
Apache Iceberg技术调研&在各大公司的实践应用大总结
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多惊喜

作者在实际工作中调研了Iceberg的一些优缺点和在各大厂的应用,总结在下面。希望能给大家带来一些启示。
随着大数据存储和处理需求越来越多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式的数据分析,成了企业构建大数据生态的一个重要方向。如何快速、一致、原子性地在数据湖存储上构建起 Data Pipeline,成了亟待解决的问题。
为此,Uber 开源了 Apache Hudi,Databricks 提出了 Delta Lake,而 Netflix 则发起了 Apache Iceberg 项目,一时间这种具备 ACID 能力的表格式中间件成为了大数据、数据湖领域炙手可热的方向。
我们曾经在之前曾经介绍过数据湖的概念和具体应用:
为什么选择 Iceberg?
谈及引入 Iceberg 的原因,在构建大数据生态的过程中遇到的一些痛点 Iceberg 恰好能解决:
T+0 的数据落地和处理。传统的数据处理流程从数据入库到数据处理通常需要一个较长的环节、涉及许多复杂的逻辑来保证数据的一致性,由于架构的复杂性使得整个流水线具有明显的延迟。Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟。
降低数据修正的成本。传统 Hive/Spark 在修正数据时需要将数据读取出来,修改后再写入,有极大的修正成本。Iceberg 所具有的修改、删除能力能够有效地降低开销,提升效率。
至于为何最终选择采用 Iceberg,而不是其他两个开源项目,技术方面的考量主要有以下几点:
Iceberg 的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如 Flink、Hive、Spark)对接,这对于腾讯内部落地是非常重要的,因为上下游数据管道的衔接往往涉及到不同的计算引擎;
良好的架构和开放的格式。相比于 Hudi、Delta Lake,Iceberg 的架构实现更为优雅,同时对于数据格式、类型系统有完备的定义和可进化的设计;
面向对象存储的优化。Iceberg 在数据组织方式上充分考虑了对象存储的特性,避免耗时的 listing 和 rename 操作,使其在基于对象存储的数据湖架构适配上更有优势。
除去技术上的考量,代码质量、社区等方面详细的评估如下:
整体的代码质量以及未来的进化能力。整体架构代码上的抽象和优势,以及这些优势对于未来进行演化的能力是团队非常关注的。一门技术需要能够在架构上持续演化,而不会具体实现上需要大量的不兼容重构才能支持。
社区的潜力以及腾讯能够在社区发挥的价值。社区的活跃度是另一个考量,更重要的是在这个社区中腾讯能做些什么,能发挥什么样的价值。如果社区相对封闭或已经足够成熟,那么腾讯再加入后能发挥的价值就没有那么大了,在选择技术时这也是团队的一个重要考量点。
技术的中立性和开放性。社区能够以开放的态度去推动技术的演化,而不是有所保留地向社区贡献,同时社区各方相对中立而没有一个相对的强势方来完全控制社区的演进。
