
推荐一款 10 行 Python 代码实现网页自动化工具

各种各样的网站在我们日常工作和学习中占据着举足轻重的地位,学习、影音娱乐、查询资料、协同办公,越来越多的任务都被迁移到浏览器
因此,网页也蕴含着很多有价值、我们能够用得到的资源
例如,数据、歌曲、影视、文本、图片;所以,这几年来爬虫这项技术也成了很多开发人员必备的技能之一
以 Python 爬虫为例,比较常用的爬虫手段是结合 Requests、正则表达式等有一定门槛的工具来完成,并且还需要对 HTML、Web 具有一定的基础
这把很多开发同学拒之门外,也让很多初学者花费很多功夫和时间来学习爬虫这些技能
其实,除了上述提到那些具有一定门槛的爬虫知识之外,有一些另辟蹊径的同学会选择 Selenium 这款 Web 应用测试工具来完成爬虫任务,它能够像真正的用户一样完成一系列的操作
Selenium已经很好用,但是,它的大多数交互还是和 Web 元素之间进行的,需要使用到 HTML id、Xpath、CSS 选择器,虽然自动化程度高了一些,但是还不算足够的容易使用。
而本文的主角Helium则是在 Selenium 的基础上封装的更加高级的 Web 自动化工具,它能够通过网页端可见的标签、名称来和 Web 进行交互,例如,
点击键盘按键 右键点击 悬浮 滚动鼠标 拖动文件 刷新 ......

通过Helium,即便不在了解 Html、CSS 这些知识,你依然可以轻松的完成 Web 自动化程序的开发,轻松掌握爬虫技能,同时能够辅助日常重复性劳动,彻底解放你的双手
Helium
