
Pandas从小白到大师学习指南
作者:Rudolf Höhn
机器之心编译
在本文中,作者从 Pandas 的简介开始,一步一步讲解了 Pandas 的发展现状、内存优化等问题。这是一篇最佳实践教程,既适合用过 Pandas 的读者,也适合没用过但想要上手的小白。
Pandas 发展现状
内存优化
索引
方法链
随机提示

import pandas as pdimport numpy as npimport os# to download https://www.kaggle.com/russellyates88/suicide-rates-overview-1985-to-2016data_path = 'path/to/folder/'df = (pd.read_csv(filepath_or_buffer=os.path.join(data_path, 'master.csv')).rename(columns={'suicides/100k pop' : 'suicides_per_100k', ' gdp_for_year ($) ' : 'gdp_year', 'gdp_per_capita ($)' : 'gdp_capita', 'country-year' : 'country_year'}).assign(gdp_year=lambda _df: _df['gdp_year'].str.replace(',','').astype(np.int64)) )
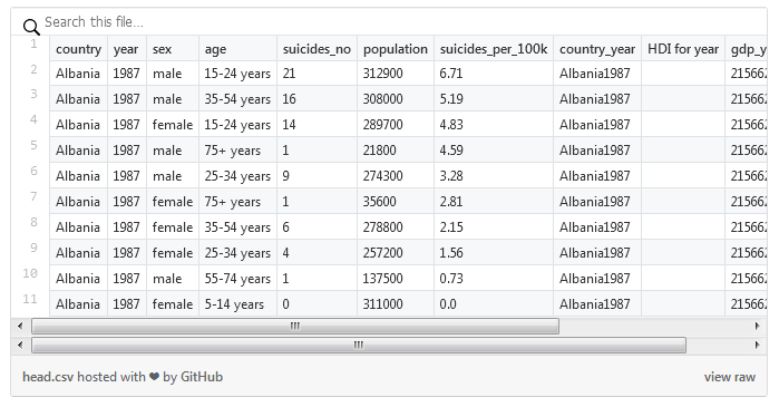
> df.columnsIndex(['country', 'year', 'sex', 'age', 'suicides_no', 'population', 'suicides_per_100k', 'country_year', 'HDI for year', 'gdp_year', 'gdp_capita', 'generation'], dtype='object')> df['generation'].unique()array(['Generation X', 'Silent', 'G.I. Generation', 'Boomers', 'Millenials', 'Generation Z'], dtype=object)> df['country'].nunique()101
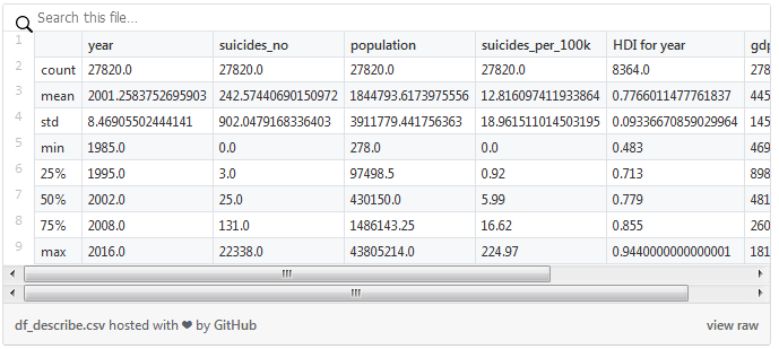
import pandas as pddef mem_usage(df: pd.DataFrame) -> str:"""This method styles the memory usage of a DataFrame to be readable as MB. Parameters ---------- df: pd.DataFrame Data frame to measure. Returns ------- str Complete memory usage as a string formatted for MB. """return f'{df.memory_usage(deep=True).sum() / 1024 ** 2 : 3.2f} MB'def convert_df(df: pd.DataFrame, deep_copy: bool = True) -> pd.DataFrame:"""Automatically converts columns that are worth stored as ``categorical`` dtype. Parameters ---------- df: pd.DataFrame Data frame to convert. deep_copy: bool Whether or not to perform a deep copy of the original data frame. Returns ------- pd.DataFrame Optimized copy of the input data frame. """return df.copy(deep=deep_copy).astype({ col: 'category' for col in df.columns if df[col].nunique() / df[col].shape[0] < 0.5})
了解数据框使用的类型;
了解数据框可以使用哪种类型来减少内存的使用(例如,price 这一列值在 0 到 59 之间,只带有一位小数,使用 float64 类型可能会产生不必要的内存开销)
如果你是用 R 语言的开发人员,你可能觉得它和 factor 类型是一样的。
