
盘点一个Python网络爬虫过验证码的问题(方法一)
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是皮皮。
一、前言
前几天在Python最强王者群【鶏啊鶏。】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。
下面是他的代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from PIL import Image
import ddddocr
ocr = ddddocr.DdddOcr()
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=options)
# 打开目标网页
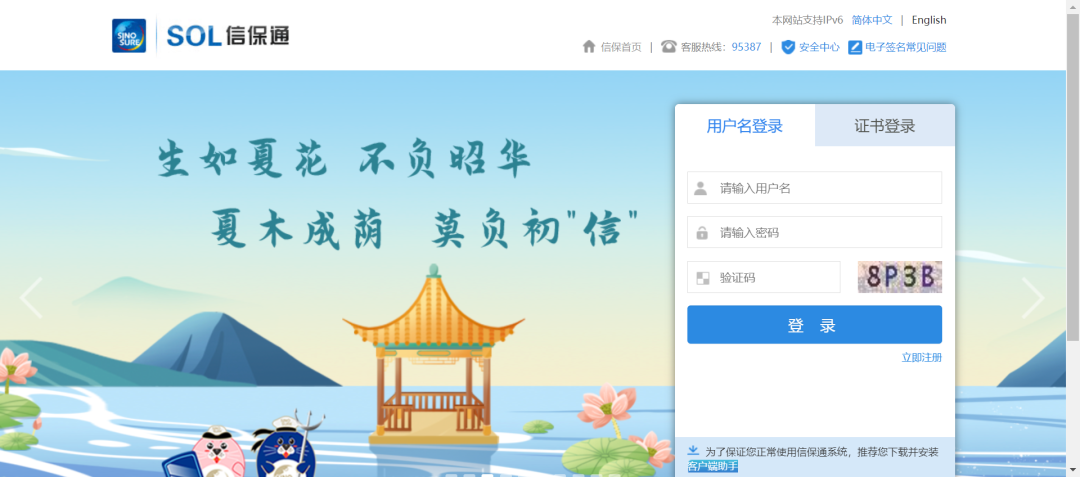
driver.get('https://sol.sinosure.com.cn')
time.sleep(5)
driver.maximize_window()
# 定位验证码图片元素并模拟鼠标悬停以加载图片
yanzhengma = driver.find_element(By.CSS_SELECTOR, '.pass-form-item.pass-form-item-code')
captcha_element = yanzhengma.find_element(By.CSS_SELECTOR, '.pass-label-img')
webdriver.ActionChains(driver).move_to_element(captcha_element).perform()
time.sleep(5)
# 获取验证码图片元素的位置和大小
location = captcha_element.location
size = captcha_element.size
print(location)
print(size)
# 截取整个网页的截图
driver.save_screenshot('screenshot.png')
# 根据验证码图片元素的位置和大小,从整个网页截图中裁剪出验证码图片
left = int(location['x'])
top = int(location['y'])
right = int(location['x'] + size['width'])
bottom = int(location['y'] + size['height'])
captcha_screenshot = Image.open('screenshot.png').crop((left, top, right, bottom))
print(left)
print(top)
