
数据分析终极一问:多影响因素下,到底咋归因?!
数据分析领域有几个经典的终极难题。多影响因素归因,绝对是其中最让人头大的。特别是临近年底,品牌、售后、客服、供应链、运营、产品、商品管理都会跑来,问:“今年业绩不错呀,那么问题便来了:今年公司多赚的10个亿,到底几个亿归功于品牌,到底几个亿归功于供应……请量化分析一下,谢谢”。
那么,到底该怎么分析呢?今天我们详细讲解一下。
为啥这个问题是终极难题,只要做一个实验,马上便知道。
同学们可以亲自试试哦
第一步:请闭上眼睛
第二步:回忆淘宝里最近买的一件商品
第三步:在脑海里回忆该商品的名称、包装、价格、品牌、客服小妹声音……
第四步:睁开眼,告诉自己:我为这个商品付费的XXX钱,其中有X%是付给名称,X%付给包装,X%付费给商品上blingbling的广告,X%付给快递叔叔……
答得出来不?
不但很难答出来,估计很多同学连最近买的是啥都不记得了。
消费者不是所有消费都理性。
消费者不是所有商品都重视。
商家提供的品牌、服务、产品本身就是一个整体。
因此站在消费者角度,这个问题从源头上就不成立。特别是啤酒瓜子矿泉水一类的快消类产品。价格低,消费频次高,冲动消费多,心情好了就买点,心情不好了也买点,因此很难讲清楚。大宗耐用品,比如房子、车子可能思考的多一些,有一定概率区分出来,但是仍然很难量化到每个因素的得分(如果怀疑这点的,想象你结婚那一刻有多纠结,就秒懂了,哈哈)。
那么问题来了:为啥明知道分不清楚,各个部门还一而再、再而三要求分家呢?
这就触及到问题的本质:大家的屁股坐在哪里。
表象上看,多影响因素归因,难在很难拆解数据。
本质上看,多影响因素归因,只是部门间分赃不均的结果。
每个部门都太急于证明自己的价值,总想努力跟业绩指标挂上联系。
特别在年底,要为部门争取奖金,要为明年争取预算,分家的冲动就更高。
因此,多影响因素归因,本质上是在衡量部门价值,这才是核心难点。
很多同学会忽视这个核心问题,用一些简单的数据方法处理。比如:把各个部门的费用设为x,把业绩设为y然后怼一个线性回归模型出来。然后把各个参数的系数视为贡献大小。且不说,这么干,首先完全误会了回归模型的含义;其次,也没有考虑分类变量和连续变量的问题。单纯就结果本身,也会被人喷死。
比如,算出来销售的系数是2,供应链的系数是1,那明年多找2倍的销售,却只提供1倍的商品,还能有这个销售业绩吗?肯定不可能啊,有枪没子弹啊!部门之间分工合作,不是简单的1+1=2的关系,这是常识。因此强行割裂部门间联系,把不同分类的部门拉在一起评价,是注定要扑街的。
因此,破局思路,在于从一开始,就应该直接否掉这种一条公式打天下的想法。从部门工作性质出发,建立科学的衡量机制,从而有效化解这种立功焦虑。
想破局,首先得分清各个部门的工作类型与贡献方式(如下图)
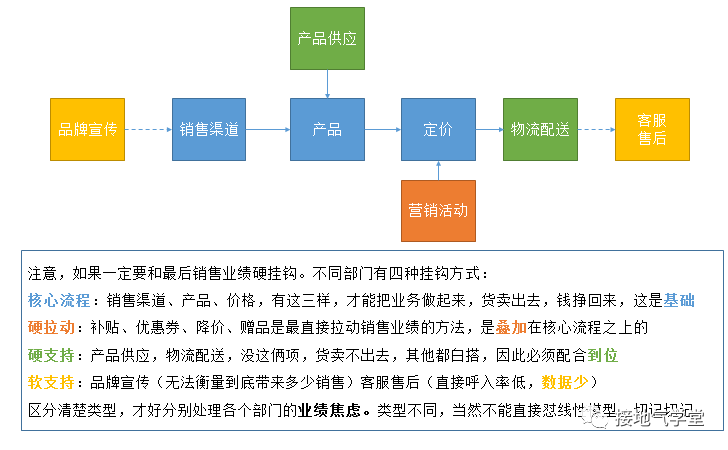
之后,就可以分门别类进行分析考察。
软支持类:放弃直接关联销售业绩,按需分配。
软支持的核心问题,在于不能自证清白。对于品牌宣传而言,即使所有宣传都带连接,导流到购买页面,也无法证明到底用户购买是多大因为品牌,甚至这些年爆款打法、网红带货,都在可以弱化品牌,突出产品功能和粉丝效应。况且,至少6成以上的品牌宣传,根本连带货链接都没有(比如上市前的宣传),就更无从谈起了。客服、售后也同理,虽然顾客找上门来的时候,这两者服务很重要。但是主动发起的客户比例少,因此很难关联整体业绩。
这种不做不行,做了说不清楚效果的事,最好直接按整体业绩比例分配资源,考核自身的效果,而不是非要强行关联销售业绩。
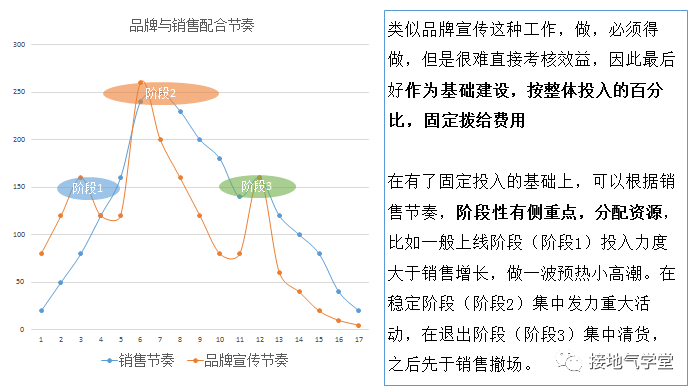
比如根据产品生命周期/时间,配置宣传力度(如下图)宣传能达成足够市场认知,覆盖足够人数(考核点击、转发、阅读数等等)即完成任务。
比如客服、售后。根据业务总量分配资源和人力。考核本身服务满意度,服务覆盖率,从呼叫到响应的速度,严重投诉/风险事件的应对速度,等等。做好本职工作及完成任务。
硬支持类:考核。
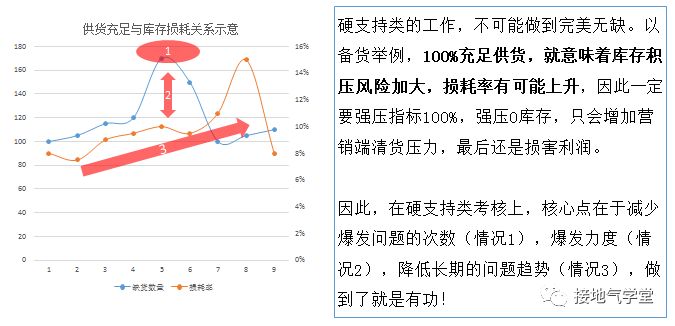
硬支持类的考核就简单清晰很多:供给到位,损耗降低。并且追求的是峰值控制与长期水平的下降。太过计较一城一地得失,反而容易定出来很死板的流程,搞出很多乌龙(如下图)
硬拉动类:引入ABtest机制,提前预设目标。
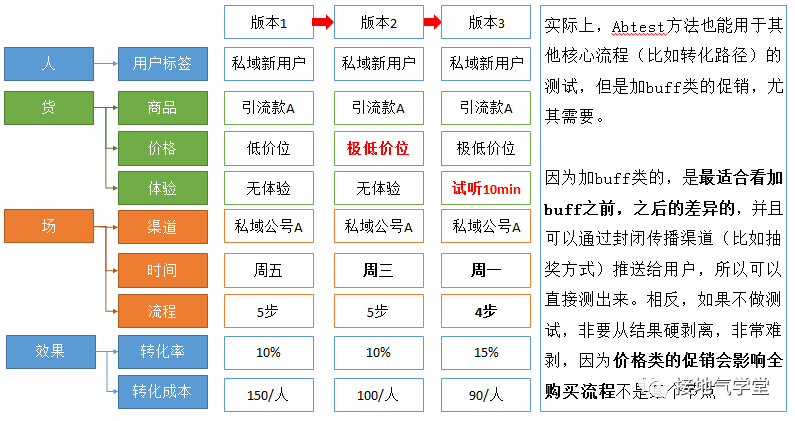
硬拉动类,属于叠加buff的做法,因此必须事先设好控制变量,否则混在一堆因素里,事后根本无法拆分。比如事先设定好拉动的总目标,事先测试方案效果,事中余留参照组,采集过程数据,这样才能在事后做好区分。硬拉动类是可以评估的,问题总是出在:事先不做工作,事中不留参照,不踩数据。啥都没有,事后能分析出来就见鬼了。
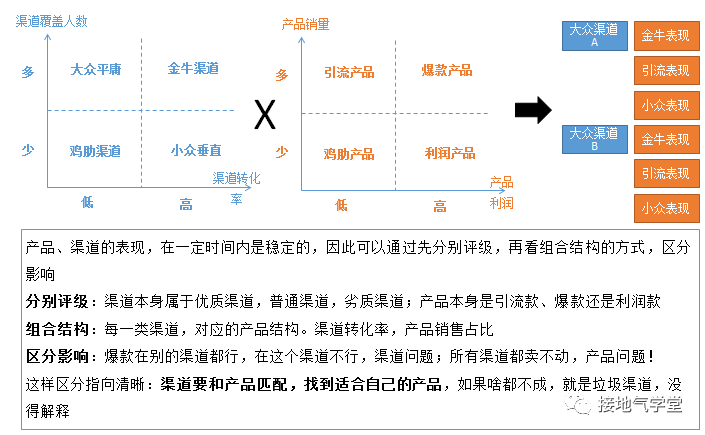
核心流程:建立分级机制,深入分析影响。
核心流程里,销售和产品互怼的事也很常见,但是这种互怼是可以分析出,到底过错在谁那边的。只要建立好分级机制,对渠道质量、商品属性进行打标签分析,监控过程转化率,是可以做深入分析的,因此核心流程尽量多做分析,不留扯皮空间(如下图)
以上只是理想状态下的建议,实际开工:
● 总有人想争取更多资源,大喊:“品效合一!”“心智资源!”
● 总有人认为客服售后没必要,今年再扣他点费用?(从而引发服务部门的奋起反击“老子也有贡献!”)
● 总有人喜欢夸大自己贡献,促销活动效益写的巨高,甚至比自然销量还高。
● 总有人怕被追究责任,拼命往:没有促销!没有支持!产品不给力上推责任。
所以有关“到底每个部门贡献多少,能不能具体到每一块钱里几毛几分是谁来的”的议题,永远不会停下来。
加之,总有新入行的数据分析师,认为只要怼几个数据进线性回归或者因子分析模型,就能算个参数出来让每个部门满意。所以这种来来回回扯皮的事,还会延续很多很多年,哈哈哈。
类似的数据分析千古难题,还有很多:
● 为什么ABtest中实验有效,投产没效,到底怎么测得准!
● 自然增长率要怎么计算,才是全宇宙最公平合理的!
● 用户心智资源的开发与认知深度的变化,如何衡量!
● 销售预测,到底怎么才能预测100%精准!
● ……
每一个问题,都是表面看似数据分析,背后是人心贪婪,推过拦功。业绩好了就说是自己做的,业绩不好就甩给外部各自因素,内部各种无法量化的因素,以图自保。实在不行就说是数据分析能力不行,你咋不早点预测出来呢!做数据分析的同学们,要对这些问题有足够清晰的认知,不要轻易上当哦。就比如看似最简单的:自然增长率怎么算,到底咋算才能让业务部门服气呢?