categorical_dict = {0: 'Switzerland', 1: 'Poland'}> mem_usage(df)10.28 MB> mem_usage(df.set_index(['country', 'year', 'sex', 'age']))5.00 MB> mem_usage(convert_df(df))1.40 MB> mem_usage(convert_df(df.set_index(['country', 'year', 'sex', 'age'])))1.40 MB
> %%time>>> df.query('country == "Albania" and year == 1987 and sex == "male" and age == "25-34 years"')CPU times: user 7.27 ms, sys: 751 µs, total: 8.02 ms# ==================>>> %%time> mi_df.loc['Albania', 1987, 'male', '25-34 years']CPU times: user 459 µs, sys: 1 µs, total: 460 µs
%timemi_df = df.set_index(['country', 'year', 'sex', 'age'])CPU times: user 10.8 ms, sys: 2.2 ms, total: 13 ms
> (pd.DataFrame({'a':range(2), 'b': range(2)}, index=['a', 'a']) .loc['a'])a ba 0 0a 1 1
%%time>>> mi_df.sort_index()CPU times: user 34.8 ms, sys: 1.63 ms, total: 36.5 ms>>> mi_df.index.is_monotonicTrue
Pandas 高级索引用户指南:https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html;
Pandas 库中的索引代码:https://github.com/pandas-dev/pandas/blob/master/pandas/core/indexing.py。
import numpy as npimport pandas as pddf = pd.DataFrame({'a_column': [1, -999, -999], 'powerless_column': [2, 3, 4], 'int_column': [1, 1, -1]})df['a_column'] = df['a_column'].replace(-999, np.nan)df['power_column'] = df['powerless_column'] ** 2df['real_column'] = df['int_column'].astype(np.float64)df = df.apply(lambda _df: _df.replace(4, np.nan))df = df.dropna(how='all')
df = (pd.DataFrame({'a_column': [1, -999, -999],'powerless_column': [2, 3, 4],'int_column': [1, 1, -1]}).assign(a_column=lambda _df: _df['a_column'].replace(-999, np.nan)).assign(power_column=lambda _df: _df['powerless_column'] ** 2).assign(real_column=lambda _df: _df['int_column'].astype(np.float64)).apply(lambda _df: _df.replace(4, np.nan)).dropna(how='all') )

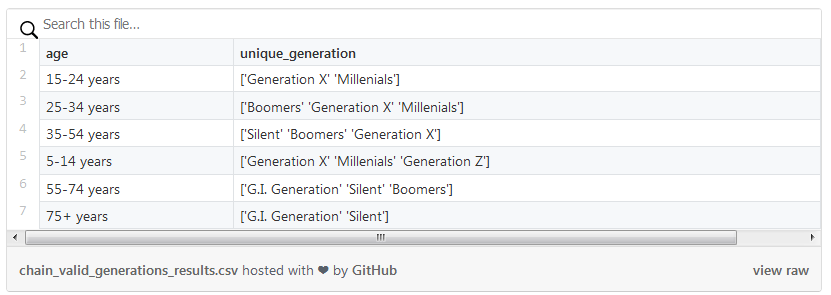
(df.groupby('age').agg({'generation':'unique'}).rename(columns={'generation':'unique_generation'})# Recommended from v0.25# .agg(unique_generation=('generation', 'unique')))
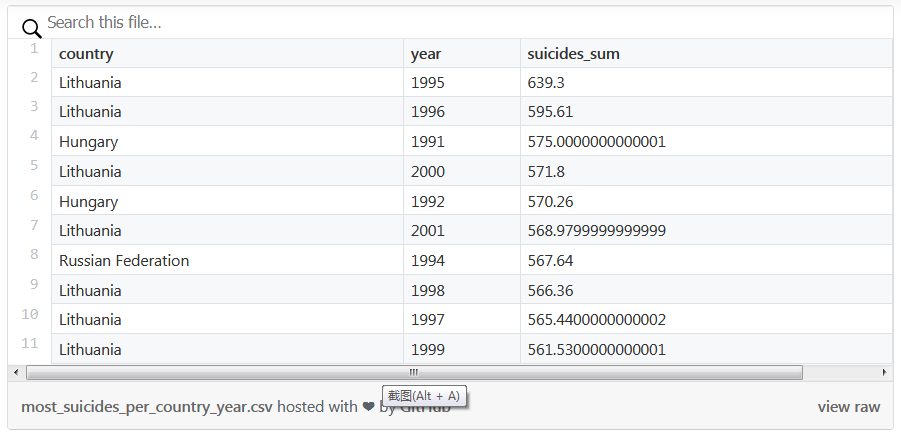
(df.groupby(['country', 'year']).agg({'suicides_per_100k': 'sum'}).rename(columns={'suicides_per_100k':'suicides_sum'})# Recommended from v0.25# .agg(suicides_sum=('suicides_per_100k', 'sum')) .sort_values('suicides_sum', ascending=False) .head(10))
