
详解数据存储的 6 种可选技术

导读:业务问题的范围太广、太深、太复杂,一种工具无法解决所有问题,在大数据和分析领域尤其如此。

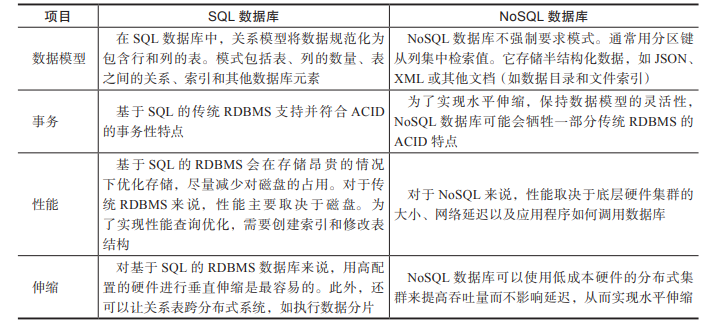
原子性:事务将从头到尾完全执行,一旦出现错误,整个事务将会回滚。 一致性:一旦事务完成,所有的数据都要提交到数据库中。 隔离性:要求多个事务能在隔离的情况下同时运行,互不干扰。 持久性:在任何中断(如网络或电源故障)的情况下,事务应该能够恢复到最后已知的状态。

列式数据库:Apache Cassandra和Apache HBase是流行的列式数据库。列式数据存储有助于在查询数据时扫描某一列,而不是扫描整行。如果物品表有10列100万行,而你想查询库存中某一物品的数量,那么列式数据库只会将查询应用于物品数量列,不需要扫描整个表。 文档数据库:最流行的文档数据库有MongoDB、Couchbase、MarkLogic、Dynamo DB和Cassandra。可以使用文档数据库来存储JSON和XML格式的半结构化数据。 图数据库:流行的图数据库包括Amazon Neptune、JanusGraph、TinkerPop、Neo4j、OrientDB、GraphDB和Spark上的GraphX。图数据库存储顶点和顶点之间的链接(称为边)。图可以建立在关系型和非关系型数据库上。 内存式键值存储:最流行的内存式键值存储是Redis和Memcached。它们将数据存储在内存中,用于数据读取频率高的场景。应用程序的查询首先会转到内存数据库,如果数据在缓存中可用,则不会冲击主数据库。内存数据库很适合存储用户会话信息,这些数据会导致复杂的查询和频繁的请求数据,如用户资料。

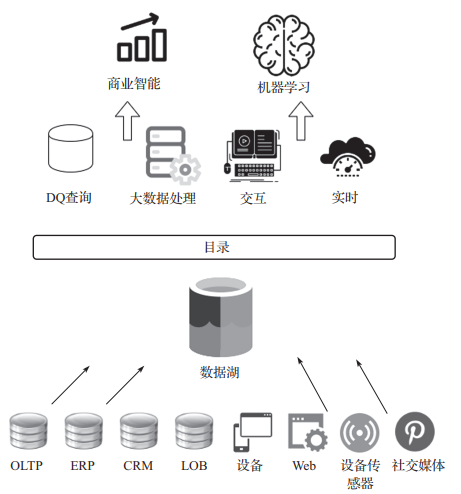
从各种来源摄取数据:数据湖可以让你在一个集中的位置存储和分析来自各种来源(如关系型、非关系型数据库以及流)的数据,以产生单一的真实来源。它解答了一些问题,例如,为什么数据分布在多个地方?单一真实来源在哪里? 采集并高效存储数据:数据湖可以摄取任何类型的数据,包括半结构化和非结构化数据,不需要任何模式。这就回答了如何从各种来源、各种格式的数据中快速摄取数据,并高效地进行大规模存储的问题。 随着产生的数据量不断扩展:数据湖允许你将存储层和计算层分开,对每个组件分别伸缩。这就回答了如何随着产生的数据量进行伸缩的问题。 将分析方法应用于不同来源的数据:通过数据湖,你可以在读取时确定数据模式,并对从不同资源收集的数据创建集中的数据目录。这使你能够随时、快速地对数据进行分析。这回答了是否能将多种分析和处理框架应用于相同的数据的问题。

延伸阅读👇

干货直达👇
评论