
CNN+Transformer=Better,国科大&华为&鹏城实验室提出Conformer,84.1% Top-1准确率

极市导读
作者提出了第一个将CNN与Vision Transformer相结合的双主干网络Conformer在MS-COCO数据集上,它在目标检测和实例分割任务上,分别比ResNet-101高出3.7%和3.6%的mAP。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但在捕获全局特征表示方面还是有一定的局限性。在Vision Transformer中,级联自注意力模块可以捕获长距离的特征依赖,但会忽略局部特征的细节。本文提出了一种混合网络结构,称为Conformer,以利用卷积操作和自注意力机制来增强特征表示的学习。Conformer依靠特征耦合单元(FCU),以交互的方式在不同分辨率下融合局部特征表示和全局特征表示。此外,Conformer采用并行结构,以最大限度地保留局部特征和全局表示。
作者通过实验证明,在相似的参数和复杂度下,Conformer在ImageNet上比DeiT-B好2.3%。在MS-COCO数据集上,它在目标检测和实例分割任务上,分别比ResNet-101高出3.7%和3.6%的mAP。
1. 论文和代码地址

论文地址:https://arxiv.org/abs/2105.03889
代码地址:https://github.com/pengzhiliang/Conformer
2. Motivation
在图像分类、目标检测和实例分割等计算机视觉任务中,CNN具有非常良好的性能。这在很大程度上归因于卷积操作,它以分层的方式收集局部特征以获得更好的图像表示。尽管在局部特征提取方面具有优势,但CNN捕获全局表示的能力还是不足,这对很多high-level的计算机视觉任务又是非常重要的。一个最直观的解决方案是扩大感受野,但是这就会破坏池化层的操作。

最近Transformer结构被用到了视觉任务中,ViT方法通过将每个图像分割为具有位置嵌入的Patch来构建一系列token,然后用Transformer Block来提取参数化向量作为视觉表示。由于自注意力机制(Self-Attention)和多层感知机(MLP)结构,Vision Transformer能够反映了复杂的空间变换和长距离特征依赖性,从而获得全局特征表示。然而,Vision Transformer会忽略了局部特征细节,这降低了背景和前景之间的可辨别性(如上图(c)和(g)所示)。因此,一些工作提出了一个tokenization模块或利用CNN特征图作为输入token来捕获特征的邻近信息。然而,这些方法依旧没有从根本上解决好局部建模和全局建模之间的关系。
在本文中,作者提出了一个双网络结构Conformer,能够将基于CNN的局部特征与基于Transformer的全局表示相结合,以增强表示学习。Conformer由一个CNN分支和一个Transformer分支组成,这两个分支由局部卷积块、自我注意模块和MLP单元的组合而成。在训练过程中,交叉熵损失函数被用于监督CNN和Transformer两个分支的训练,以获得同时具备CNN风格和Transformer风格的特征。
考虑到CNN与Vision Transformer特征之间的不对称性,作者设计了特性耦合单元(FCU)作为CNN与Vision Transformer 之间的桥接。一方面,为了融合两种风格的特征,FCU利用1×1卷积对齐通道尺寸,用下/上采样策略对齐特征分辨率,用LayerNorm和BatchNorm对齐特征值 。另一方面,由于CNN和Vision Transformer分支倾向于捕获不同级别的特征(局部和全局),因此将FCU插入到每个block中,以 连续 交互的方式消除它们之间的语义差异 。这种融合过程可以极大地提高局部特征的全局感知能力和全局表示的局部细节。
从上图可以看出,Conformer每个分支的特征表示都比单独使用CNN或者单独使用Transformer结构的特征表示要更好。传统的CNN倾向于保留可区分的局部区域,而Conformer的CNN分支还可以激活完整的物体范围。Vision Transformer的特征很难区分物体和背景,Conformer的分支对局部细节信息的捕获更好。
3. 方法
3.1. Overview
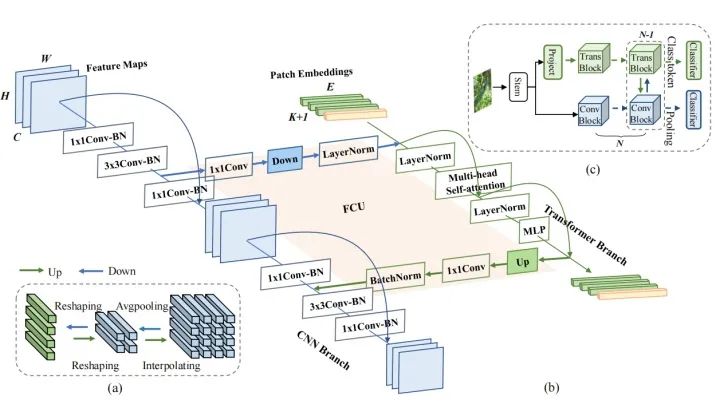
局部特征和全局特征在计算机视觉任务中得到了广泛的研究。局部特征是局部图像邻域的紧凑向量表示,一直是许多计算机视觉算法的组成部分。全局表示包括轮廓表示、形状描述符和长距离上的对象表示等等。在深度学习中,CNN通过卷积操作分层收集局部特征,并保留局部线索作为特征。Vision Transformer被认为可以通过级联的Self-Attention模块以一种soft的方式在压缩的patch embedding之间聚合全局表示。
为了利用局部特征和全局表示,作者设计了一个并发网络的结构Conformer,如上图(c)所示。考虑两种特征的互补性,作者将来自Vision Transformer分支的全局特征送入CNN中,以增强CNN分支的全局感知能力。类似的,将来自CNN分支的局部特征送入到Vision Transformer中,以增强Vision Transformer分支的局部感知能力。这样的过程构成了interaction的作用。