为了方便大家理解和使用,Helium 作者把一些常用方法总结了一个清单
另外,在 Python 文件列出了公共函数,使用者可以通过阅读这个 Python 文件的代码来了解有哪些函数接口可以调用
在前面 GIF 动图中给出了 Helium 与 Github 的交互过程,其中涉及了我们常用的操作,例如,
输入账号密码 点击按钮 跳转网页
在这里,我就不再重复这个过程,下面以 爬取网页图片链接 的例子来讲解一下 Helium 的用法,同时把 Helium 的常用操作串联起来。各位可以根据自己的需求,举一反三,来发挥 Helium 的价值。
首先,来了解一下我们个人在下载图片的过程中的具体流程。
打开百度搜索; 搜索相关图片; 跳转到图片页面; 打开图片; 点击下载按钮;
下面,就通过 Helium 来逐步完成上述 5 步
打开百度搜索
Helium 可以直接打开对应的网址,目前支持 Chrome 和火狐浏览器,只要用到start_chrome或者start_firefox函数,下面以 Chrome 浏览器为例,
from helium import *
start_chrome("www.baidu.com")
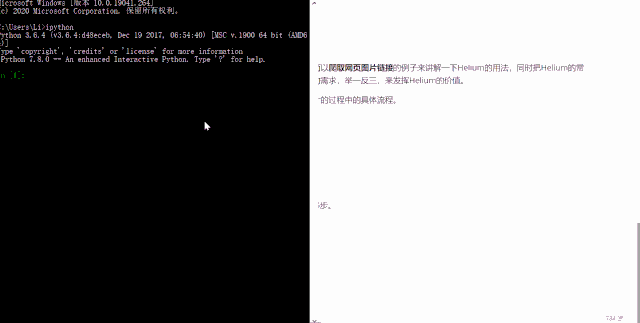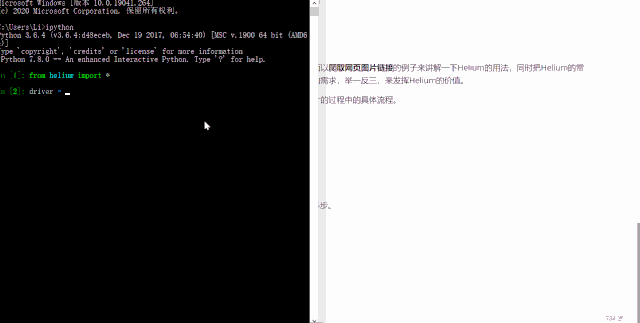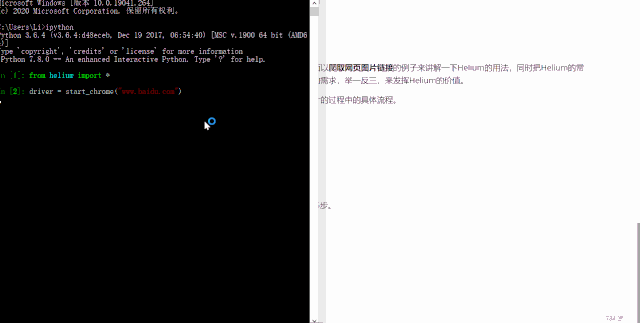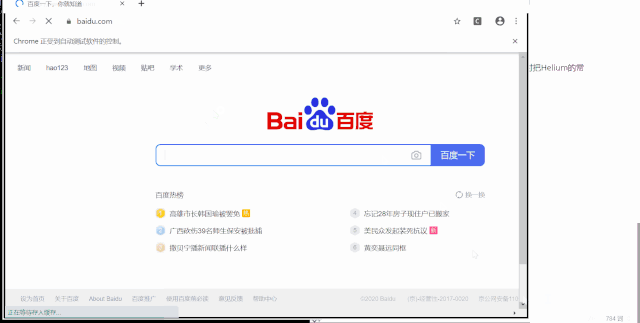
搜索图片&跳转到图片页面
