
究极缝合怪 | Pulsar核心概念和特性解读

Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
简介
Pulsar 是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。Pulsar 最初由 Yahoo 开发,目前由 Apache 软件基金会管理。
Pulsar 的关键特性如下:
Pulsar 的单个实例原生支持多个集群,可跨机房在集群间无缝地完成消息复制。
极低的发布延迟和端到端延迟。
可无缝扩展到超过一百万个 topic。
简单的客户端 API,支持 Java、Go、Python 和 C++。
支持多种 topic 订阅模式(独占订阅、共享订阅、故障转移订阅)。
通过 Apache BookKeeper 提供的持久化消息存储机制保证消息传递 。
由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。
基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如S3、GCS)中。
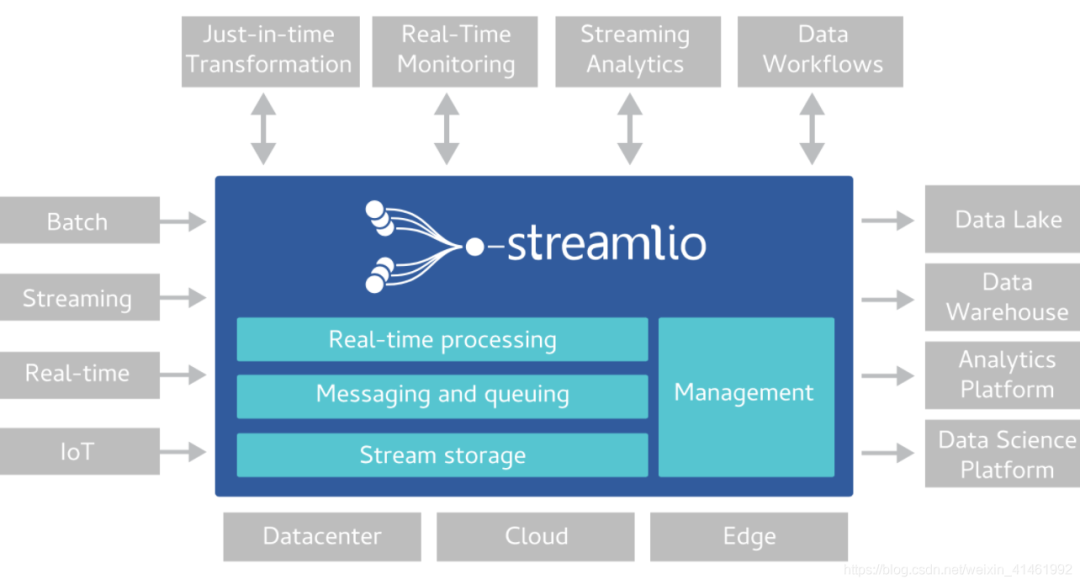
集群架构
单个 Pulsar 集群由以下三部分组成:
一个或者多个 broker 负责处理和负载均衡 producer 发出的消息,并将这些消息分派给 consumer;Broker 与 Pulsar 配置存储交互来处理相应的任务,并将消息存储在 BookKeeper 实例中(又称 bookies);Broker 依赖 ZooKeeper 集群处理特定的任务,等等。
包含一个或多个 bookie的 BookKeeper 集群负责消息的持久化存储。
一个Zookeeper集群,用来处理多个Pulsar集群之间的协调任务。ZooKeeper 只用于为 broker 和 bookie 存储元数据。
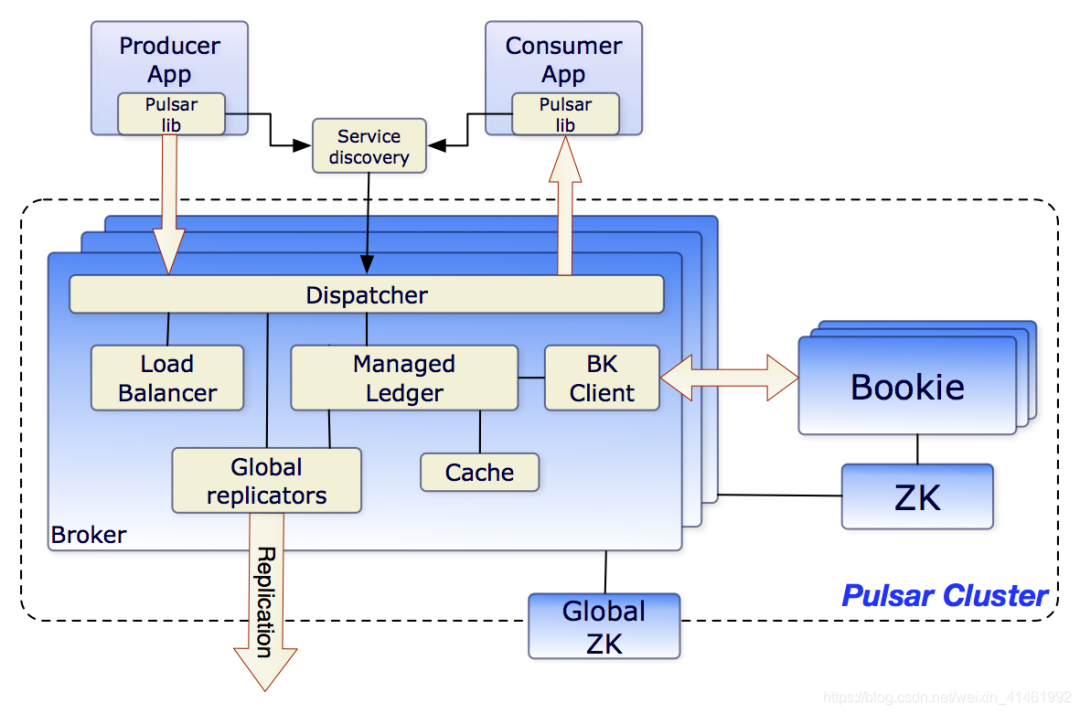
Brokers
Pulsar的broker是一个无状态组件, 主要负责运行另外的两个组件:
http服务器,可用于接收Rest API请求,并负责生产者连接生产消息,消费者连接消费消息。
一个调度分发器,它是异步的TCP服务器,通过自定义二进制协议应用于所有相关的数据传输。
Apache BookKeeper
Pulsar用Apache BookKeeper作为持久化存储。BookKeeper是一个分布式的预写日志(WAL)系统,BookKeeper节点(bookie)存储消息与游标。
以pulsar-manager的某个topic为例:
Ledgers
Ledger是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个BookKeeper存储节点(就是Bookies)的写入。Ledger的条目会被复制到多个bookies。Ledgers本身有着非常简单的语义:
Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,这个ledger只会以只读模式打开。
最后,当ledger中的条目不再有用的时候,整个legder可以被删除(ledger分布是跨Bookies的)。
Ledger读一致性