腾讯对Iceberg的优化和改进
从正式投入研发到现在,腾讯在开源版本的基础上对 Iceberg 进行了一些优化和改进,主要包括:
实现了行级的删除和更新操作,极大地节省了数据修正和删除所带来的开销;
对 Spark 3.0 的 DataSource V2 进行了适配,使用 Spark 3.0 的 SQL 和 DataFrame 可以无缝对接 Iceberg 进行操作;
增加了对 Flink 的支持,可以对接 Flink 以 Iceberg 的格式进行数据落地。
这些改进点提高了 Iceberg 在落地上的可用性,也为它在腾讯内部落地提供了更为吸引人的特性。同时腾讯也在积极拥抱社区,大部分的内部改进都已推往社区,一些内部定制化的需求也会以更为通用的方式贡献回社区。
目前团队正在积极尝试将 Iceberg 融入到腾讯的大数据生态中,其中最主要的挑战在于如何与腾讯现有系统以及自研系统适配,以及如何在一个成熟的大数据体系中寻找落地点并带来明显的收益。
Iceberg 的上下游配套能力的建设相对缺乏,需要较多的配套能力的建设,比如 Spark、Hive、Flink 等不同引擎的适配;
其次是 Iceberg 核心能力成熟度的验证,它是否能够支撑起腾讯大数据量级的考验,其所宣称的能力是否真正达到了企业级可用,都需要进一步验证和加强;
最后,腾讯内部大数据经过多年发展,已经形成了一整套完整的数据接入分析方案,Iceberg 如何能够在内部落地,优化现有的方案非常重要。
典型实践
Flink 集成 Iceberg 在同程艺龙的实践
痛点
由于采用的是列式存储格式 ORC,无法像行式存储格式那样进行追加操作,所以不可避免的产生了一个大数据领域非常常见且非常棘手的问题,即 HDFS 小文件问题。
Flink+Iceberg 的落地
Iceberg 技术调研
基于 HDFS 小文件、查询慢等问题,结合我们的现状,我调研了目前市面上的数据湖技术:Delta、Apache Iceberg 和 Apache Hudi,考虑了目前数据湖框架支持的功能和以后的社区规划,最终我们是选择了 Iceberg,其中考虑的原因有以下几方面:
Iceberg 深度集成 Flink
我们的绝大部分任务都是 Flink 任务,包括批处理任务和流处理任务,目前这三个数据湖框架,Iceberg 是集成 Flink 做的最完善的,如果采用 Iceberg 替代 Hive 之后,迁移的成本非常小,对用户几乎是无感知的,
比如我们原来的 SQL 是这样的:
INSERT INTO hive_catalog.db.hive_table SELECT * FROM kafka_table
迁移到 Iceberg 以后,只需要修改 catalog 就行。
INSERT INTO iceberg_catalog.db.iIcebergceberg_table SELECT * FROM kafka_table
Presto 查询也是和这个类似,只需要修改 catalog 就行了。
Iceberg 的设计架构使得查询更快
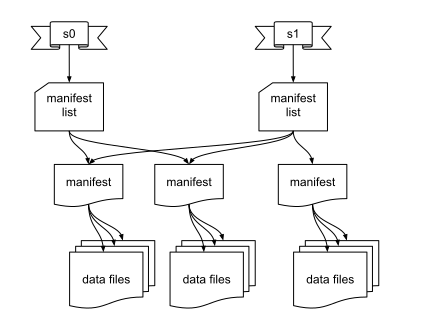