搜索图片过程中,首先需要在搜索框输出想要的目标图片,然后点击百度一下或者按下ENTER键
write("詹姆斯")
click("百度一下")
// 或者
press(ENTER)
click("图片")
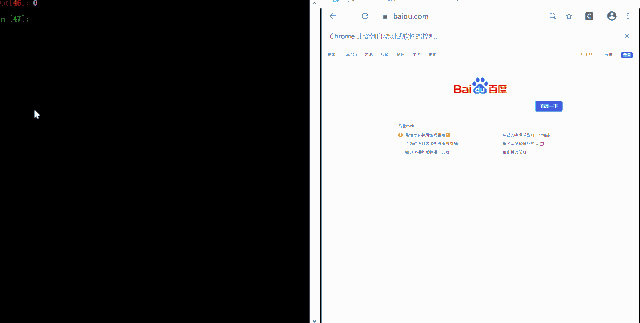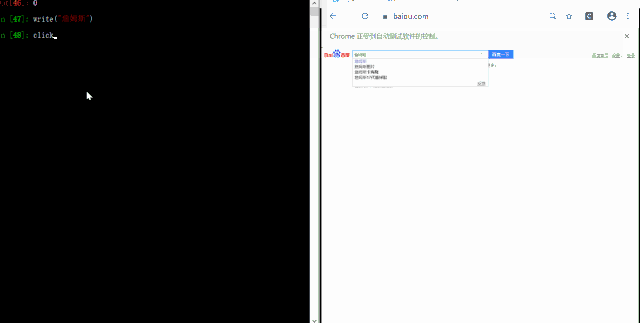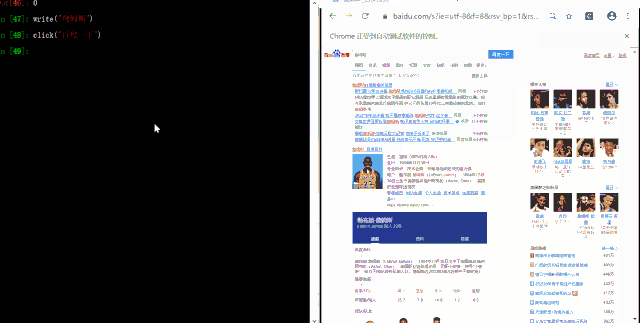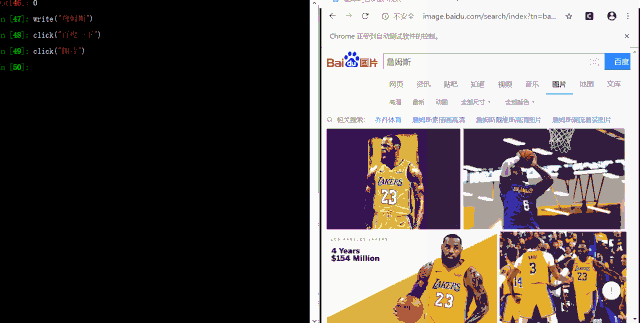
打开图片
在前面 Helium 与 Github 交互的示例中,我们发现,Sign in、Username 等都有标签名称。
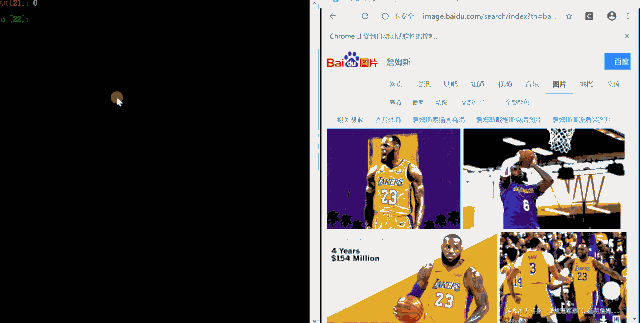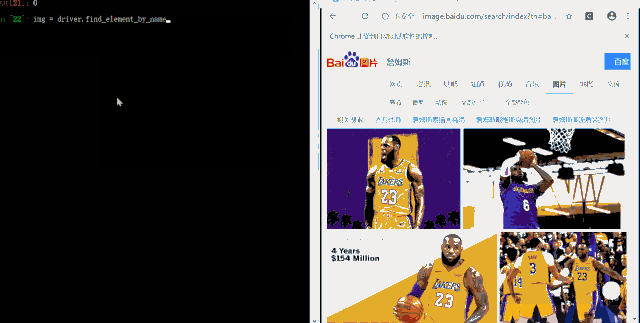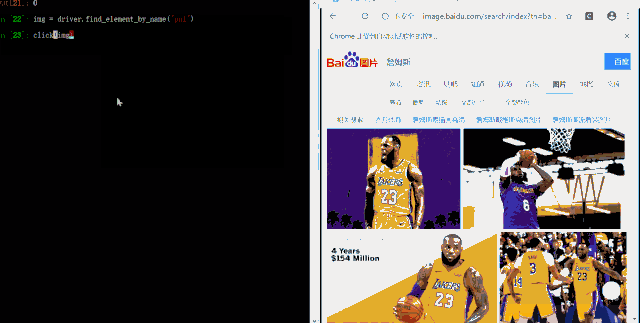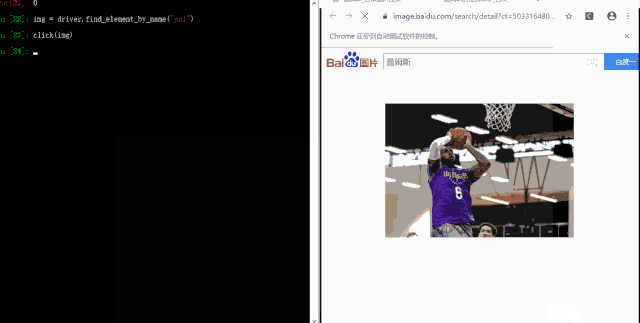
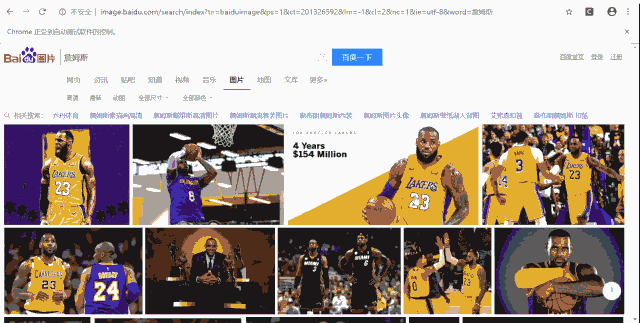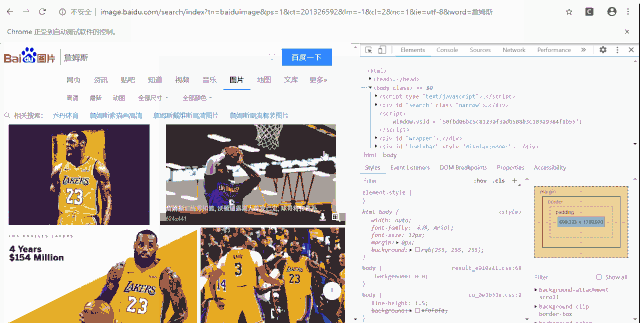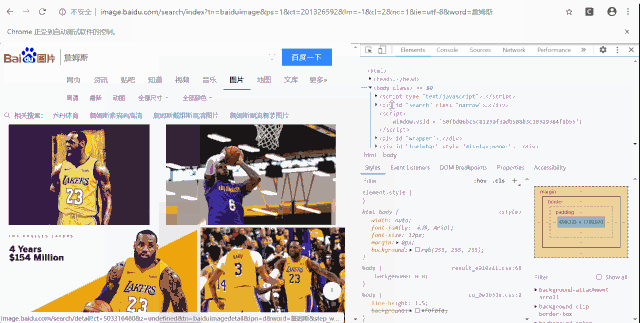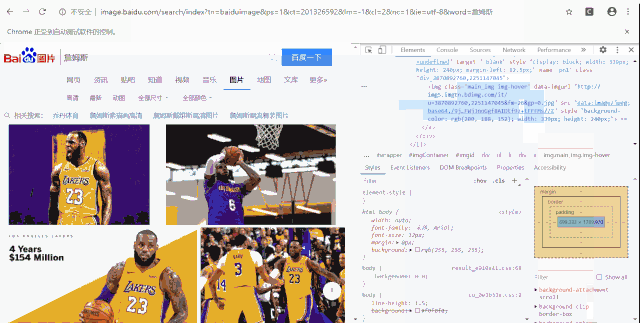
但是,我们在这里跳转到图片页面时,发现每幅图片并没有 标签,那么我们该怎么确定点击哪一幅图呢?