BookKeeper的主要优势在于他能在有系统故障时保证读的一致性。由于Ledger只能被一个进程写入(之前提的写入器进程),这样这个进程在写入时不会有冲突,从而写入会非常高效。在一次故障之后,ledger会启动一个恢复进程来确定ledger的最终状态并确认最后提交到日志的是哪一个条目。在这之后,能保证所有的ledger读进程读取到相同的内容。
Managed ledgers
managed ledger即消息流的抽象,有一个写入器进程不断在流结尾添加消息,并且有多个cursors 消费这个流,每个cursor有自己的消费位置。

日志存储
在BookKeeper中, journal files包含BookKeeper transaction logs. 在更新到ledger之前,bookie需要确保描述这个更新的事务被写到持久(非易失)存储上面。在bookie启动和旧的日志文件大小达到上限(由journalMaxSizeMB参数配置)的时候,新的日志文件会被创建。
Kafka对比
组件
Kafka 采用单片架构模型,将服务与存储相结合。而Pulsar则采用了多层架构,可以在单独的层内进行管理。Pulsar中的broker在一个层上进行计算,而 bookie 则在另一个层上管理有状态存储。
存储
Pulsar的多层架构影响到了其存储数据的方式。Pulsar将topic 分区划分为分片,然后将这些分片存储在 Apache BookKeeper的存储节点上,以提高性能、可伸缩性和可用性。
Pulsar对日志进行分段,从而避免了拷贝大块的日志。通过BookKeeper, Pulsar将日志分段分散到多台不同的服务器上。也就是说,日志不会保存在单台服务器上,任何一台服务器都不会成为整个系统的瓶颈。这使故障处理和扩容更加简单,只需要加入新的服务器,而无需进行再均衡处理。
Pulsar消息只有被所有订阅消费后才会删除,不会丢失数据。Kafka根据设置的数据保留过期时间,过期后删除。同样,Pulsar也支持设置保留时间(TTL)。
无状态
Kafka不是无状态的,每个 broker 都包含了分区的所有日志,如果一个 broker宕机,不是所有broker都可以接替它的工作。如果工作负载太高,也不能随意添加新的 broker 来分担,而是必须与持有其分区副本的 broker 进行状态同步。
在 Pulsar 架构中,broker是无状态的。但是完全无状态的系统无法持久化消息,所以Pulsar 不是依靠 broker 来实现消息持久化的。在 Pulsar 架构中,数据的分发和保存是相互独立的。broker从生产者接收数据,然后将数据发送给消费者,但数据保存在 BookKeeper 中。
Pulsar 的 broker是无状态的,所以如果工作负载很高,可以直接添加新的 broker,快速接管工作负载。
Exactly-Once 处理
目前,Pulsar 通过 broker 端去重支持exactly-once producer。
生产者
生产者连接到主题并生产消息到pulsar的broker上。
pulsar的broker处理这条消息。
发送模式
Producer可以以同步(sync) 或 异步(async) 的方式发布消息到broker。
同步发送到broker,如果没broker没有返回ack,则该条消息视为发送失败。Producer将把消息放于阻塞队列中,并立即返回 然后,客户端将在后台将消息发送给 broker。如果队列已满(最大大小可配置),则调用 API 时,producer可能会立即被阻止或失败,具体取决于传递给producer 的参数。访问模式
访问模式

批量处理