(df.groupby(['country', 'year']).agg({'suicides_per_100k': 'sum'}).rename(columns={'suicides_per_100k':'suicides_sum'})# Recommended from v0.25# .agg(suicides_sum=('suicides_per_100k', 'sum')).nlargest(10, columns='suicides_sum'))
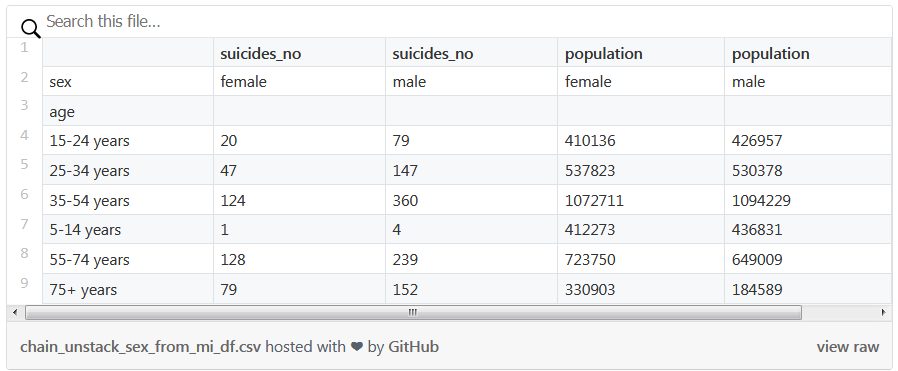
(mi_df.loc[('Switzerland', 2000)].unstack('sex') [['suicides_no', 'population']])
def log_head(df, head_count=10):print(df.head(head_count))return dfdef log_columns(df):print(df.columns)return dfdef log_shape(df):print(f'shape = {df.shape}')return df
(df.assign(valid_cy=lambda _serie: _serie.apply(lambda _row: re.split(r'(?=\d{4})',_row['country_year'])[1] == str(_row['year']), axis=1)).query('valid_cy == False').pipe(log_shape))
shape = (0, 13)(df .pipe(log_shape).query('sex == "female"').groupby(['year', 'country']).agg({'suicides_per_100k':'sum'}).pipe(log_shape).rename(columns={'suicides_per_100k':'sum_suicides_per_100k_female'})# Recommended from v0.25# .agg(sum_suicides_per_100k_female=('suicides_per_100k', 'sum')).nlargest(n=10, columns=['sum_suicides_per_100k_female']))
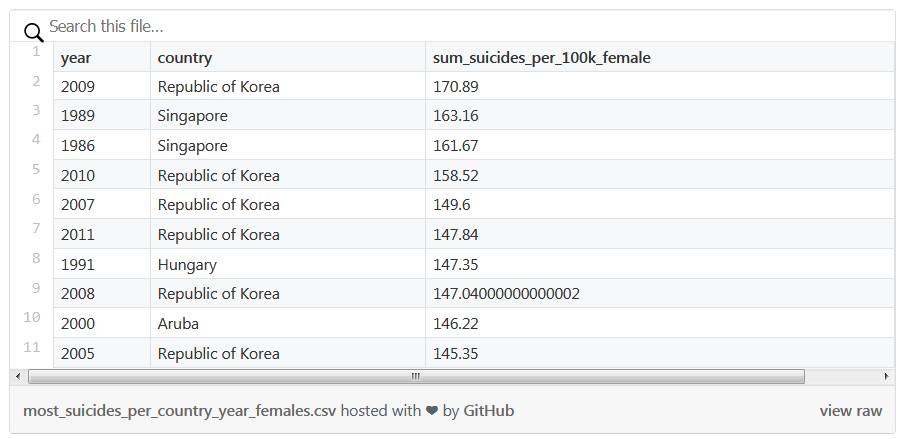
shape = (27820, 12)shape = (2321, 1)
from sklearn.preprocessing import MinMaxScalerdef norm_df(df, columns):return df.assign(**{col: MinMaxScaler().fit_transform(df[[col]].values.astype(float))for col in columns})for sex in ['male', 'female']:print(sex)print( df .query(f'sex == "{sex}"').groupby(['country']).agg({'suicides_per_100k': 'sum', 'gdp_year': 'mean'}).rename(columns={'suicides_per_100k':'suicides_per_100k_sum', 'gdp_year': 'gdp_year_mean'})# Recommended in v0.25# .agg(suicides_per_100k=('suicides_per_100k_sum', 'sum'),# gdp_year=('gdp_year_mean', 'mean')).pipe(norm_df, columns=['suicides_per_100k_sum', 'gdp_year_mean']).corr(method='spearman') )print('\n')
malesuicides_per_100k_sum gdp_year_meansuicides_per_100k_sum 1.000000 0.421218gdp_year_mean 0.421218 1.000000
femalesuicides_per_100k_sum gdp_year_meansuicides_per_100k_sum 1.000000 0.452343gdp_year_mean 0.452343 1.000000
>>> %%time>>> for row in df.iterrows(): continueCPU times: user 1.97 s, sys: 17.3 ms, total: 1.99 s>>> for tup in df.itertuples(): continueCPU times: user 55.9 ms, sys: 2.85 ms, total: 58.8 ms

评论