
Hudi 实践 | Apache Hudi 在 Hopsworks 机器学习的应用
Hopsworks特征存储库统一了在线和批处理应用程序的特征访问而屏蔽了双数据库系统的复杂性。我们构建了一个可靠且高性能的服务,以将特征物化到在线特征存储库,不仅仅保证低延迟访问,而且还保证在服务时间可以访问最新鲜的特征值。
企业机器学习模型为指导产品用户交互提供了价值价值。通常这些 ML 模型应用于整个实体数据库,例如由唯一主键标识用户。离线应用程序的一个示例是预测客户终身价值(Customer Lifetime Value),其中可以定期(每晚、每周)分批预测,然后用于选择营销活动的目标受众。然而更先进的人工智能应用程序可以实时指导用户交互,例如推荐系统。对于这些在线应用程序,模型输入的某些部分(特征向量)将在应用程序本身中可用,例如最后点击的按钮,而特征向量的其他部分则依赖于历史或上下文数据,必须检索后端存储,例如用户在过去一小时内点击按钮的次数或按钮是否为热门按钮。
在这篇博客中,我们将深入探讨在线应用程序的需求细节,以及 Hopsworks特征库如何抽象并规避双存储系统的复杂性。
1. 生产中的机器学习模型
虽然具有(分析)模型的批处理应用程序在很大程度上类似于模型本身的训练,需要有效访问将要参与评分的大量数据,但在线应用程序需要低延迟访问给定主键的最新特征值,然后作为特征向量发送到模型服务实例进行推理。
据我们所知没有单一的数据库能够高性能满足这两个要求,因此数据团队倾向于将用于训练和批量推理的数据保留在数据湖中,而 ML工程师更倾向于构建微服务以将微服务中的特征工程逻辑复制到在线应用程序中。
然而,这给数据科学家和机器学习工程师带来了不必要的障碍,无法快速迭代并显着增加机器学习模型的用于生产环境的时间
•数据科学视角:数据和基础设施通过微服务紧密耦合,导致数据科学家无法从开发转向生产,也无法复用特征。•ML 工程视角:大量工程工作以保证对生产中数据的一致访问,正如 ML 模型在训练过程中所看到的那样。
2. Hopsworks特征存储库:透明的双存储系统
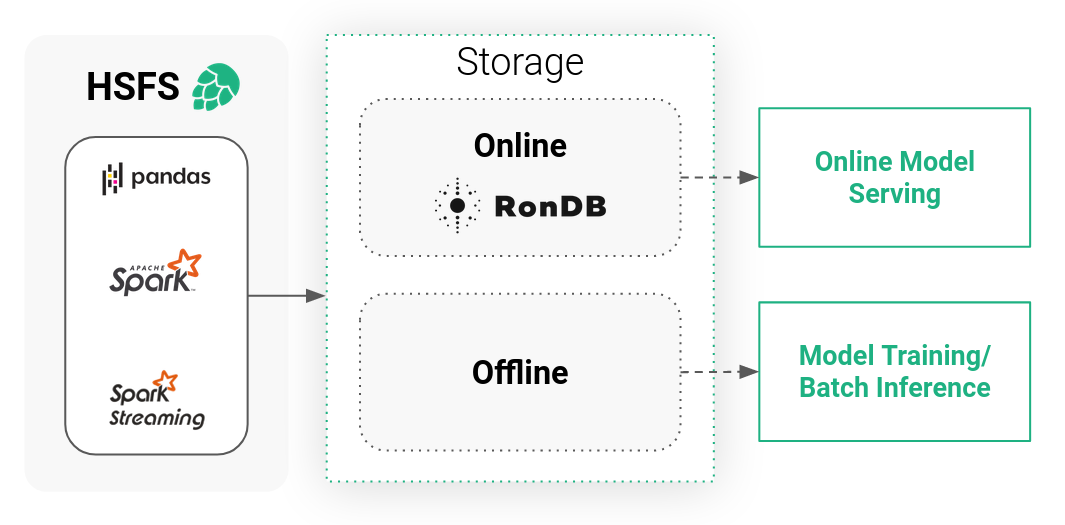
Hopsworks特征存储库是一个双存储系统,由高带宽(低成本)离线存储和低延迟在线存储组成。离线存储是我们 HopsFS 文件系统上的 Apache Hudi 表(由 S3 或 Azure Blob 存储支持)和外部表(例如 Snowflake、Redshift 等),提供对大量特征数据的访问以用于训练或批量评分。相比在线存储是一个低延迟的键值数据库,它只存储每个特征的最新值及其主键。因此在线特征存储充当这些特征值的低延迟缓存。
为了使该系统对数据科学家有价值并缩短生产时间,并为最终用户提供良好的体验,它需要满足一些要求:
•用于训练和服务的一致特征:在 ML 中,为生产中的特征复制精确的特征工程逻辑非常重要,因为它用于生成模型训练的特征。•特征新鲜度:低延迟、高吞吐量的在线特征存储只有在存储在其中的数据保持最新时才有益,特征新鲜度被定义为触发特征重新计算的事件到达与重新计算的特征在在线特征库中发布之间的端到端延迟。•延迟:在线特征库必须提供近乎实时的低延迟和高吞吐量,以便应用程序能够使用尽可能多的特征及其可用的SLA。•可访问性:数据需要可通过直观的 API 访问,就像从离线特征存储中提取数据进行训练一样容易。
Hopsworks在线特征库围绕四大支柱构建,以满足需求,同时扩展以管理大量数据:
•HSFS API:Hopsworks 特征存储库是开发人员特征存储的主要入口点,可用于 Python 和 Scala/Java。HSFS 将两个存储系统抽象出来,提供透明的 Dataframe API(Spark、Spark Structured Streaming、Pandas)用于在线和离线存储的写入和读取。•元数据:Hopsworks 可以存储大量自定义元数据,以便数据科学家发现、管理和复用特征,而且还能够在将模型移至生产时依赖模式和数据质量。•引擎:在线特征存储带有可扩展的无状态服务,可确保数据尽快写入在线特征存储,而不会从数据流(Spark 结构化流)或静态 Spark 或 Pandas DataFrame中进行写入放大,即不必在摄取特征之前先将特征物化到存储中 - 可以直接写入特征存储。•RonDB:在线存储背后的数据库是世界上最快的具有 SQL 功能的键值存储[1]。不仅为在线特征数据构建基础,而且还处理 Hopsworks 中生成的所有元数据。
我们将在以下部分详细介绍其中的每一部分,并提供一些用于定量比较的基准。
3. RonDB:在线特征存储,文件系统和元数据的基础
Hopsworks 是围绕分布式横向扩展元数据从头开始构建的。这有助于确保 Hopsworks 内服务的一致性和可扩展性,以及数据和 ML 工件的注释和可发现性。
自第一次发布以来,Hopsworks 一直使用 NDB Cluster(RonDB 的前身)作为在线特征存储。2020 年我们创建了 RonDB 作为 NDB Cluster 的托管版本,并针对用作在线特征存储进行了优化。
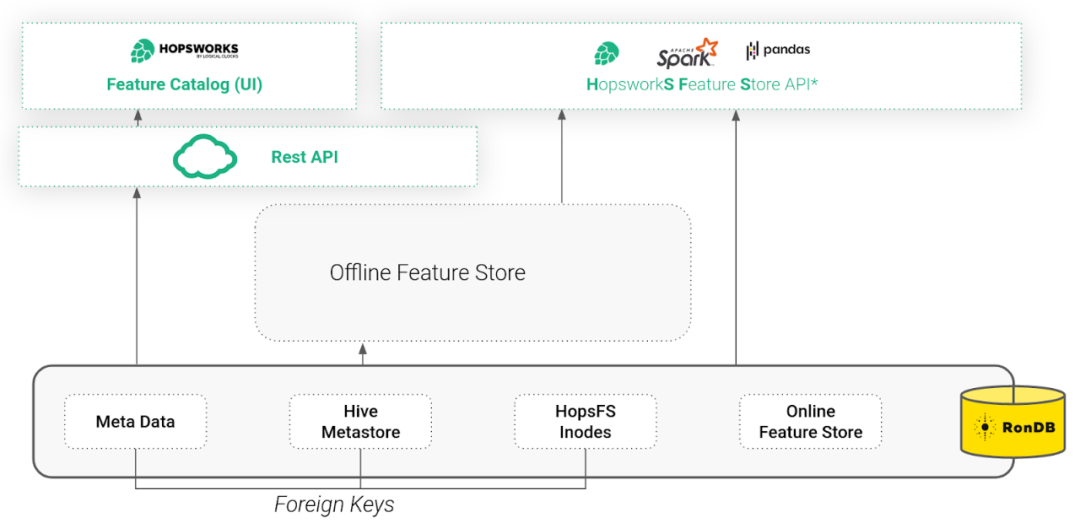
但是在 Hopsworks 中我们将 RonDB 用于不仅仅是在线特征存储。RonDB 还存储整个特征存储库的元数据,包括模式、统计信息和提交。RonDB 还存储了文件系统 HopsFS 的元数据,其中存储了离线 Hudi 表,具体实践可参考 如何将Apache Hudi应用于机器学习。使用 RonDB 作为单个元数据数据库,我们使用事务和外键来保持 Feature Store 和 Hudi 元数据与目标文件和目录(inode)一致。Hopsworks 可通过 REST API 或直观的 UI(包括特征目录)访问或通过 Hopsworks 特征存储 API (HSFS) 以编程方式访问。