当批量处理启用时,producer 会在单个请求中积累并发送一批消息。批量处理的量大小由最大消息数和最大发布延迟定义。因此,积压数量是分批处理的总数,而不是信息总数。
在 Pulsar 中,批次被跟踪并存储为单个单元,而不是单个消息。Consumer 将批量处理的消息拆分成单个消息。但即使启用了批量处理,也始终将计划中的消息(通过 deliverAt 或者 deliverAfter 进行配置) 作为单个消息发送。
一般来说,当 consumer 确认了一个批的所有消息,该批才会被认定为确认。这意味着当发生不可预料的失败、否定的确认(negative acknowledgements)或确认超时,都可能导致批中的所有消息都被重新发送,即使其中一些消息已经被确认了。
维护批量索引的确认状态并跟踪每批索引的确认状态,以避免向 consumer发送已确认的消息。当某一批消息的所有索引都被确认时,该批消息将被删除。
默认情况下,批量索引是默认关闭的(acknowledgmentAtBatchIndexLevelEnabled=false),可以在broker配置中开启。启用批量索引确认将会导致更多内存开销
分块
启用分块(chunking),需要注意下面说明:
批量处理不能和分块同时启用 分块只支持persisted topic 分块只支持exclusive和failoversubscription modes.
当启用分块(chunking) 时(chunkingEnabled=true) ,如果消息大小大于允许的最大发布有效载荷大小,则 producer 将原始消息分割成分块的消息,并将它们与块状的元数据一起单独和按顺序发布到broker。在 broker 中,分块的消息将和普通的消息以相同的方式存储在 Managed Ledger 上。唯一的区别是,consumer需要缓冲分块消息,并在收集完所有分块消息后将其合并成真正的消息。Managed Ledger上的分块消息可以和普通消息交织在一起。如果 producer 未能发布消息的所有分块,则当 consumer 未能在过期时间(expire time) 内接收所有分块时,consumer 可以过期未完成的分块。默认情况下,过期时间设置为1小时。
Consumer会缓存收到的块状消息,直到收到消息的所有分块为止。然后 consumer 将分块的消息拼接在一起,并将它们放入接收器队列中。客户端从接收器队列中消费消息。一旦consumer使用整个大消息并确认,consumer 就会在内部发送与该大消息关联的所有分块消息的确认。You can set the maxPendingChunkedMessage parameter on the consumer. 当达到阈值时,consumer 通过静默确认未分块的消息或通过将其标记为未确认,要求 broker稍后重新发送这些消息。
分块为例:
处理一个 producer 和一个订阅 consumer 的分块消息
如下图所示,当生产者向主题发送一批大的分块消息和普通的非分块消息时。假设生产者发送的消息为 M1,M1 有三个分块 M1-C1,M1-C2 和 M1-C3。这个broker在其管理的ledger里面保存所有的三个块消息,然后以相同的顺序分发给消费者(独占/灾备模式)。消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息M1,发送给处理进程。
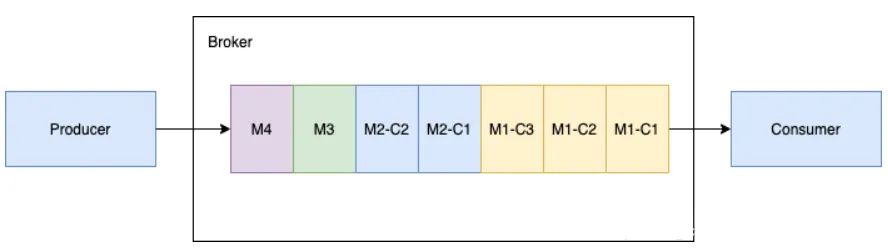
多个生产者和一个生产者处理块消息