好在 Helium 兼容了 Selenium 的接口,我们可以通过 Selenium 来获取页面的元素,然后结合 Helium 的点击就可以实现打开图片这一步骤
// pn1是其中一幅图的名称,通过名称来获取对应的元素,然后调用Helium的click函数点击图片
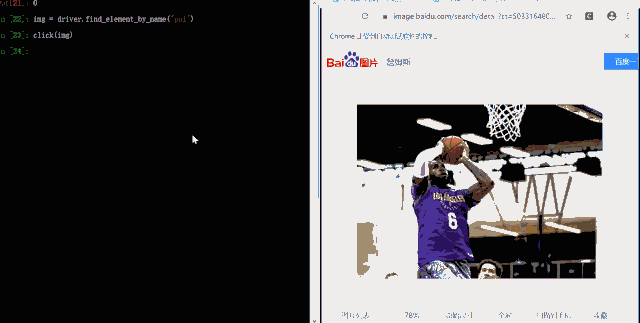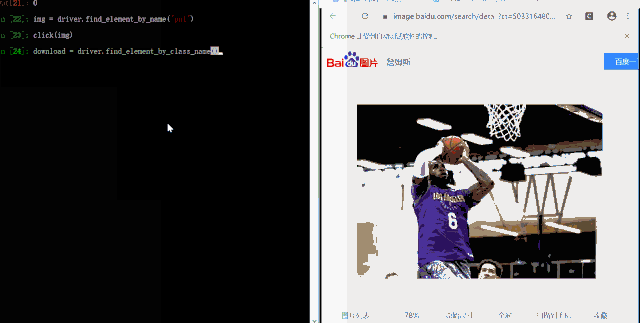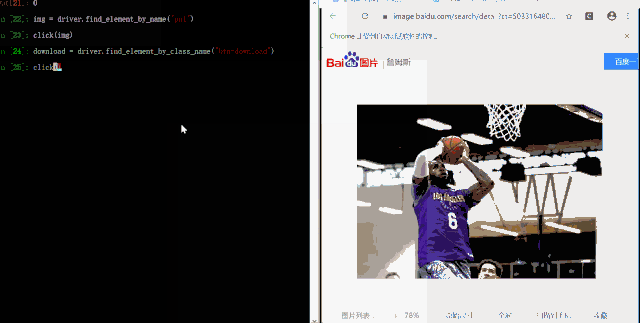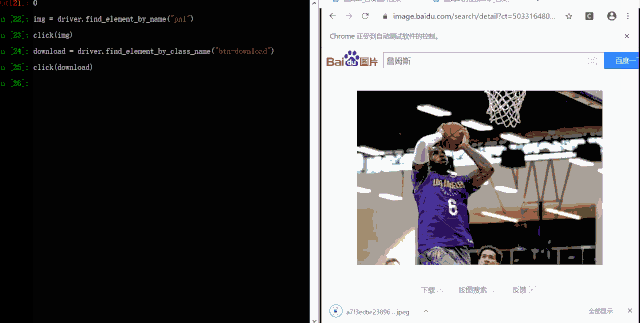
img = driver.find_element_by_name("pn1")
click(img)
点击下载按钮
最后一步就是点击下载按钮,这一步和上一步类似,我们先通过 Selenium 的接口来获取 Web 元素,然后点击即可
download = driver.find_element_by_class_name("btn-download")
click(download)
到这里,就完成了整个自动化爬取图片的过程,完成代码如下,
from helium import *
start_chrome("www.baidu.com")
write("詹姆斯")
press(ENTER)
click("图片")
img = driver.find_element_by_name("pn1")
click(img)
download = driver.find_element_by_class_name("btn-download")
click(download)
可以看出,整条爬取图片的代码仅仅需要 10 行代码,和人为手动操作步骤一样,非常简单。
除了下载图片这项简单的任务,我们也可以利用它开发一款自动化的工具,例如文件的上传、编辑、下载影视音乐、B站视频等,可以举一反三。
如何查询指定元素名称?
在前面事例中,涉及到pn1、btn-download这 2 个 HTML 层面的内容,分别是元素名称和元素类别名称,那么,这是怎么获取的呢?
其实,非常简单,我们只需要鼠标右键点击对应按钮,然后选择 检查 即可
好了,以上就是利用 Helium 实现网页自动化的常规操作,大家也来试试吧。