4. OnlineFS:可扩展的在线特征物化引擎
有了底层的 RonDB 和所需的元数据,我们就能够构建一个横向扩展、高吞吐量的物化服务,以在在线特征存储上执行更新、删除和写入——我们简单地将其命名为 OnlineFS。
OnlineFS 是一种使用 ClusterJ 直接访问 RonDB 数据节点的无状态服务。ClusterJ 被实现为原生 C++ NDB API 之上的高性能 JNI 层,提供低延迟和高吞吐量。由于 RonDB 中元数据的可用性,例如 avro 模式和特征类型,我们能够使 OnlineFS 无状态。使服务无状态允许我们通过简单地添加或删除服务的实例来向上和向下扩展对在线特征存储的写入,从而随着实例的数量线性地增加或减少吞吐量。
让我们完成将数据写入在线特征存储所需的步骤,这些步骤在下图中编号。
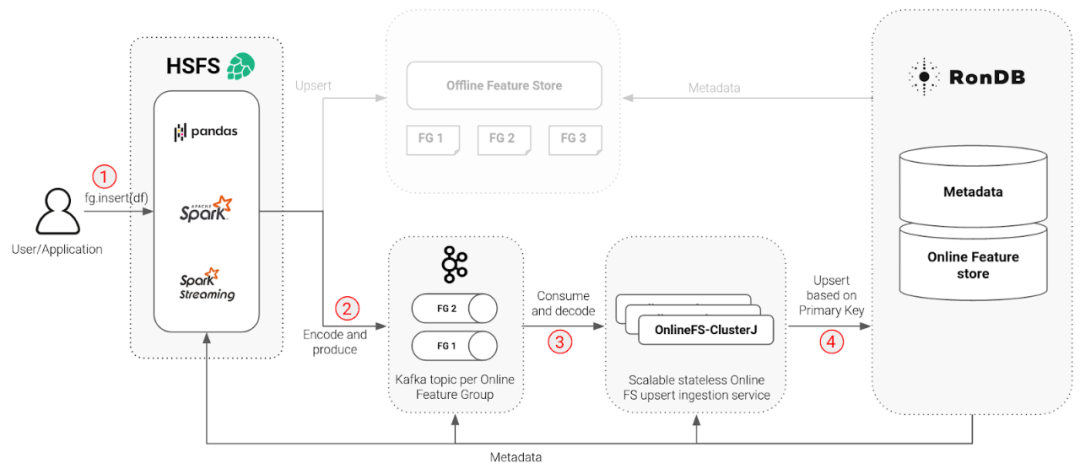
1.特征作为 Pandas 或 Spark DataFrame写入特征存储
每个 Dataframe 更新一个称为特征组的表(离线存储中有一个类似的表)。一个特征组中的特征共享同一个主键,可以是复合主键。主键与元数据的其余部分一起被跟踪。因此Hopsworks 特征存储库有一个 Dataframe API,这意味着特征工程的结果应该是将写入到特征存储的常规 Spark、Spark Structured Streaming 或 Pandas Dataframe。对于所有三种类型的DataFrame,用于写入特征存储的 API 几乎相同。通过对特征组对象的引用可以插入DataFrame。特征组在创建时已配置为将 Dataframe 存储到在线和离线库或仅存储到其中之一。
2.编码和产生
Dataframe 的行使用 avro 进行编码并写入在 Hopsworks 上运行的 Kafka中。每个特性组都有自己的 Kafka 主题,具有可配置的分区数量,并按主键进行分区,这是保证写入顺序所必需的。
3.消费和解码
我们使用 Kafka 来缓冲来自 Spark 特征工程作业的写入,因为直接写入 RonDB 的大型 Spark 集群可能会使 RonDB 过载,因为现有 Spark JDBC 驱动程序中缺乏背压。OnlineFS 从 Kafka 读取缓冲的消息并对其进行解码。重要的是OnlineFS 仅解码原始特征类型,而嵌入等复杂特征以二进制格式存储在在线特征存储中。
4.基于主键的Upsert
OnlineFS 可以使用 ClusterJ API 将行实际更新插入到 RonDB。Upsert 分批执行(具有可配置的批量大小)以提高吞吐量。
由于管道步骤中的所有服务都可以访问相同的元数据,因此我们能够向用户隐藏与编码和模式相关的所有复杂性。此外所有涉及的服务都是水平可扩展的(Spark、Kafka、OnlineFS),并且由于我们类似于流的设置,该过程不会创建不必要的数据副本,即没有写放大。由于模式注册表、X.509 证书管理器和 Hopsworks 中的 Kafka 等服务的可用性,这种高度可扩展的设置成为可能。在任何时候X.509 证书都用于双向身份验证,而 TLS 用于加密网络流量。