在 Iceberg 的设计架构中,manifest 文件存储了分区相关信息、data files 的相关统计信息(max/min)等,去查询一些大的分区的数据,就可以直接定位到所要的数据,而不是像 Hive 一样去 list 整个 HDFS 文件夹,时间复杂度从 O(n)降到了 O(1),使得一些大的查询速度有了明显的提升,在 Iceberg PMC Chair Ryan Blue 的演讲中,我们看到命中 filter 的任务执行时间从 61.5 小时降到了 22 分钟。
使用 Flink SQL 将 CDC 数据写入 Iceberg:Flink CDC 提供了直接读取 MySQL binlog 的方式,相对以前需要使用 canal 读取 binlog 写入 Iceberg,然后再去消费 Iceberg 数据。少了两个组件的维护,链路减少了,节省了维护的成本和出错的概率。并且可以实现导入全量数据和增量数据的完美对接,所以使用 Flink SQL 将 MySQL binlog 数据导入 Iceberg 来做 MySQL->Iceberg 的导入将会是一件非常有意义的事情。
此外对于我们最初的压缩小文件的需求,虽然 Iceberg 目前还无法实现自动压缩,但是它提供了一个批处理任务,已经能满足我们的需求。
Iceberg 优化实践
压缩小文件
代码示例参考:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Actions.forTable(env, table)
.rewriteDataFiles()
//.maxParallelism(parallelism)
//.filter(Expressions.equal("day", day))
//.targetSizeInBytes(targetSizeInBytes)
.execute();
目前系统运行稳定,已经完成了几万次任务的压缩。
查询优化
批处理定时任务
/home/flink/bin/fFlinklinklink run -p 10 -m yarn-cluster /home/work/iceberg-scheduler.jar my.sql
批任务的查询这块,我做了一些优化工作,比如 limit 下推,filter 下推,查询并行度推断等,可以大大提高查询的速度,这些优化都已经推回给社区,并且在 Iceberg 0.11 版本中发布。
运维管理
清理 orphan 文件
快照过期处理
数据管理
Flink + Iceberg 全场景实时数仓的建设实践
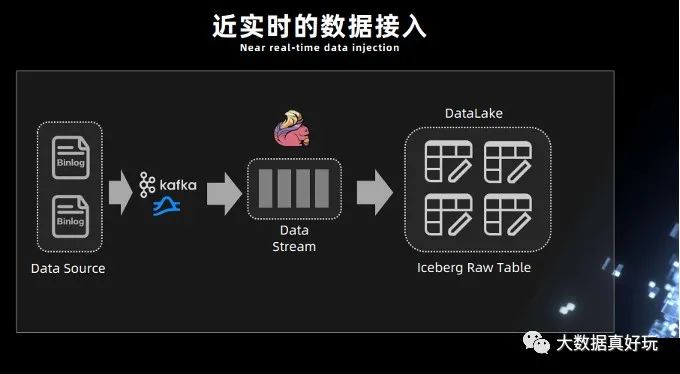
1.近实时的数据接入
Iceberg 既支持读写分离,又支持并发读、增量读、小文件合并,还可以支持秒级到分钟级的延迟,基于这些优势我们尝试采用 Iceberg 这些功能来构建基于 Flink 的实时全链路批流一体化的实时数仓架构。
如下图所示,Iceberg 每次的 commit 操作,都是对数据的可见性的改变,比如说让数据从不可见变成可见,在这个过程中,就可以实现近实时的数据记录。
2.实时数仓 - 数据湖分析系统
此前需要先进行数据接入,比如用 Spark 的离线调度任务去跑一些数据,拉取,抽取最后再写入到 Hive 表里面,这个过程的延时比较大。有了 Iceberg 的表结构,可以中间使用 Flink,或者 spark streaming,完成近实时的数据接入。