具体实现上,Conformer由一个stem模块、双分支、桥接双分支的FCU和每个分支上的分类器(FC)组成。Stem模块是一个步长为2的7×7卷积和步长为2的3×3 max pooling,用于提取初始局部特征,然后分别送入到两个分支中。CNN分支和Transformer分支分别由N个重复卷积和Transformer块组成(具体设置如上表所示)。这种并发结构意味着CNN和Transformer分支分别可以最大限度地保留局部特征和全局表示。FCU被提出作为一个桥接模块,将CNN分支的局部特征与Transformer分支的全局表示融合,如上图(b)所示。沿着这些分支结构,FCU会以交互式的方式逐步融合feature map和patch embedding。
最后,对于CNN分支,所有的特征被合并之后输入给一个分类器。对于Transformer分支,取出[cls] token之后送入给另一个分类器进行分类。在训练过程中,作者使用两个交叉熵损失来分别监督这两个分类器。损失函数的重要性权重被设置为是相同的。在推理过程中,作者将这两个分类器的输出简单地相加作为预测结果。
3.2. Network Structure
3.2.1. CNN Branch
如上图(b)所示,CNN分支采用特征金字塔结构,其中特征图的分辨率随着网络深度的增加而降低,而通道数随着网络深度的增加而增加。作者将整个CNN分支分为4个阶段(如上表所示)。每个阶段由多个卷积块组成,每个卷积块包含个bottleneck。在实验中,在第一个卷积块中被设置为1,并在随后的N−1卷积块中设置为。
Vision Transformer通过一个简单的patch embedding步骤将一个图像patch投影到一个特征向量中,导致局部细节的丢失。而在CNN中,卷积核在具有重叠的特征映射上滑动,最大程度的保留了局部特征。因此,CNN分支能够连续地为Transformer分支提供局部的特征细节。
3.2.2. Transformer Branch
在Transformer分支中,包含N个重复的Transformer块。从上图(b)可以看出,每个Transformer块由一个Multi-head Self-Attention模块和一个MLP模块组成,在每一层的Self-Attention层和MLP块都用了LayerNorm进行归一化。为了tokenization,作者将CNN中的stem模块生成的特征映射压缩为14×14的无重叠的patch embedding(通过一个步长为4的4x4卷积),然后在加入一个[cls] token用于分类。由于CNN分支(3×3卷积)同时编码局部特征和空间位置信息,这里就不再需要position encoding。
3.2.3. Feature Coupling Unit
给定CNN分支中的特性映射和Transformer分支中的patch embedding,如何消除它们之间的特征错位 是一个重要的问题。为了解决这个问题,作者提出了FCU以交互式的方式连续地结合局部特征和全局表示。
一方面,作者认识到CNN和Transformer的特征维度是不一致的。CNN特征的维度是C×H×W(C、H、W分别为通道、高度和宽度),但是Transformer的patch embedding维度是(K + 1) × E(K、1和E分别表示图像patch的数量、[cls] token的数量和embedding维度)。当输入给Transformer分支时,首先需要通过1×1卷积来对齐通道维度,然后进行下采样(如上图(a)所示)。当从Transformer分支送入到CNN分支时,也是需要通过1×1卷积来对齐通道维度,进行上采样(如上图(a)所示)。此外LayerNorm和BatchNorm用于归一化特征。
另一方面,CNN特征和Patch Embedding之间存在显著的语义差距,因为CNN特征映射通过局部卷积运算得到,而Patch Embedding则是通过全局自注意力机制进行聚合的。因此,FCU应用于每个block中以逐步填补语义信息的差距。
4.实验
4.1. Image Classification

如上表所示,在类似的参数量和计算量下,Conformer的性能均优于CNN和Vision Transformer。
4.2. Object Detection and Instance Segmentation
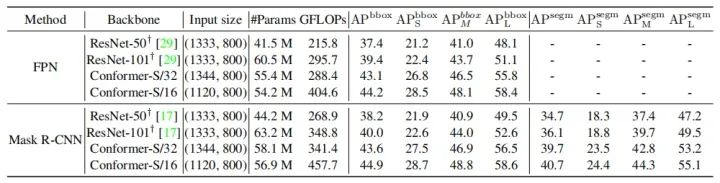
如上表所示,Conformer显著提高了和。
4.3. Ablation Studies
4.3.1. Number of Parameters.

上表展示了不同参数量下的性能。可以看出,通过增加CNN或Vision Transformer分支的参数量,可以提高精度。
4.3.2. Dual Structure
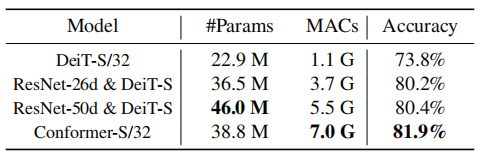
可以看出,具有相当的计算量下,Conformer-S/32优于串行的结构。
4.3.3. Positional Embeddings

当去除Positional Embedding时,DeiT-S的精度降低了2.4%,而Conformer-S的精度略有下降。
4.3.4. Sampling Strategies

上表展示了不同的上/下采样策略,包括max-pooling、mean-pooling、卷积和基于注意力采样的结果。
4.3.5. Comparison with Ensemble Models

如上图所示,CNN支路、Transformer支路、Conformer-S的精度分别达到83.3%、83.1%和83.4%。而CNN和Transformer集成模型的精度也只有81.8%。
4.3.5. Generalization Capability

上图展示了不同旋转角度和分辨率下,不同模型的泛化性能。
5. 总结
在本文中,作者提出了第一个将CNN与Vision Transformer相结合的双主干网络Conformer。在Conformer中,作者利用卷积算子来提取局部特征、利用自注意力机制来捕获全局表示。此外,作者设计了特征耦合单元(FCU)来融合局部特征和全局表示,以交互的方式增强了视觉表示的能力。实验表明,Conformer在相似的参数和计算量下,优于传统的CNN和Vision Transformer。在各种下游任务中,Conformer也展现出了成为一个简单而有效的主干网络的巨大潜力。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
