
华为深度学习新模型DeepShift:移位和求反代替乘法,神经网络成本...
新智元报道
来源:Arxiv编辑:大明【新智元导读】深度学习模型,尤其是卷积神经网络的计算成本问题主要是由于卷积层和全连接层中大量进行乘法运算造成的。华为异构实验室的研究人员提出,用移位和求反运算代替乘法,可有效缓解计算成本过高的问题,同时精度与传统模型差距很小。戳右边链接上 新智元小程序 了解更多!
深度学习模型(尤其是深度卷积神经网络)已在多种计算机视觉应用中获得了很高的准确性。但是,对于在移动环境中进行部署,事实证明,高计算量和功耗预算是主要瓶颈。卷积层和完全连接的层,由于它们大量使用乘法,是此计算预算的主要贡献者。
本文建议通过引入两个新的运算来解决该问题:卷积移位和全连接移位,这两种运算替换了乘法,并执行按位移位和按位求反操作。这套使用这两种运算代替乘法的神经网络体系结构称为DeepShift。
利用无需乘法即可实现的DeepShift模型,研究人员在CIFAR10数据集上的准确度高达93.6%,在Imagenet数据集上的Top-1 / Top-5准确度高达70.9%/ 90.13%。
在将所有卷积层和完全连接的层转换为按比特移位的对应层后,研究人员对各种著名的CNN架构进行了广泛测试,结果发现在一些架构中,Top-1的准确性下降了不到4%,Top-5的准确度下降了不到1.5%。实验在PyTorch框架上进行,培训和运行代码与论文一起提交,并将在线提供。

深度学习模型(尤其是DCNN)已在多种计算机视觉应用达到了很高精度。但是,对于在移动环境中的实例,大计算量和高功耗带来的高成本仍然是主要瓶颈。对于卷积层和全连接层,由于大量使用乘法,成为推高计算成本预算的主要因素。
本文通过引入两个新的运算来解决这个问题:及卷积移位和全连接移位,这两种运算代替乘法,并用按位移位和按位求反。这套神经网络体系结构称为DeepShift模型。
DeepShift模型在CIFAR10数据集上的准确度高达93.6%,在Imagenet数据集上的Top-1/ Top-5准确度高达70.9%/ 90.13%。将所有卷积层和完全连接的层转换为按比特移位的对应层后,对各个知名CNN架构进行了广泛测试,结果发现在某些架构中,Top-1的准确性下降了不到4%,Top-5的准确性下降不到1.5%。