Iceberg 既然能够作为一个优秀的表格式,既支持 Streaming reader,又可以支持 Streaming sink,是否可以考虑将 Kafka 替换成 Iceberg?
Iceberg 底层依赖的存储是像 HDFS 或 S3 这样的廉价存储,而且 Iceberg 是支持 parquet、orc、Avro 这样的列式存储。有列式存储的支持,就可以对 OLAP 分析进行基本的优化,在中间层直接进行计算。例如谓词下推最基本的 OLAP 优化策略,基于 Iceberg snapshot 的 Streaming reader 功能,可以把离线任务天级别到小时级别的延迟大大的降低,改造成一个近实时的数据湖分析系统。
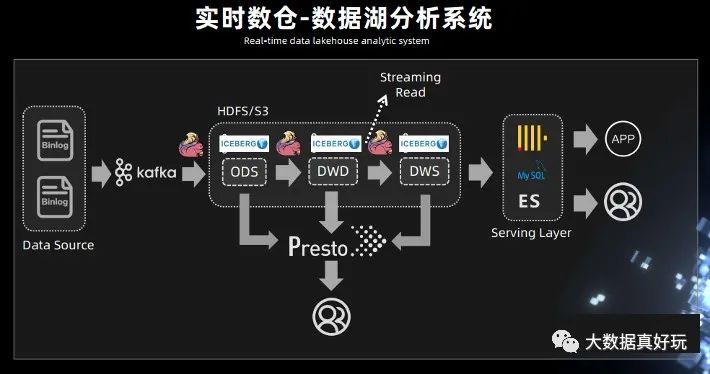
在中间处理层,可以用 presto 进行一些简单的查询,因为 Iceberg 支持 Streaming read,所以在系统的中间层也可以直接接入 Flink,直接在中间层用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。
Iceberg 替换 Kafka 的优势主要包括:
实现存储层的流批统一
中间层支持 OLAP 分析
完美支持高效回溯
存储成本降低
在 Iceberg 底层支持 Alluxio 这样一个缓存,借助于缓存的能力可以实现数据湖的加速。
3.最佳实践
实时小文件合并
Flink 实时增量读取
SQL Extension 管理文件
Flink + Iceberg 在去哪儿的实时数仓实践
1. 小文件处理
Iceberg 0.11 以前,通过定时触发 batch api 进行小文件合并,这样虽然能合并,但是需要维护一套 Actions 代码,而且也不是实时合并的。
Table table = findTable(options, conf); Actions.forTable(table).rewriteDataFiles() .targetSizeInBytes(10 * 1024) // 10KB .execute();
Iceberg 0.11 新特性,支持了流式小文件合并。
通过分区/存储桶键使用哈希混洗方式写数据、从源头直接合并文件,这样的好处在于,一个 task 会处理某个分区的数据,提交自己的 Datafile 文件,比如一个 task 只处理对应分区的数据。这样避免了多个 task 处理提交很多小文件的问题,且不需要额外的维护代码,只需在建表的时候指定属性 write.distribution-mode,该参数与其它引擎是通用的,比如 Spark 等。
CREATE TABLE city_table ( province BIGINT, city STRING ) PARTITIONED BY (province, city) WITH ( 'write.distribution-mode'='hash' );
2. Iceberg 0.11 排序
2.1 排序介绍
