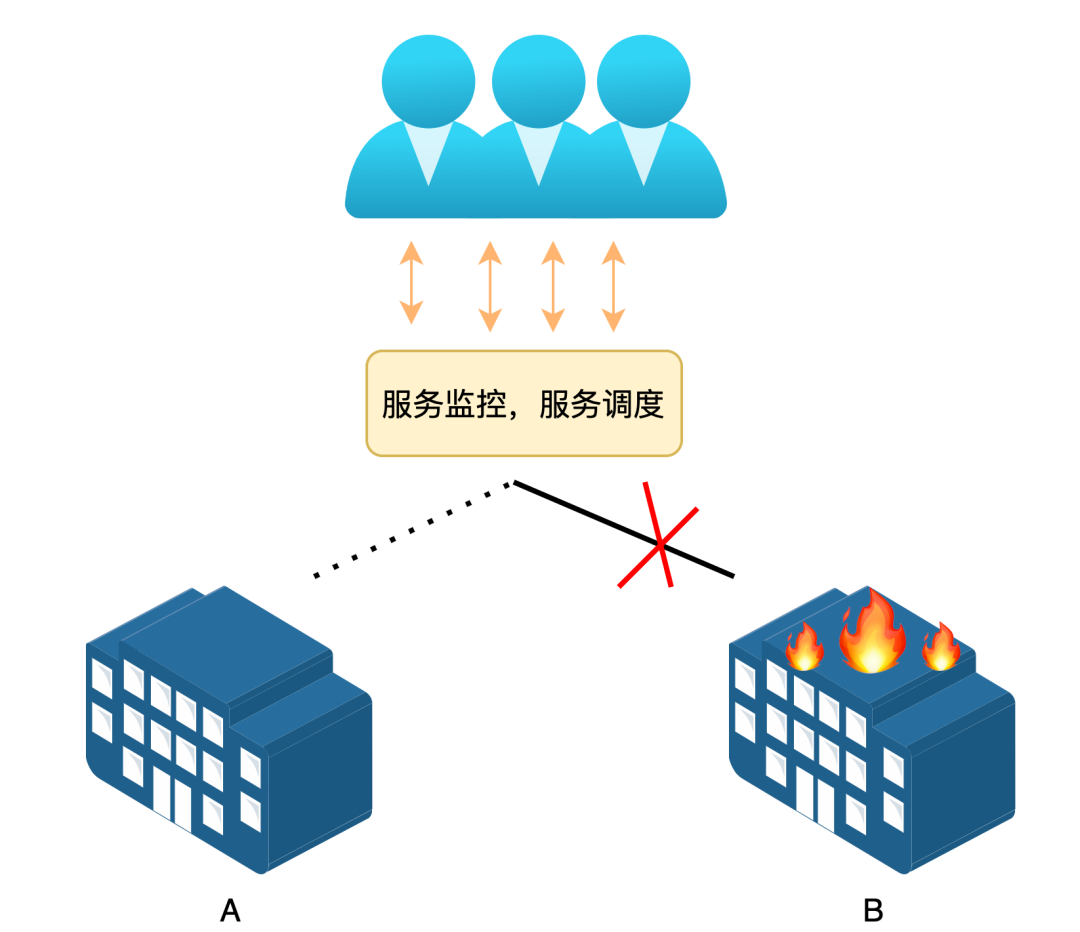
在以上几个主要技术的加持下,拍乐云目前已经可以做到99.95%的高可用,并服务于全球用户。
02
服务的高质量
03
超大规模,超高并发
SFU架构中的有选择的数据转发
在单向直播的场景中,我们也可以通过第三方CDN网络来扩展会议规模,但这种方案的延迟会比较大,会达到3~10秒的延迟,基本无法互动沟通,只能单向直播,当需要互动沟通的时候,必须切换接入方式到边缘计算节点或中心DC。
04
拍乐云音视频系统技术架构
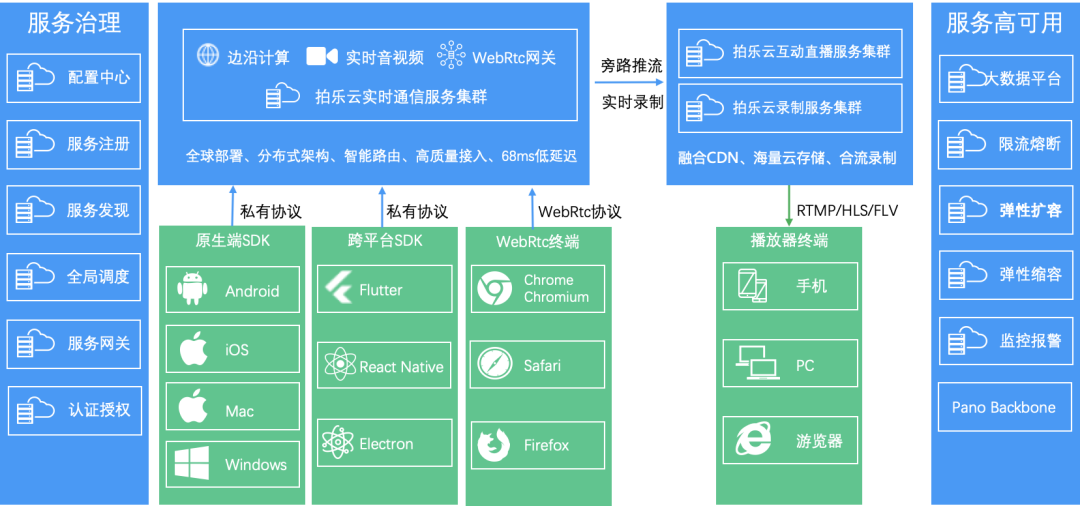
#05
业界动向与最新技术
近年来,音视频通讯领域的发展非常快,出现了各种前沿新兴的技术,有的已经落地,有的还在深入的研究之中,很多技术的应用前景都非常看好。在这里我们举几个例子:
01
WebRTC
2010年5月,Google收购Global IP Solutions的GIPS引擎,将其开源并改名为WebRTC。2014年7月,WebRTC成为W3C标准,并发布浏览器标准API1.0。自此以后,实时音视频通讯服务的门槛大幅度降低,很多基于WebRTC的实时音视频服务如雨后春笋般蓬勃发展起来。可以说WebRTC的出现改变了音视频通讯领域的市场格局。
https://webrtcweekly.com/
02
SDN
Software Defined Network即软件定义网络,最初是由美国斯坦福大学CLean State研究组提出的一种新型网络创新架构,可通过软件编程的形式定义和控制网络,其控制平面和转发平面分离及开放性可编程的特点,被认为是网络领域的一场革命,为新型互联网体系结构研究提供了新的实验途径,也极大地推动了下一代互联网的发展。
其核心概念是:控制与转发分离,管理与控制分离。其可编程和虚拟化特点可以帮助快速定义网络,并实现自动化部署和运维。控制和管理的集中,使得网络路径最优化变得更加容易实现。
03
基于机器学习的新算法
机器学习在很多领域都得到了广泛的应用,在实时音视频通讯领域上也出现了很多应用方向,比如:
语音相关的:语音识别,语音增强等。
04
虚拟现实、增强现实和3D技术
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
私信领取相关资料
推荐阅读:
觉得不错,点个在看呗~
