
如何优雅的夺冠问答匹配竞赛(开源代码+上分Tricks)
团队介绍:看我看啥
- 成员1:许明 中国海洋大学
- 成员2:刘猛 南京大学
非常感谢第一名“看我干啥”分享的方案 原文:https://xv44586.github.io/2021/01/20/ccf-qa-2/#sai-ti 作者:看我干啥 代码链接:https://github.com/xv44586/ccf_2020_qa_match
- [前言]
- [赛题]
- [QA pair]
- [QA Point]
- [Pattern-Exploiting Training (PET)]
- [Concat]
- [focal loss]
- [对抗训练]
- [post training]
- [Post Training]
- [MLM]
- [nsp]
- [model-adaptive]
- [更新次数]
- [最终结果]
- [融入知识]
- [对比学习]
- [非监督对比学习]
- [监督对比学习]
- [实验结果]
- [数据增强]
- [EDA]
- [伪标签]
- [实验结果]
- [自蒸馏]
- [shuffle 解码]
- [模型融合]
- [实验总结]
- [比赛结果]
- [代码]
- [最后]
- [关于头图]
 ccf问答匹配比赛也结束了一段时间了,这篇算是一个下篇吧,总结一下后期优(夺)化(冠)的心路历程。标题中的“bert”指的是bert-base系列模型,包括bert/RoBERTa/NEZHA/MacBERT/ERNIE等,而取这个有点“标题党”的标题的主要原因,也是对答辩看到有些团队使用的bert+xgb这种“大力出奇迹”做法吐个槽。
ccf问答匹配比赛也结束了一段时间了,这篇算是一个下篇吧,总结一下后期优(夺)化(冠)的心路历程。标题中的“bert”指的是bert-base系列模型,包括bert/RoBERTa/NEZHA/MacBERT/ERNIE等,而取这个有点“标题党”的标题的主要原因,也是对答辩看到有些团队使用的bert+xgb这种“大力出奇迹”做法吐个槽。前言