在 Iceberg 0.11 之前,Flink 是不支持 Iceberg 排序功能的,所以之前只能结合 Spark 以批模式来支持排序功能,0.11 新增了排序特性的支持,也意味着,我们在实时也可以体会到这个好处。
排序的本质是为了扫描更快,因为按照 sort key 做了聚合之后,所有的数据都按照从小到大排列,max-min 可以过滤掉大量的无效数据。

2.2 排序 demo
insert into Iceberg_table select days from Kafka_tbl order by days, province_id;
3. Iceberg 排序后 manifest 详解
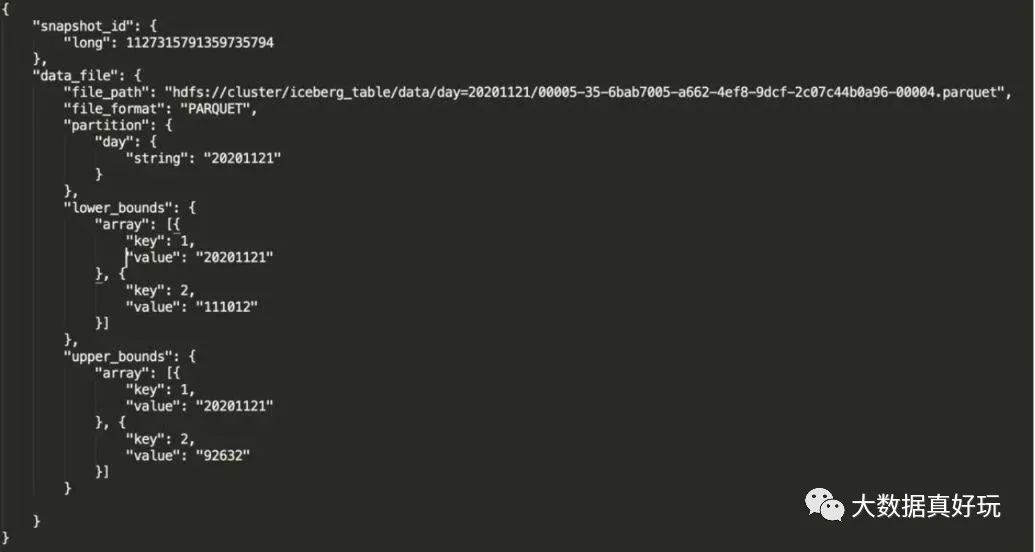
参数解释
file_path:物理文件位置。
partition:文件所对应的分区。
lower_bounds:该文件中,多个排序字段的最小值,下图是我的 days 和 province_id 最小值。
upper_bounds:该文件中,多个排序字段的最大值,下图是我的 days 和 province_id 最大值。
通过分区、列的上下限信息来确定是否读取 file_path 的文件,数据排序后,文件列的信息也会记录在元数据中,查询计划从 manifest 去定位文件,不需要把信息记录在 Hive metadata,从而减轻 Hive metadata 压力,提升查询效率。
利用 Iceberg 0.11 的排序特性,将天作为分区。按天、小时、分钟进行排序,那么 manifest 文件就会记录这个排序规则,从而在检索数据的时候,提高查询效率,既能实现 Hive 分区的检索优点,还能避免 Hive metadata 元数据过多带来的压力。
基于 Flink+Iceberg 构建企业级实时数据湖
目前 Apache Iceberg 0.10.0 版本上实现 Flink 流批入湖功能,同时还支持 Flink 批作业查询 Iceberg 数据湖的数据。
我们知道,Flink iceberg sink 的设计原理是由 Iceberg 采用乐观锁的方式来实现 Transaction 的提交,也就是说两个人同时提交更改事务到 Iceberg 时,后开始的一方会不断重试,等先开始的一方顺利提交之后再重新读取 metadata 信息提交 transaction。考虑到这一点,采用多个并发算子去提交 transaction 是不合适的,容易造成大量事务冲突,导致重试。
所以,把 Flink 写入流程拆成了两个算子,一个叫做 IcebergStreamWriter,主要用来写入记录到对应的 avro、parquet、orc 文件,生成一个对应的 Iceberg DataFile,并发送给下游算子;另外一个叫做 IcebergFilesCommitter,主要用来在 checkpoint 到来时把所有的 DataFile 文件收集起来,并提交 Transaction 到 Apache iceberg,完成本次 checkpoint 的数据写入。
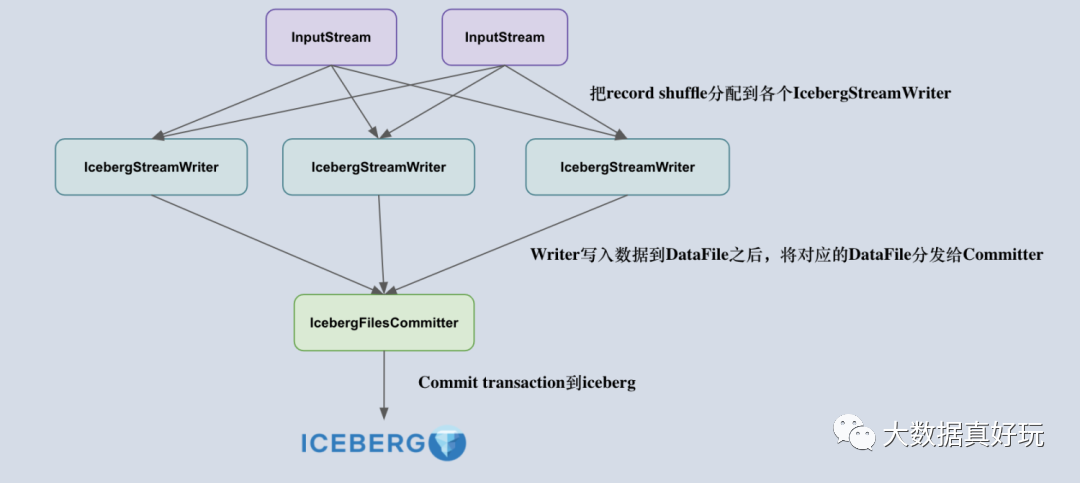
理解了 Flink Sink 算子的设计后,下一个比较重要的问题就是:如何正确地设计两个算子的 state ?