当多个生产者发布块消息到单个主题,这个 Broker在同一个 Ledger里面保存来自不同生产者的所有块消息。如下所示,生产者1发布的消息 M1,M1 由 M1-C1, M1-C2 和 M1-C3 三个块组成。生产者2发布的消息 M2,M2 由 M2-C1, M2-C2 和 M2-C3 三个块组成。这些特定消息的所有分块是顺序排列的,但是其在ledger 里面可能不是连续的。这种方式会给消费者带来一定的内存负担。因为消费者会为每个大消息在内存开辟一块缓冲区,以便将所有的块消息合并为原始的大消息。
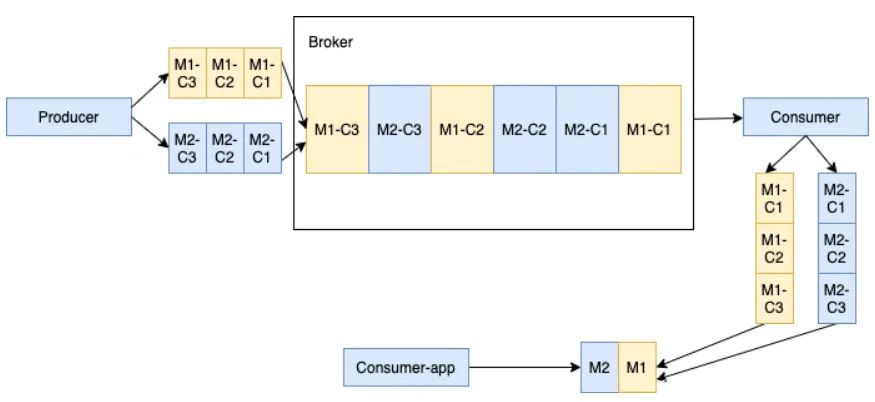
消费者
Consumer 向 broker 发送消息流获取申请(flow permit request)以获取消息。在Consumer端有一个队列,用于接收从 broker推送来的消息。你能够通过receiverQueueSize参数配置队列的长度 (队列的默认长度是1000) 每当 consumer.receive() 被调用一次,就从缓冲区(buffer)获取一条消息。
接收模式
可以通过同步(sync) 或者异步(async)的方式从brokers接受消息。
监听
客户端提供listener的实现接口给消费者,例如,Java Client提供了MessageListener接口。在这个接口中,一旦接受到新的消息,received方法将被调用。
MessageListener myMessageListener = (consumer, msg) -> {
try {
System.out.println("Message received: " + new String(msg.getData()));
consumer.acknowledge(msg);
} catch (Exception e) {
consumer.negativeAcknowledge(msg);
}
}
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.messageListener(myMessageListener)
.subscribe();
确认
当消费者成功的消费了一条消息,这个消费者会发送一个确认信息给broker。这个消息时是永久保存的,只有在收到订阅者消费成功的消息确认后才会被删除。
如果希望消息被 Consumer 确认后仍然保留下来,可配置 消息保留策略实现。
对于批量处理来说,当某一批消息的所有索引都被确认时,该批消息将被删除。
消息保留策略
Pulsar有两个特性,让你可以覆盖上面的默认行为。
Message retention enables you to store messages that have been acknowledged by a consumer(即保留)
Message expiry enables you to set a time to live (TTL) for messages that have not yet been acknowledged(即过期)
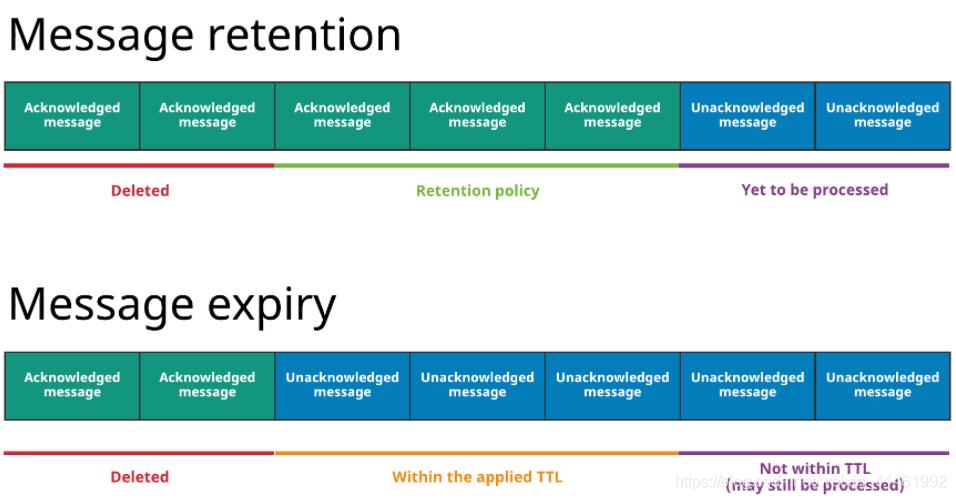
图中上面的是消息存留,存留规则会被用于某namespace下所有的topic,指明哪些消息会被持久存储,即使已经被确认过。没有被留存规则覆盖的消息将会被删除。Without a retention policy, all of the acknowledged messages would be deleted.