在上一篇中,笔者对比赛做了简单说明,提出了四种baseline(QA Pair/QA Point/PET/Concat),并做了部分尝试(focal loss/对抗训练/梯度惩罚/kfold/post training),没看过的同学可以先看上篇,这里只简单再介绍一下:赛题
比赛链接:
https://www.datafountain.cn/competitions/474

本次赛题的任务是:给定IM交流片段,片段包含一个客户问题以及随后的经纪人若干IM消息,从这些随后的经纪人消息中找出一个是对客户问题的回答。数据示例

评测标准
QA pair
由于回答列表是不连续的,所以不考虑问答之间的顺序关系,将其拆分为query-answer pair,然后进行判断。QA Point
考虑对话连贯性、相关性,将所有回答顺序拼接后再与问题拼接,组成query-answer list,模型对一个问题的所有答案进行预测。此外,我们还给模型增加了“大局观”,即新增一个任务来预测全局所有回答中是否存在label为 1 的回答。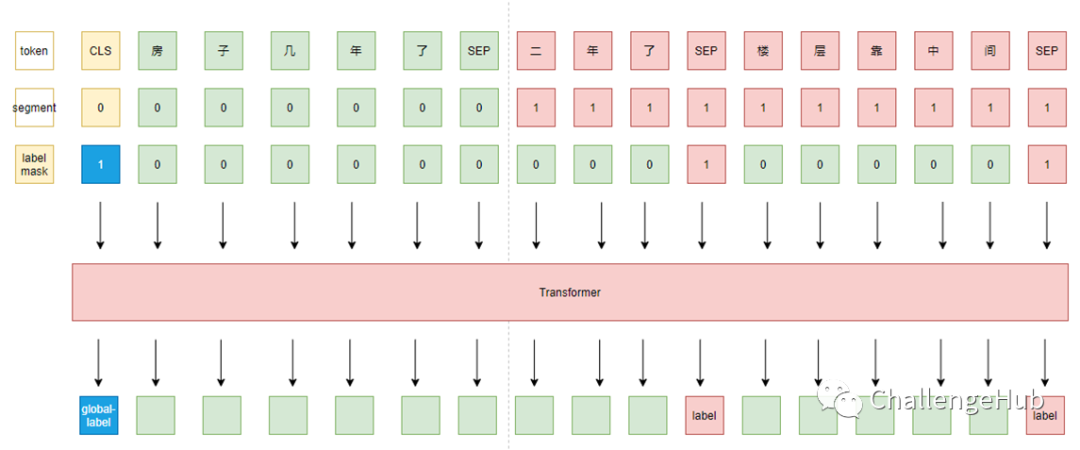
Pattern-Exploiting Training (PET)
此方案通过增加一个pattern,将任务转换为MLM任务,然后通过pattern的得分来判断对应的类别。如本次比赛可以添加一个前缀pattern:“间接回答问题”/ “直接回答问题”,分别对应label 0 / 1,pattern的得分只需看第一个位置中“间”/“直”两个token的概率谁高即可。对于unlabel data,可以不增加pattern 进行mlm任务,这也在一定程度增加了模型的泛化能力。此外,通过多个不同pattern进行融合也能进一步提高其性能。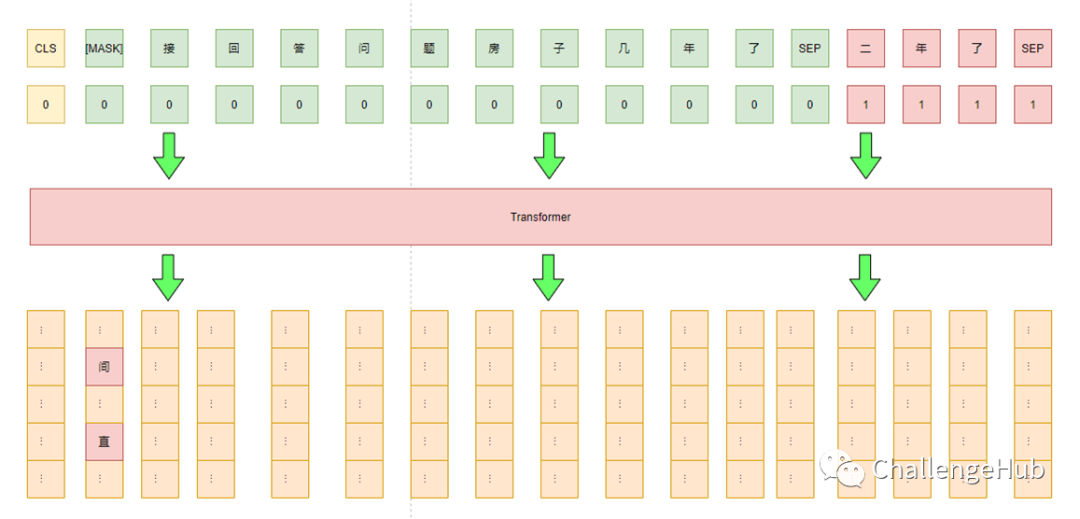
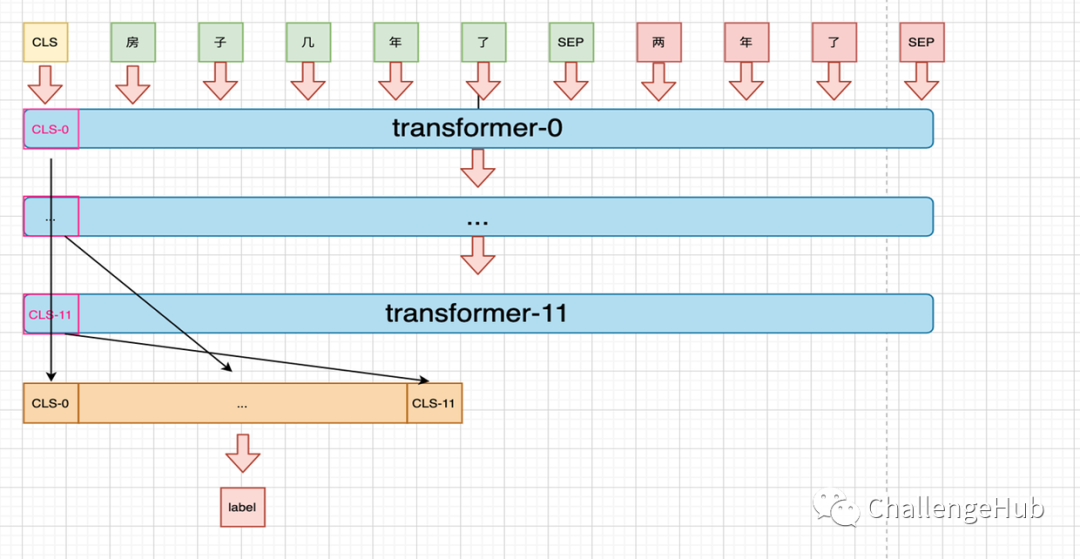
Concat由于bert 中不同的transformer 层提取到的语义粒度不同,而不同粒度的信息对分类来说起到的作用也可能不同,所以可以将所有粒度的语义信息拼接后作为特征进行分类。
