
中文文本错别字检测以及自动纠错

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
How to use :
run in the terminal : python Autochecker4Chinese.py
You will get the following result :
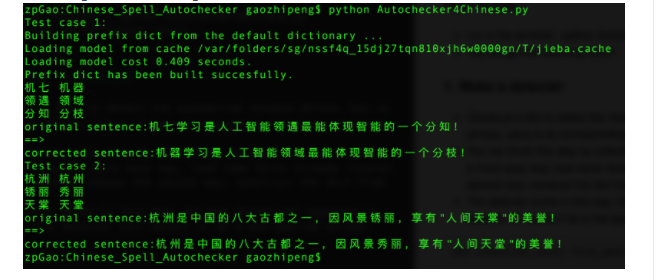
代码及运行教程 获取:
关注微信公众号 datayx 然后回复 纠错 即可获取。
1. Make a detecter
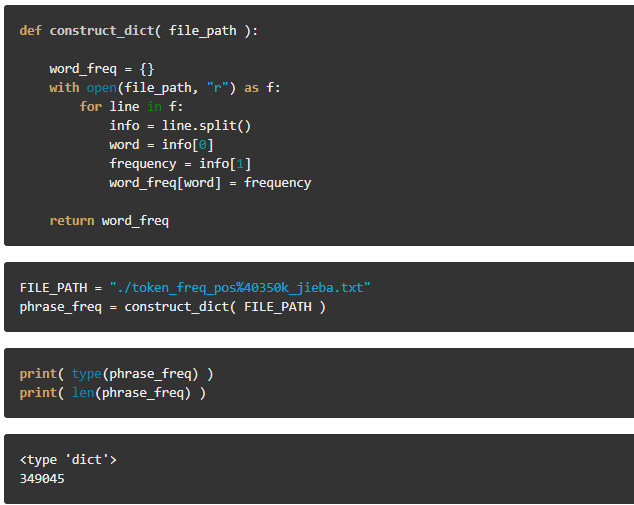
Construct a dict to detect the misspelled chinese phrase,key is the chinese phrase, value is its corresponding frequency appeared in corpus.
You can finish this step by collecting corpus from the internet, or you can choose a more easy way, load some dicts already created by others. Here we choose the second way, construct the dict from file.
The detecter works in this way: for any phrase not appeared in this dict, the detecter will detect it as a mis-spelled phrase.
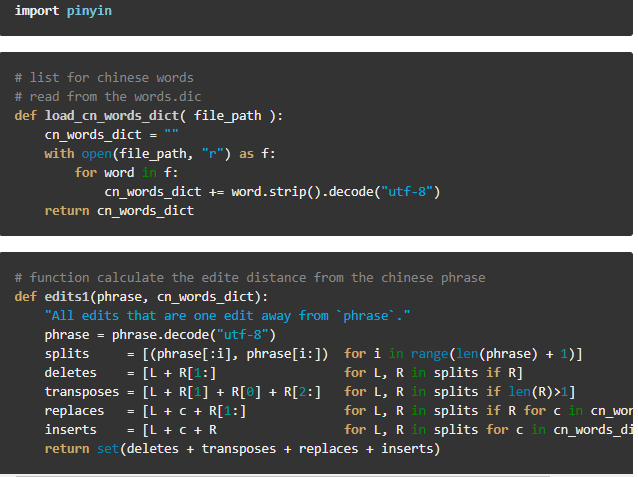
Make an autocorrecter
Make an autocorrecter for the misspelled phrase, we use the edit distance to make a correct-candidate list for the mis-spelled phrase
We sort the correct-candidate list according to the likelyhood of being the correct phrase, based on the following rules:
If the candidate's pinyin matches exactly with misspelled phrase's pinyin, we put the candidate in first order, which means they are the most likely phrase to be selected.
Else if candidate first word's pinyin matches with misspelled phrase's first word's pinyin, we put the candidate in second order.
Otherwise, we put the candidate in third order.
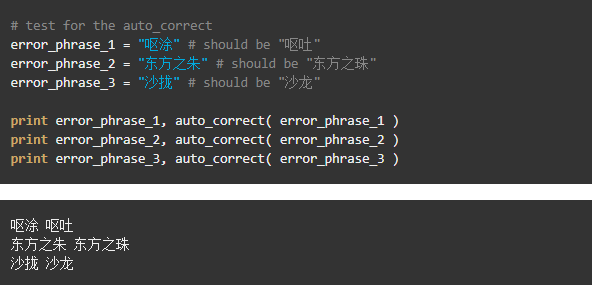
3. Correct the misspelled phrase in a sentance
For any given sentence, use jieba do the segmentation,
Get segment list after segmentation is done, check if the remain phrase exists in word_freq dict, if not, then it is a misspelled phrase
Use auto_correct function to correct the misspelled phrase
Output the correct sentence

阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码