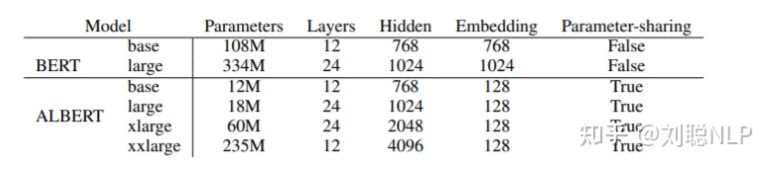
ALBERT 如何有效减少 BERT 的参数?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达



推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论
 下载APP
下载APP点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!