focal loss
由于针对性回答与非针对性回答在数量上有不小差距,大约3:1,所以也想到尝试在loss上进行调节。最终结果是没有多少提升,猜测样本不均衡的问题影响是非常小的,所以将Binary-Crossentropy训练后的模型在train data上进行了predict,并借鉴之前focal loss中的方式分析了一下,画出对应的难易样本分布。根据图形上的分布结果,也证实了之前的猜测。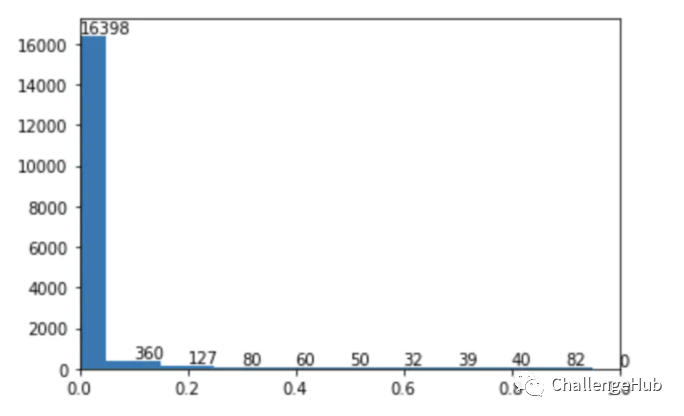
对抗训练
对抗训练主要尝试了FGM 方法对Embedding进行扰动,线下对比提升大约一个点上下。线下测试结果:
without adt0.831with adt0.838without adtwith adt0.8310.838
post training
上一篇中,提到post training 做的效果不好,然而pet 的效果又很好,两者比较矛盾,所以我也重新阅读了几篇关于优化bert 与post training 相关的论文,重新思考了一下,这篇就从重新做post training开始。Post Training
post training一般包括两部分:Domain-Adaptive training 和 Task-Adaptive training,通过在同领域与任务数据上继续预训练,可以让模型更适应任务,有利于提高模型在下游的性能。而bert 在训练时主要有两个任务:mlm 与nsp ,接下来针对每个任务进行讨论。MLM
在post training 阶段尝试进一步优化的只找到刘知远老师的Train No Evil: Selective Masking for Task-Guided Pre-Training,论文里的思路是通过建立一个二分类模型,来有针对性的选择token 来进行mask,不过由于这个方法比较麻烦,需要三个中间模型,所以没有尝试,不过这个论文给出了一个结论:在继续预训练的过程中,优化mask 策略,是可以进一步提高下游性能的。让我们回归一下bert 的mask 策略即后续的改进:
这里笔者思考后认为,不同的mask 策略本质区别是对更多的“固定搭配”进行同时mask,从而降低模型对局部、浅层信息的过拟合,增加任务的难度,提高模型的泛化能力。所谓“固定搭配”,不仅仅包含词,或者说是更广义的“词”。字的固定搭配可以构成词,进一步固定搭配又可以形成短语。比如考虑“好好学习,天天向上”,“08北京奥运会”,如果只mask 其中一部分,是比较“容易”通过剩余的部分来还原的。既然“固定搭配”是更广义的词,这里我们就可以来挖掘这些“固定搭配”了。最简单的方式就是新词/短语挖掘,而新词/短语挖掘最常用的方法是计算左右熵和紧密度,不过这种方式计算量较大,这次比赛笔者舍弃了这种方式,采用借鉴苏神的博客最小熵原理(二):“当机立断”之词库构建中的思路,用PMI表征紧密度,用相邻两个字之间的紧密度判断两者是否存在“固定搭配”,最终未被切分的为一个整体。最后将挖掘出的新词通过jieba 过滤掉已在词库内的,并只保留长度2~5的新词,添加到jieba的词库内。这里选择用jieba 做分词工具的原因是因为笔者用的是NEZHA,而NEZHA在训练时使用的就是jieba 处理的数据,这里与他保持一致,而长度选择上,主要借鉴spanBert中的结论。最后挖掘了2736个新词,而如果是实际工作中,则可以进一步将积累的词也加入。
以上的方式中全程没有人为参与,所以新词的质量是无法保证的,即存在词的边界不准确。而此时的全词mask 退化为n-gram mask,依然是一种有效的提升方案。
nsp
原始bert 在训练时,句子级别的任务为nsp,而RoBERTa 中给出的结论是句子级别的任务没什么用,所以取消了句子级别的任务;而albert 中则将句子级别的任务切换为sop,而SpanBERT中则切换为sbo。这里笔者认为下游任务是句子级别的分类任务,所以句子级别的任务是有用的,不过由于nsp 会引入大量噪音,所以这里选择sop/aop:在qa pair格式的样本下互换qa(sop),在q a-list格式的样本下,保持query 在最前面,只shuffle a-list(aop)。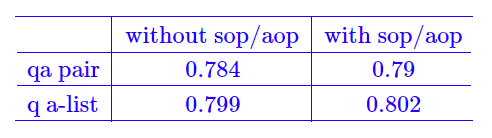