print(location)
print(bottom)
# 保存裁剪后的验证码图片,并进行识别
captcha_screenshot.save('captcha.png')
with open('captcha.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print('识别的验证码是:' + res)
基本思路是没啥问题的,确实也是可以拿到对应界面的截图,只不过是验证码的位置截取出现了点偏差,导致验证码没正确识别到。
下面这个代码是获取验证码图片元素的位置和大小:
location = captcha_element.location
size = captcha_element.size
这个部分我看介绍应该是会返回定位的元素位置,我刚刚大致拖拉了一下在裁剪前的定位打印出来确实就已经去了输入密码附近的位置了 但是我定位的元素是验证码的地方,并且我也尝试了先定位验证那个位置的大元素再定位至具体的验证码图片位置 问题依旧。
上面是粉丝的疑惑,下面一起来看看解决办法。
二、实现过程
这里【魏哥】尝试了下代码,但是出现下图报错:
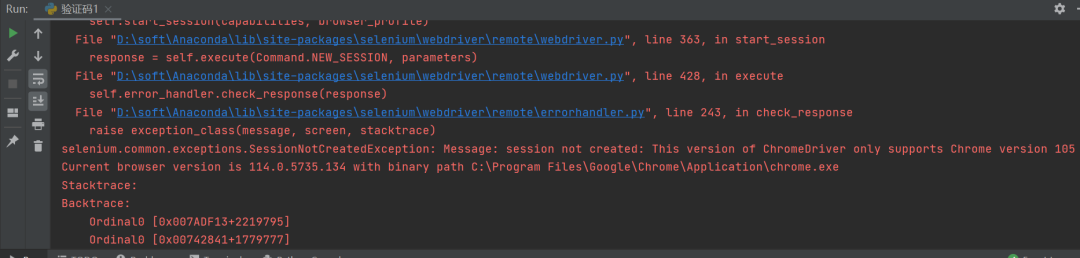
这个报错还是蛮常见的,对于时常使用sel的人来说,这个报错算是家常便饭了,报错的原因是本地浏览器驱动和谷歌浏览器的版本不匹配,需要更换本地浏览器驱动。
关于这个问题的解决方法,就是去网页下载对应浏览器版本的对应驱动,放到本地指定文件夹,确保该文件夹路径有加入环境变量。该问题的解决办法公众号历史文章也有提及,网上的解决教程也一大堆,这里不再赘述。
言归正传,继续回到这个问题的解决办法。这里【甯同学】给了一个思路,直接找到 验证码的图片的url 用requests 请求 验证码的.content 用 ocr.classification(验证码的.content) 就可以了 不用保存图片 在open读取二进制流,代码如下所示:
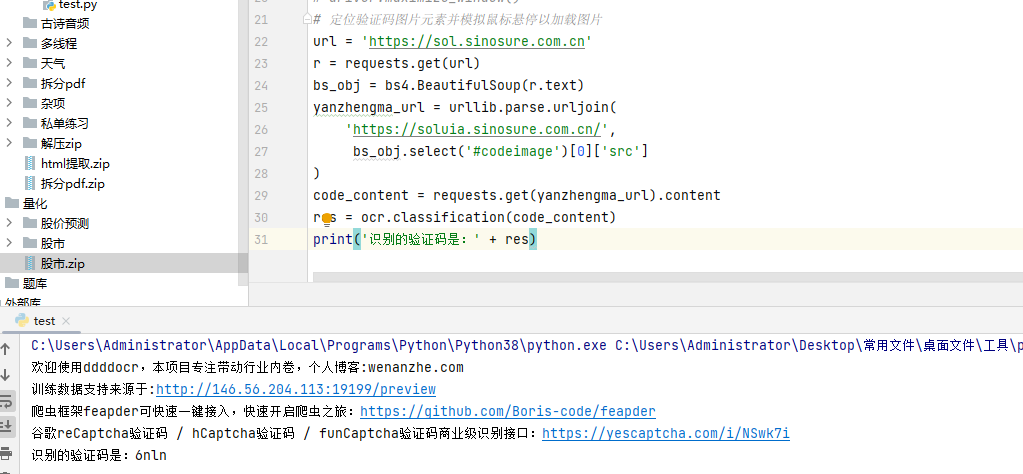
顺利地解决了粉丝的问题,如果对requests和Beautiful还不熟悉的小伙伴,可能接受起来就比较困难一些。
这里只是给出了其中一个方法,另外的一个方法,一起看下一篇文章,敬请期待!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫过验证码的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【鶏啊鶏】提问,感谢【甯同学】、【魏哥】给出的思路和代码解析,感谢【Ineverleft】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~