首先,IcebergStreamWriter 的设计比较简单,主要任务是把记录转换成 DataFile,并没有复杂的 State 需要设计。IcebergFilesCommitter 相对复杂一点,它为每个 checkpointId 维护了一个 DataFile 文件列表,即 map>,这样即使中间有某个 checkpoint 的 transaction 提交失败了,它的 DataFile 文件仍然维护在 State 中,依然可以通过后续的 checkpoint 来提交数据到 Iceberg 表中。
Iceberg0.11 与 Spark3.0 结合
1.安装编译 Iceberg0.11
此处我下载的是 Iceberg0.11.1 版本需要提前安装 gradle,iceberg 的编译,此处使用的是 gradle5.4.1 版本
wget https://downloads.gradle.org/distributions/gradle-5.4-bin.zip
unzip -d /opt/gradle gradle-5.4-bin.zip
vim /etc/profile
# 加入下面的
#GREDLE
export GRADLE_HOME=/opt/gradle/gradle-5.4
export PATH=$PATH:$GRADLE_HOME/bin
source /etc/profile
编译 Iceberg,github 上下载源码进行编译,此处略过下载过程直接进行编译
cd iceberg-apache-iceberg-0.11.1
gradle build -x test
2. Iceberg 编译与 SparkSQL 相结合
2.1 上述编译成功后到 spark3 目录下取出我们所需的 jar 包
cd spark3-runtime/build/libs
ll

iceberg-spark3-runtime-0.11.1.jar 为我们所需的插件包
2.2 将插件包放入到 spark 目录下
cd $SPARK_HOME/jars
cp iceberg-apache-iceberg-0.11.1/spark3-runtime/build/libs/iceberg-spark3-runtime-0.11.1.jar .
2.3 修改 spark 相应的配置
模式一:用 hadoop 当元数据
在 spark-defaults.confspark.sql.catalog.iceberg=org.apache.iceberg.spark.SparkCatalogspark.sql.catalog.iceberg.type=hadoopmapreduce.output.fileoutputformat.outputdir=/tmpspark.sql.catalog.iceberg.warehouse=hdfs://mycluster/iceberg/warehouse
模式二:元数据共用 hive.metastore
在 spark-defaults.confspark.sql.catalog.hive_iceberg = org.apache.iceberg.spark.SparkCatalogspark.sql.catalog.hive_iceberg.type = hivespark.sql.catalog.hive_iceberg.uri = thrift://node182:9083
下面的例子都是按模式二:元数据共用 hive.metastore进行。
1.spark 进行安装完毕,此处不再详述,conf 目录下需要有 hdfs-site.xml,core-site.xml,mared-reduce.xml,hive-site.xml,yarn-site.xml,这里就不多描述了
2.在 spark-defaults.conf 下加入下面的语句
spark.sql.catalog.iceberg = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.iceberg.type = hive
spark.sql.catalog.iceberg.uri = thrift://node182:9083
其中 spark.sql.catalog.iceberg.uri 是参照 hive-site.xml 中配置 spark.sql.catalog.iceberg,其中的 iceberg 为 namespace 的意思命名空间,下面我们创建 database 都要在此命名空间之下。
<property>
<name>hive.metastore.uris</name>
<value>thrift://172.16.129.182:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
2.4 启动 Spark
1)启动 Spark 的 thriftserver 服务
sh start-thriftserver.sh --master yarn
2)用 beeline 进行连接
bin/beeline
!connect jdbc:hive2://node182:25001 spark spark

此处连接的端口号从 hive-site.xml 中配置读取
<property>
<name>hive.server2.thrift.port</name>
<value>25001</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
2.5 创建 iceberg 源表
1)创建 database
create database iceberg.jzhou_test;

想看当前 namespace 用下面命令
show current namespace;

2)创建 iceberg 源的表
use iceberg.jzhou_test;
create table iceberg_spark(id int, name string) using iceberg;
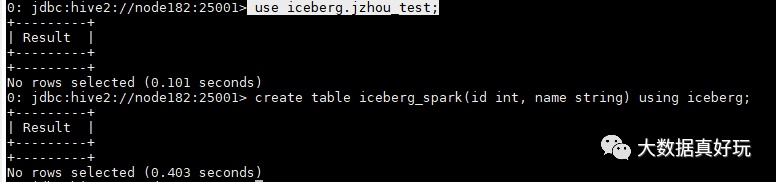
可以修改底层 file_format,此处默认为 parquet,但是我想修改为 orc,两种方法:
方法一:
ALTER TABLE iceberg_spark SET TBLPROPERTIES('write.format.default' = 'orc');
方法二:
create table iceberg_spark(id int, name string) using iceberg TBLPROPERTIES ('write.format.default' = 'orc');
3)插入数据,并看 hdfs 上表的元数据
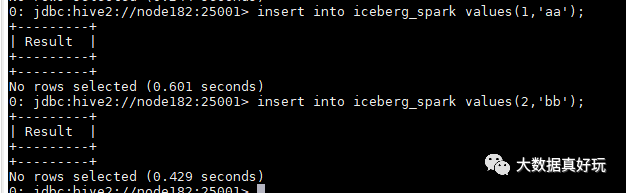
元数据所在 hdfs 目录可以从 hive-site.xml 的配置中得到:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
看到 hdfs 上数据与元数据
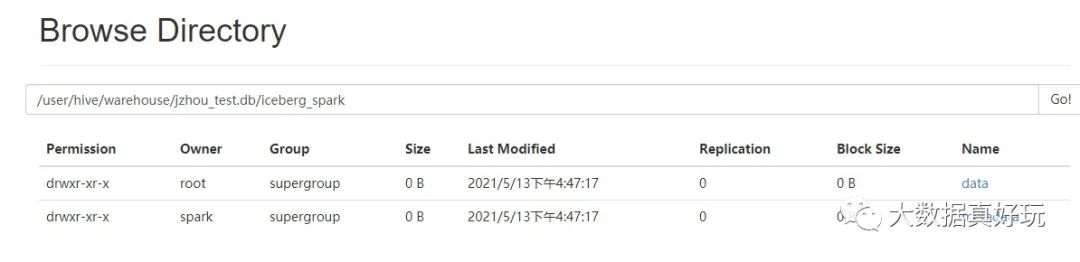

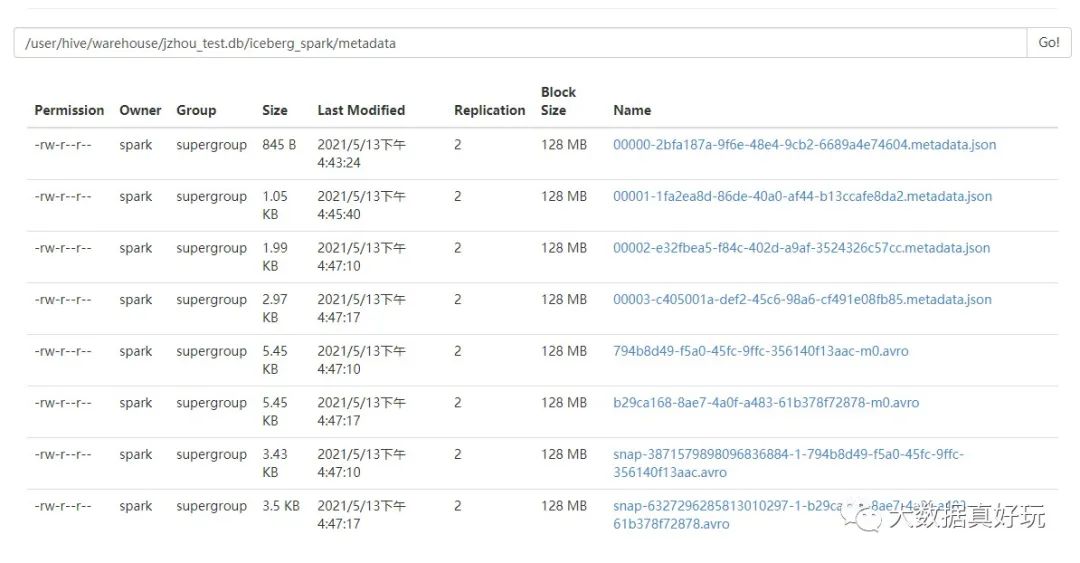
总结
IceBerg目前在高速迭代中,越来越多大公司加入到了 Iceberg 的贡献中,包括 Netflix、Apple、Adobe、Expedia 等国外大厂,也包括腾讯、阿里、网易等国内公司。一个好的技术架构最终会得到更多人的认可。随着国内推广的增多,以及国内开发者在这个项目上的投入、运营,未来在国内 Iceberg 前景可期。