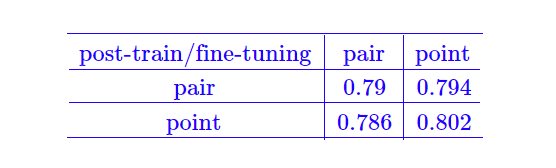
model-adaptive
由于样本的组织方式有qa pair 和 q a-list两种方式,而task 相关的数据是相对较小的,所以这里笔者认为两个阶段的样本组织方式相同的情况下,性能会更好,即:用qa pair格式post training后的模型,来微调qa pair格式的baseline,q a-list格式post training后的模型微调q a-list格式的baseline。更新次数
这里参考邱锡鹏老师的How to Fine-Tune BERT for Text Classification?,实验时每10 个epochs保存一次模型,最后通过在下游任务上的表现,得出与论文中基本一致的结论:更新10K steps左右模型在下游的表现是最好的。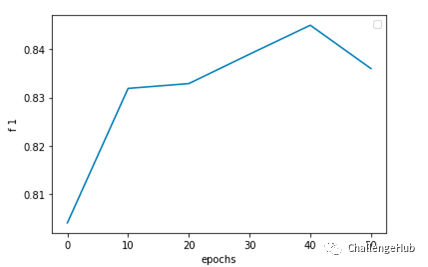
最终结果
此时我们认为已经将bert的能力最大化了,于是这里也尝试了在bert 后面接一些复杂的分类层(cnn/rnn/dgcnn/..),发现都无法进一步提高,所以也证实了之前的判断。
融入知识
既然从“内部”已经无法进一步提高bert的能力,所以此时尝试融入外部知识来增强。而融合的方式主要尝试了两种:最底层注入 在Embedding 层融入外部的embedding。优点:更多的交互
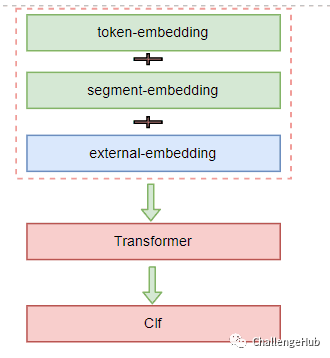
最顶层注入 在transformer output 层融入外部Embedding。优点:更灵活,不局限外部知识的形式(可以是Embedding,也可以说是其他特征,如手工特征)。
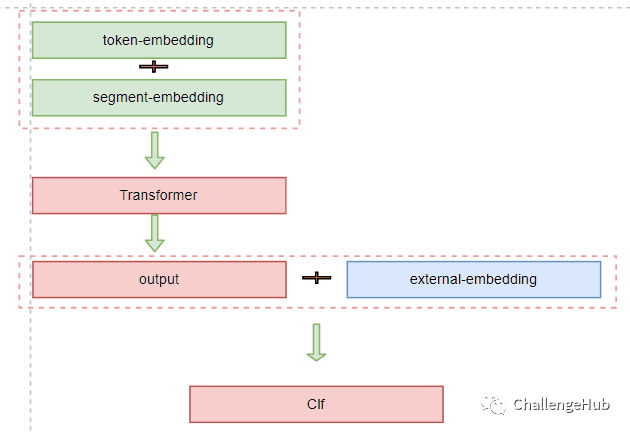
在知识选择上,首先想到的是Graph EMbedding,参考VGCN-BERT: Augmenting BERT with Graph Embedding for Text Classification,我们重跑了一下论文的代码,发现无法重现其中的结论,而我对Graph Embedding也不熟,所以放弃了这个方案。然后尝试简单的embedding,即用gensim 在task data上训练了一版词向量(dims=100),作为外部知识来实验。线下测试结果:
可以看到,两种方式都是无法进一步提高的,主要原因可能是:1.词向量的质量较差;2.词向量也是bert的“内部”知识;3.融入的方式或者调参没做好。对比学习
在模型上,还能通过增加新的任务来尝试提高性能。而今年比较热的一个思路就是对比学习,所以这里尝试通过增加一个对比学习任务来提高性能。对比学习的主要思路是拉近到正样本之间的距离,拉远到负样本之间的距离。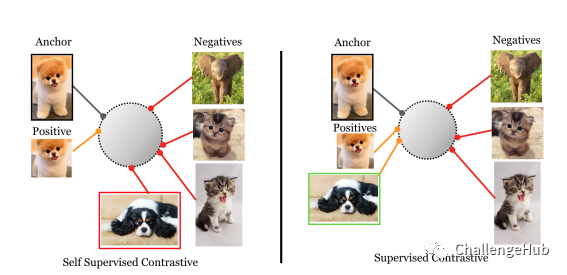
对比学习主要又分为两种:监督对比学习和分监督对比学习。监督对比学习中,将相同label的样本看做是正例,其他的为负例;而非监督对比学习中,则通过对每个样本构造一对view,view之间互为正例,其他的为负例。非监督对比学习
非监督对比学习中,通过互换QA位置,同时随机mask 15% 的token,来构造一对view。- 对应的loss:
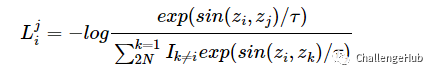 image
image- 对应的模型:
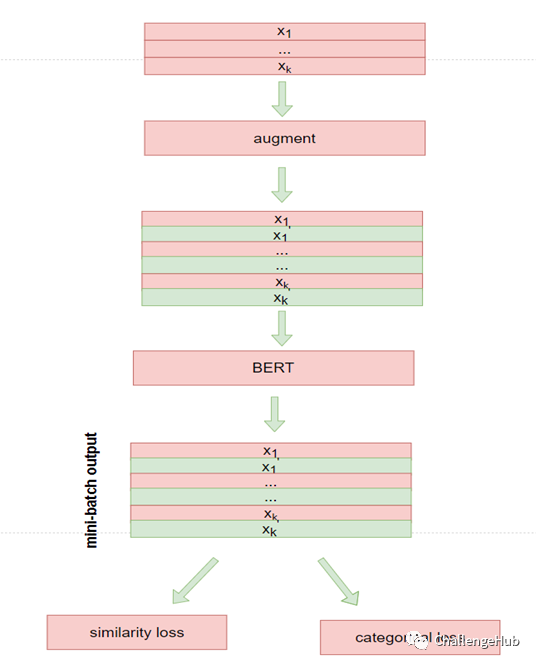 image
image监督对比学习
这里主要follow Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning,修改对应loss.- loss
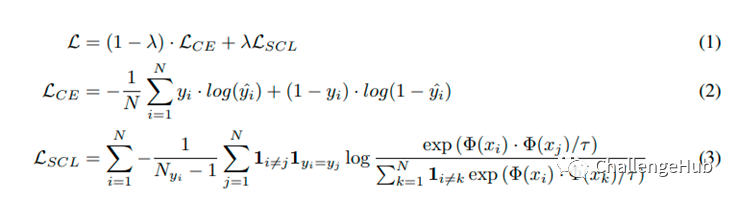 image
image- model
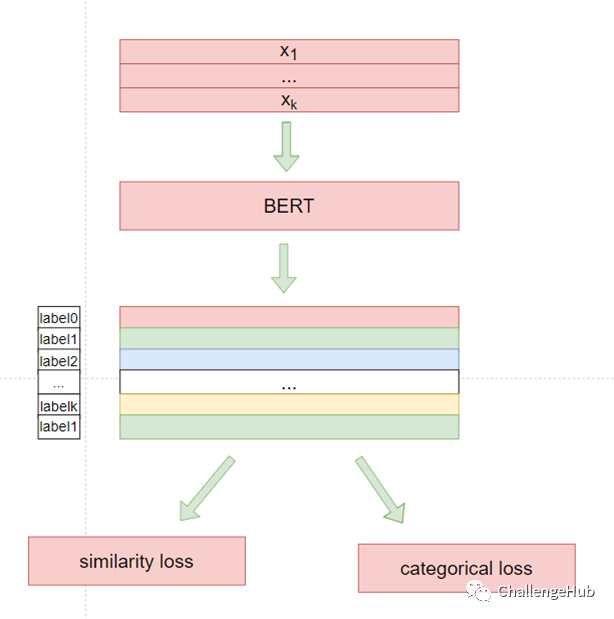 image
image实验结果
- 线下结果:

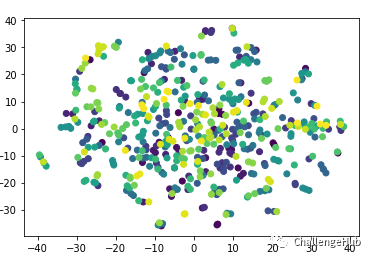
非监督对比学习结果可视化
监督对比学习结果可视化
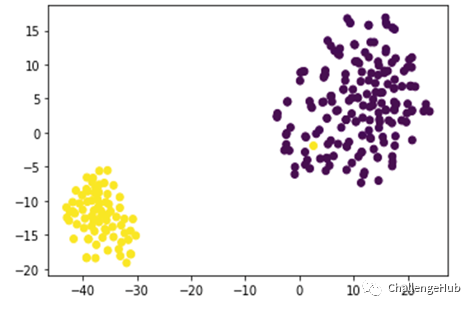
可以看到,两种方式都没有带来提升,而可视化图中可以看到,非监督对比学习的效果并不好,存在大量重叠但颜色不同的点,说明对比学习任务的结果不好,这里的原因猜测主要有两点:1.模型的设计与调参时有问题,batch size(32)太小,没有BN 层等,都有可能是性能不好的原因;2.构造view 的方式过于简单粗暴,由于样本长度大多较短,随机mask 后即有可能引入错误的label 信息,又可能引起view 间语义的gap过大,无法互为正例。监督学习效果图中,不同label的数据被分到了不同的簇中,说明对比学习的还是相当不错,不过由于此次比赛中的label 代表的是“是否是针对问题的回答”,label 相同但内涵不同,所以强行将相同label的样本聚合,并不能带来提升。数据增强数据增强主要尝试了两种方式:EDA 和伪标签。
EDA
EDA主要包括四种方式:随机替换、随机删除、随机重复和随机互换。由于词向量质量较差,所以操作时选择从当前句子中随机选取一个词作为“同义词”进行操作。操作比例为10%,每个样本构造四个样本。用训练过的模型对数据进行过滤,保留置信度高(>0.7)的样本。伪标签
用训练过的模型在test data 上进行预测,对预测结果按0.5 为阈值计算置信度并进行排序,保留前30%的样本加入训练集。这里没有单纯按置信度过滤样本,是因为模型预测结果大多数大于0.95或小于0.05,而过多的测试数据进入训练集,会导致模型最终的结果是在拟合训练集中的label,而无法带来提高(充分学习后的模型在训练数据上的预测结果自然是训练时的label)。实验结果
- 线上结果

自蒸馏
借助知识蒸馏,我们尝试了自蒸馏方案:即Teacher 与 Student 为同一个模型,Teacher模型先学习一遍后,对训练样本打上soft labels,Student 同时学习true labels 与 soft labels.soft labels:
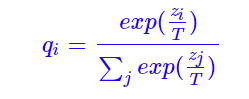
线下测试结果:

shuffle 解码
对于q a-list 的模型,可以在预测时,对answer list 进行全排列,然后将结果投票,一来可以将answer label之间的影响降低,二来可以在非常小的成本下融合,也算是一种trick。不过此次比赛的数据对顺序比较敏感,shuffle后大多数情况下会降低模型的性能,所以最终融合后结果没提升反而降低了。模型融合
为了提高模型的稳定性与泛化能力,我们进行了模型融合。融合时,我们期望模型间能“和而不同”:每个单模型的性能之间差异小(都要接近最优单模型),且模型之间差异尽量大(架构或者优化方案上差异尽量大)。根据以上策略,对QA Pair 与 QA Point两种模型进行融合。实验总结
能work的方案
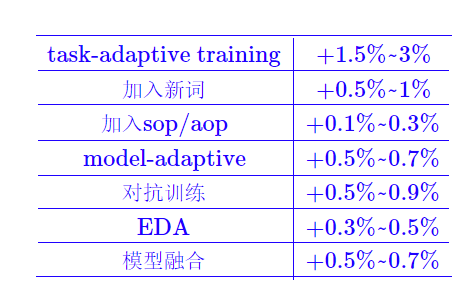
不能work的方案

线下有效但未提交

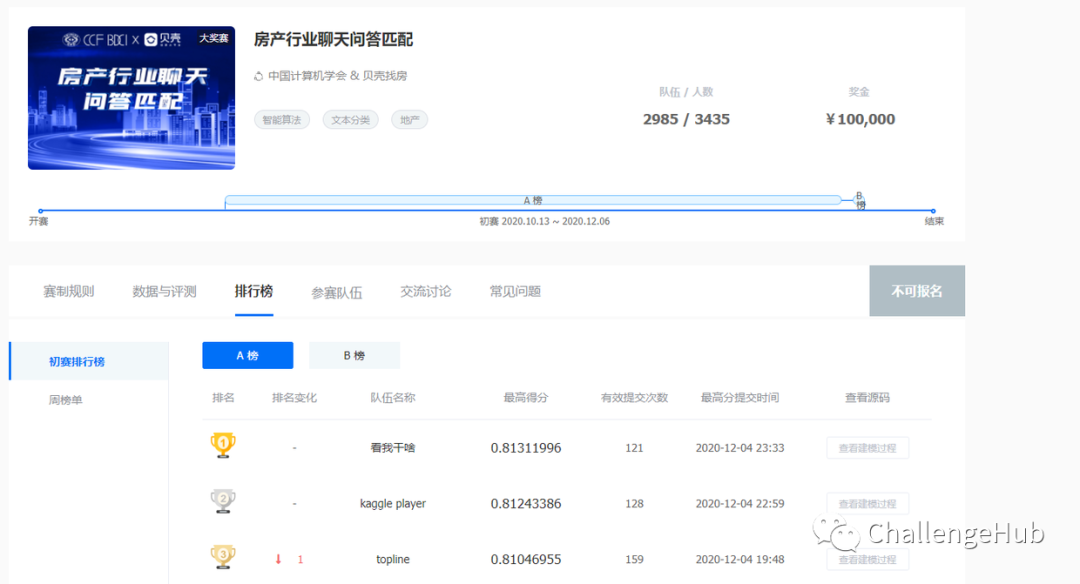
对于PET ,在post training后的效果并不是很好,不过由于没有时间了,所以没有继续优化。这里提一下可以优化的点:1.可以增加解码空间;2.增加多个pattern 进行融合的方式尝试优化。笔者本人是比较喜欢PET 这个思路的,统一了两个阶段,所以可做的事还有很多。比赛结果比赛最终的线上成绩在A/B 榜均是第一,答辩阶段也得到了第一。
A榜得分:
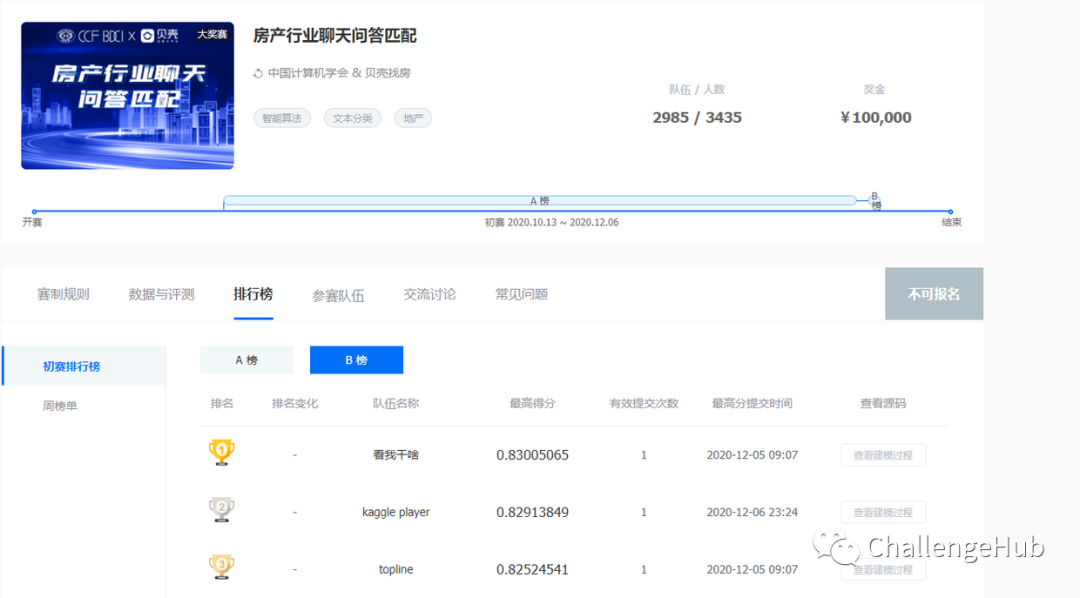
B榜得分:
答辩得分:
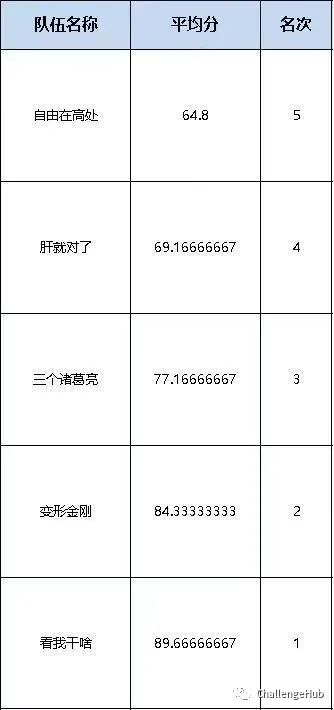
代码
比赛相关思路的代码开源在github上:ccf_2020_qa_match欢迎大家尝试使用,有问题或者想法可以提issue,一起讨论。
https://github.com/xv44586/ccf_2020_qa_match
最后
本文主要总结了此次ccf 问答匹配中的实验思路,而其中提出的四种baseline ,可以横向推广至所有的文本分类相关的任务中,而优化相关的方案,则可以应用在所有bert-base 模型上。从最初打算“白嫖”一份数据,到最终拿到第一,算起来这应该是笔者第一次参加NLP的比赛,所以很幸运也很惊喜。Enjoy!