图中下面的是消息过期,有些消息即使还没有被确认,也被删除掉了。因为根据设置在namespace上的TTL,他们已经过期了。(例如,TTL为5分钟,过了十分钟消息还没被确认)
Message retention and expiry · Apache Pulsar
在Pulsar中,你有两种方式在命名空间的级别去修改这种行为:
你可以通过设置消息保留策略持久化存储不在 backlog 内的消息(因为他们已经在每个现有的订阅上被确认,或者并没有被订阅)。
可以通过设置 time to live(TTL),设置消息在指定的时间内不被确认的话,自动确认。
broker参数设置
可以通过以下两个参数来配置实例级别的消息保留策略:
# Default message retention time
defaultRetentionTimeInMinutes=0
# Default retention size
defaultRetentionSizeInMB=0
默认情况下,这两个参数都设置为 0。
设置保留策略
有三种形式设置:
使用set-retention子命令并指定命名空间,使用-s/--size参数指定大小限制,使用-t/--time参数指定时间限制。
POST /admin/v2/namespaces/:tenant/:namespace/retention
Java程序中设置
int retentionTime = 10; // 10 minutes
int retentionSize = 500; // 500 megabytes
RetentionPolicies policies = new RetentionPolicies(retentionTime, retentionSize);
admin.namespaces().setRetention(namespace, policies);
取消确认
当消费者在某个时间没有成功的消费某条消息,消费者想重新消费到这条消息,这个消费者可以发送一条取消确认消息到 broker,broker 会将这条消息重新发给消费者。
消息取消确认也有单条取消模式和累积取消模式 ,这依赖于消费者使用的订阅模式。
在独占消费模式和灾备订阅模式中,消费者仅仅只能对收到的最后一条消息进行取消确认。
确认超时
如果消息没有被成功消费,你想去让 broker自动重新交付这个消息, 你可以采用未确认消息自动重新交付机制。客户端会跟踪 超时 时间范围内所有未确认的消息。并且在指定超时时间后会发送一个 重发未确认的消息请求到 broker。
Note If batching is enabled, other messages and the unacknowledged messages in the same batch are redelivered to the consumer.
Note Prefer negative acknowledgements over acknowledgement timeout. 确认取消是以更高的精度在控制单条消息的重新传递。当消息处理时间超过确认超时时间时,要避免无效的消息重传。
死信主题
死信主题使您能够在使用者无法成功地使用某些消息时使用新消息。在此机制中,无法使用的消息存储在单独的主题中,称为死信主题。您可以决定如何处理死信主题中的消息。
在java client例子中
Consumer consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();
默认的topic名称为:
--DLQ
也可以自己指定:
Consumer consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.deadLetterTopic("your-topic-name")
.build())
.subscribe();
Topic
pulsar的topic命名是符合良好结构的URL:
{persistent|non-persistent}://tenant/namespace/topic

命名空间(namespace)
命名空间是租户内部逻辑上的命名术语。可以通过admin API在租户下创建多个命名空间。例如,包含多个应用程序的租户可以为每个应用程序创建单独的命名空间。Namespace使得程序可以以层级的方式创建和管理topic
例如:Topic my-tenant/app1 ,它的namespace是app1这个应用,对应的租户是 my-tenant。你可以在namespace下创建任意数量的topic。
订阅
Pulsar 中有四种订阅模式: 独占,共享,灾备和key共享 下图展示了这三种模式:
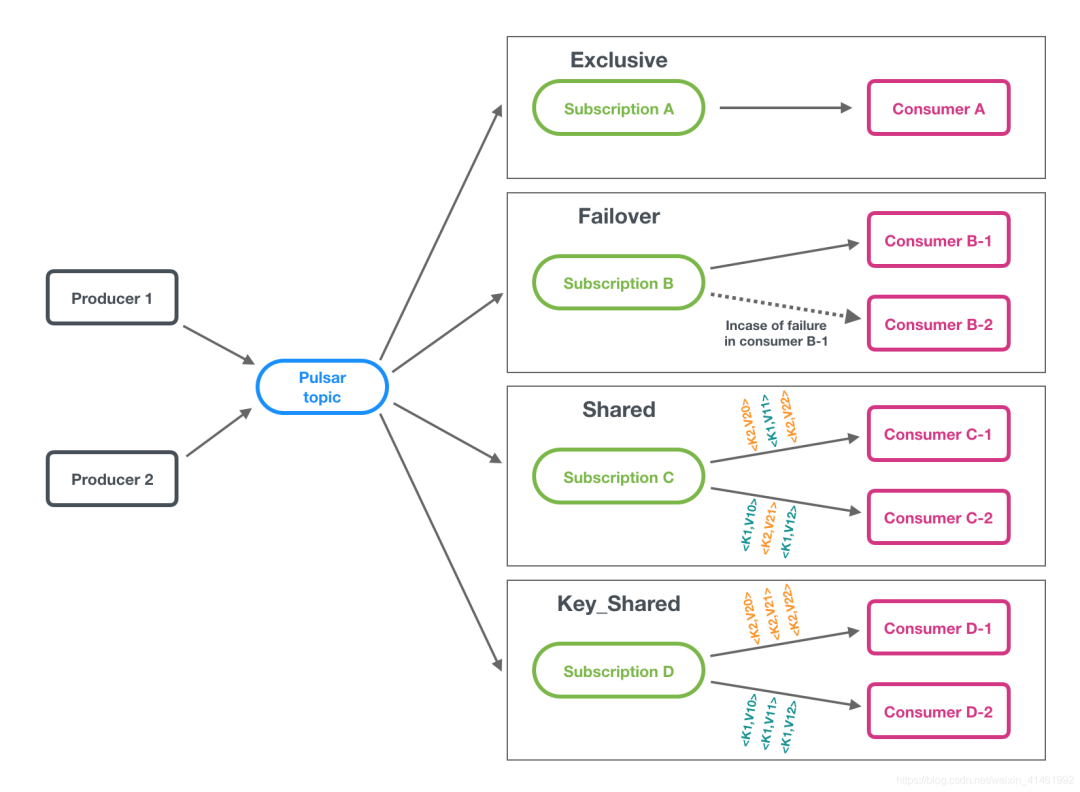
Pulsar提供了灵活的消息模型,支持以下订阅类型:

多主题订阅
当consumer订阅pulsar的主题时,它默认指定订阅了一个主题,例如:
// 通过明确指定的topic列表
persistent://public/default/my-topic
// 当使用正则匹配订阅多个主题的时候,所有的主题必须是在同一个命名空间里面的。
persistent://public/default/finance-.*
当订阅多个主题的时候,Pulsar 客户端将自动调用 Pulsar API找到符合匹配规则的主题列表,然后订阅这些主题。如果此时有暂不存在的主题,那么一旦这些主题被创建,消费者会自动订阅这些主题。
java client example.
import java.util.regex.Pattern;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.PulsarClient;
PulsarClient pulsarClient = // Instantiate Pulsar client object
// Subscribe to all topics in a namespace
Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default/.*");
Consumer allTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(allTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
// Subscribe to a subsets of topics in a namespace, based on regex
Pattern someTopicsInNamespace = Pattern.compile("persistent://public/default/foo.*");
Consumer someTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(someTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
分区 topic
普通的主题仅仅被保存在单个 broker中,这限制了主题的最大吞吐量,分区主题实际是通过在底层拥有 N 个内部主题来实现的,这个 N 的数量就是等于分区的数量。当向分区的topic发送消息,每条消息被路由到其中一个broker。Pulsar自动处理跨broker的分区分布。
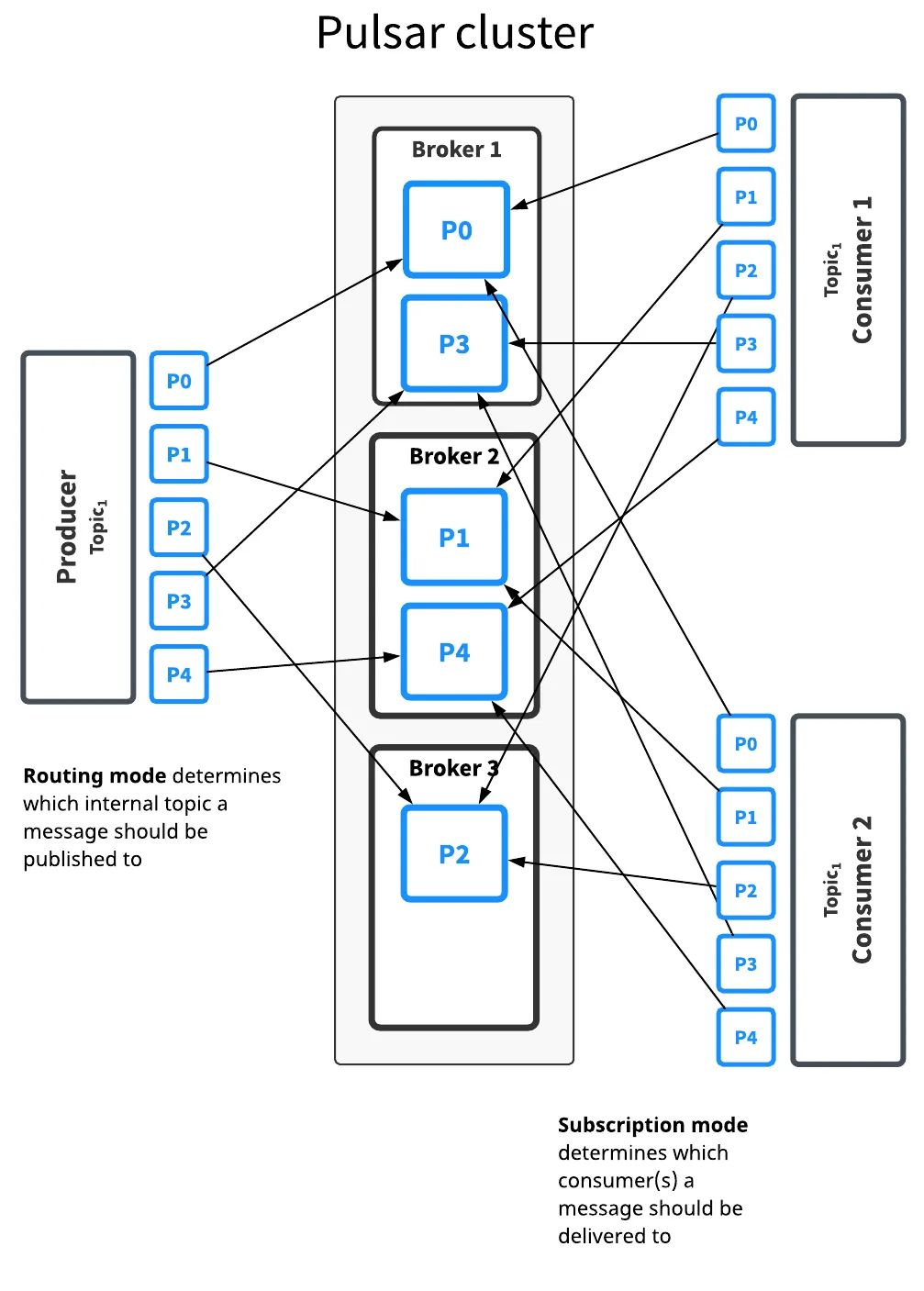
路由模式
有三种 MessageRoutingMode 可用:

顺序保证
当使用 SinglePartition或者RoundRobinPartition模式时,如果消息有key,消息将会被路由到匹配的分区,这是基于ProducerBuilder 中HashingScheme 指定的散列shema。
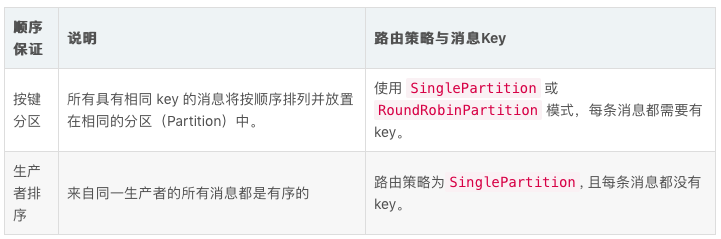
非持久topic
一般,pulsar会持久化所有未被消费的消息数据到bookkeep bookies中,以保证持久性主题上的消息数据可以在 broker 重启和订阅者故障转移之后继续存在。
Pulsar也提供了非持久topic。非持久topic的消息不会被保存在硬盘上,只存活于内存中。当使用非持久topic分发时,杀掉Pulsar的broker或者关闭订阅者,此topic( non-persistent)上所有的瞬时消息都会丢失,意味着客户端可能会遇到消息缺失。
非持久性主题具有这种形式的名称:
non-persistent://tenant/namespace/topic
所以,非持久topic,消息数据仅存活在内存。如果broker挂掉或者因其他情况不能从内存取到,你的消息数据就可能丢失。
默认非持久topic在broker上是开启的。你可以通过broker的配置关闭。
消息去重
消息去重保证了一条消息只能在 Pulsar服务端被持久化一次。消息去重是一个Pulsar可选的特性,它能够阻止不必要的消息重复,它保证了即使消息被消费了多次,也只会被保存一次。
下面为官网配置链接:
Message deduplication · Apache Pulsar
消息延迟传递
延时消息功能允许你能够过一段时间才能消费到这条消息,而不是消息发布后,就马上可以消费到
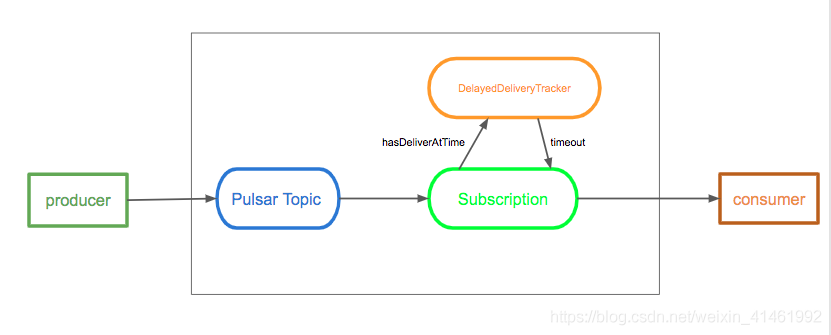
Broker 保存消息是不经过任何检查的。当消费者消费一条消息时,如果这条消息是延时消息,那么这条消息会被加入到DelayedDeliveryTracker当中。订阅检查机制会从DelayedDeliveryTracker获取到超时的消息,并交付给消费者。
Broker
默认情况下启用延迟消息传递。您可以在代理配置文件中更改它:
# Whether to enable the delayed delivery for messages.
# If disabled, messages are immediately delivered and there is no tracking overhead.
delayedDeliveryEnabled=true
# Control the ticking time for the retry of delayed message delivery,
# affecting the accuracy of the delivery time compared to the scheduled time.
# Default is 1 second.
delayedDeliveryTickTimeMillis=1000
生产者(Producer)
下面是 Java 当中生产延时消息一个例子:
// message to be delivered at the configured delay interval
producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();
租户
成为一个多租户系统是 Pulsar 最初设计理念的一部分。并且,Pulsar 提出了租户的概念。租户可以跨集群分布,每个租户都可以有单独的认证和授权机制。租户也是存储配额、消息TTL和隔离策略的管理单元。
Pulsar 的多租户性质主要体现在 topic 的 URL 中:
persistent://tenant/namespace/topic
Pulsar通过租户和命名空间这两个关键概念支持多租户。
Pulsar为指定的多个租户配置了合适的容量。
命名空间是一个术语,指租户的管理单元。命名空间上设置的配置策略适用于在该命名空间中创建的所有 topic。租户可以使用REST API和 [pulsar-admin CLI 工具来创建多个命名空间。例如,包含多个应用程序的租户可以为每个应用程序创建单独的命名空间。
命名空间更改事件和主题级策略
Pulsar是一个多租户的事件流处理系统。管理员可以通过设置不同层次的策略来管理租户和命名空间。然而,有些策略,例如数据保留策略和数据存储配额策略,仅仅只能在命名空间级别设置。在许多使用场景中,用户需要对主题设置对应的策略。命名空间更改事件提供了一个简单有效的方式去修改主题级别的策略。在这种方法中,Pulsar 使用事件日志去保存命名空间的事件改变记录(比如主题策略改动)。
这种方式有以下好处:
避免过多使用Zookeeper, 给 Zookeeper 带来更高的负载。
使用 Pulsar 作为传播策略缓存的事件日志。可以有效地扩展。
可以使用Pulsar SQL 可以查询命名空间的改变日志,并对系统进行审计。
每个命名空间有一个叫做__change_events的系统主题。这个系统主题用来保存这个命名空间的事件改变信息。
你可以使用 pulsar-admin 工具来管理租户。
创建新租户
以下是租户创建命令的示范:
$ bin/pulsar-admin tenants create my-tenant \
--admin-roles my-admin-role \
--allowed-clusters us-west,us-east
此命令会创建一个新租户 my-tenant,并允许它使用 us-west 和 us-east 集群。
成功自识别为拥有 my-admin-role 角色的客户端可以在这个租户上执行所有的管理型任务。
persistent://tenant/namespace/topic
总结
Apache pulsar作为架构合理的消息系统,将存储(bookkeeper)和计算(broker)分离,其集群伸缩性更好,并且由于broker为无状态的,其计算扩容也更为方便。总的来说,Apache pulsar值得一试。