实验在PyTorch框架上进行,训练和运行代码与论文一起呈现,并将在Github上给出相关资源。
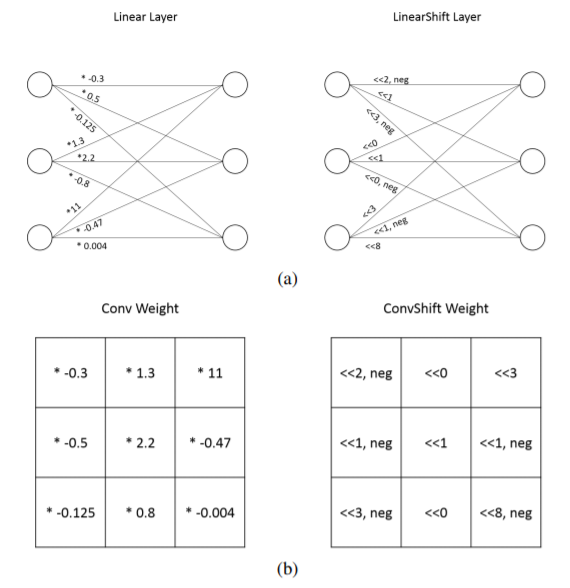
DeepShift原理与结构
如图1所示,本文的目的是用按位移位和位取反来代替乘法。如果输入数字的基本二进制表示形式A为整数或固定点格式,则向左(或右)的逐位移位在数学上等效于将其乘以2的正s(或负s次幂):
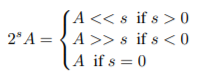
按位移位只能等效于乘以一个正数,因为对于任何s值,2的s次方> 0。但是,在神经网络中,训练必须在其搜索空间中将其乘以负数,尤其是在卷积神经网络中,具有正值和负值的滤波器都有助于检测边界。因此,我们还需要使用求反运算。
求反运算在数学上等效于:
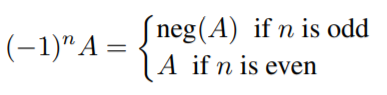
使用PyTorch的AutoGrad工具生成反向传递。为了模拟实际按位移位硬件实现的精度,在应用前向通过之前,LinearShift和ConvShift运算符的输入数据会四舍五入为定点格式精度。
MNIST和CIFAR 10测试结果
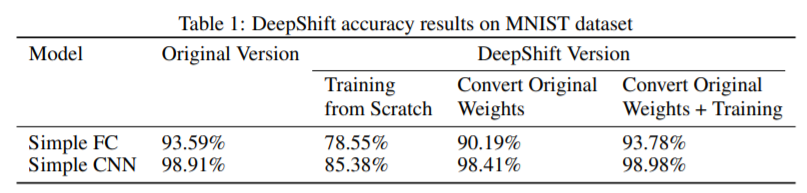
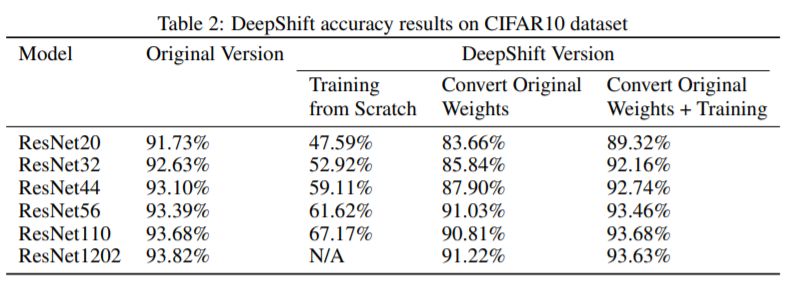
图2 MNIST和CIFAR 10数据集测试结果对比
ImageNet数据集对比测试结果
使用随机梯度下降优化器对模型进行训练,动量为0.9,重量衰减为1×10−4。 使用的损失标准是分类交叉熵。 用于从头开始训练的学习率是0.1,表3中为每个模型指定了用于训练预训练的转换模型的epoch数和学习率。
可以通过查看前几批训练的准确性来手动调整训练每个转换模型的学习率:如果准确性下降到未训练的DeepShift模型以下,或者准确性比未训练的模型还低,则说明权重“无法学习”,因此学习率太高,需要调低。
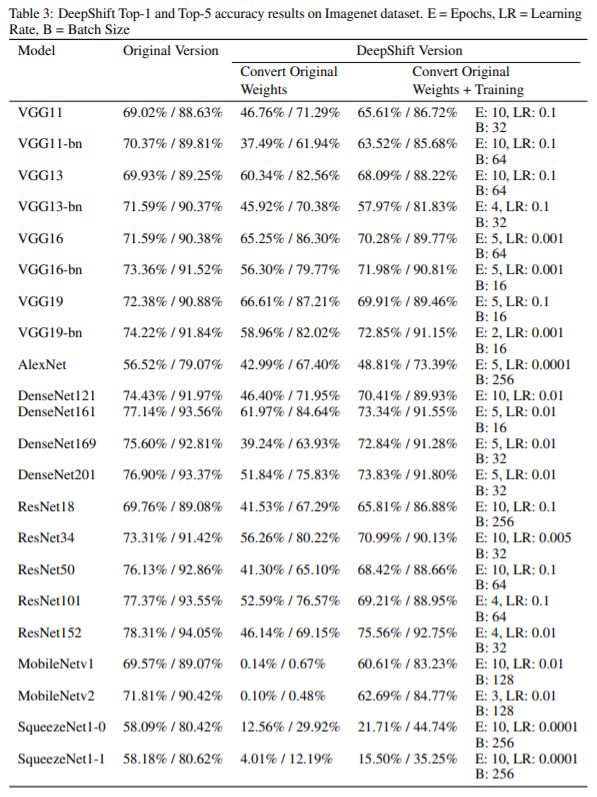
图3 ImageNet数据集测试结果对比
论文链接:
