
终于有人把网络爬虫讲明白了
导读:人们正在以前所未有的速度转向互联网,我们在互联网上所做的很多行为产生了大量的“用户数据”,比如微博、购买记录等。

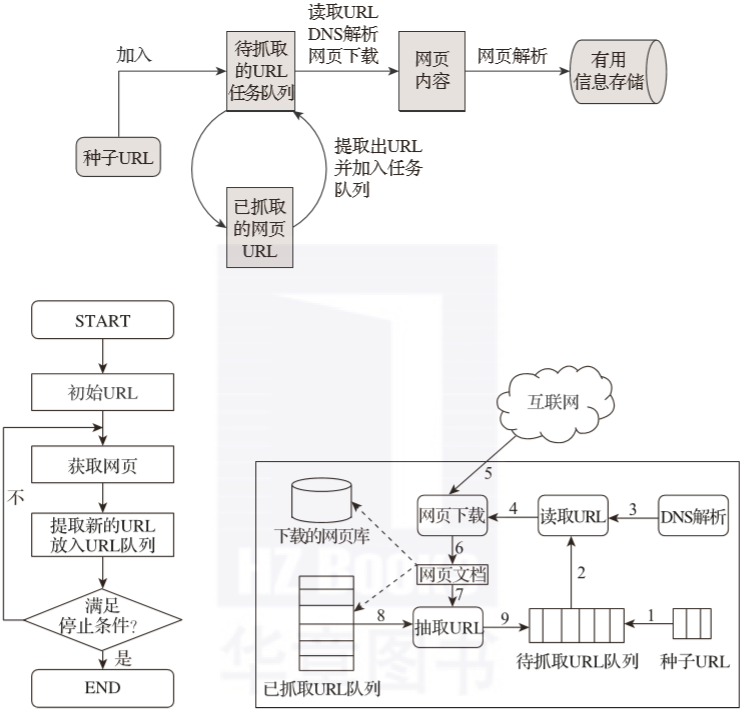
首先在互联网中选出一部分网页,以这些网页的链接地址作为种子URL; 将这些种子URL放入待抓取的URL队列中,爬虫从待抓取的URL队列依次读取; 将URL通过DNS解析; 把链接地址转换为网站服务器对应的IP地址; 网页下载器通过网站服务器对网页进行下载; 下载的网页为网页文档形式; 对网页文档中的URL进行抽取; 过滤掉已经抓取的URL; 对未进行抓取的URL继续循环抓取,直至待抓取URL队列为空。
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。 Web页面按存在方式可以分为表层网页(surface Web)和深层网页(deep Web,也称invisible Web pages或hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的Web页面。 深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。


3月25日20:00
评论