5. 可访问性意味着透明的 API
在分布式系统中,我们经常谈论透明度。如果分布式系统对开发人员隐藏网络访问和实现特定知识,则它是透明的。在 Hopsworks 特征存储库中,写入是通过相同的 API 透明地完成的,如前所述(1)无论是常规的 Spark、Spark Streaming 还是 Pandas 以及(2)系统负责一致地更新在线和离线存储
插入
HSFS 库中的核心抽象是表示特征组、训练数据集和特征存储中的特征的元数据对象。我们使用 HSFS 的目标是让开发人员能够使用他们喜欢的语言和框架来设计功能。当我们在 Dataframe API 上对齐时,Dataframe 中包含的任何内容都可以写入特征存储。如果您有现有的 ETL 或 ELT 管道,它们生成包含特征的数据帧,您可以通过简单地获取对其特征组对象的引用并使用您的数据帧作为参数调用 .insert() 来将该数据帧写入特征存储 . 这可以从定期安排的作业中调用(使用您选择的任何编排器,或者,如果您想要开箱即用的编排器,则 Hopsworks 附带 Airflow)。但是也可以通过将批次写入 Spark 结构化流应用程序中的数据帧来连续更新特征组对象。
# populate feature group metadata objectstore_fg_meta = fs.create_feature_group(name="store_fg",version=1,primary_key=["store"],description="Store related features",online_enabled=True)# create feature group for the first time in feature storefg.save(Dataframe)# replace .save with .insert for scheduled batch jobfg.insert(Dataframe)# if required, stream data only to the online feature store in long running Spark# Structured Streaming applicationfg.insert_stream(streaming_Dataframe)
读取
许多现有的特征存储没有模型的表示。然而Hopsworks 引入了训练数据集抽象来表示用于训练模型的特征集和特征值。也就是说,不可变的训练数据集和模型之间存在一对一的映射关系,但可变特征组与不可变的训练数据集之间是一对多的关系。您可以通过从特征组中加入、选择和过滤特征来创建训练数据集。训练数据集包括特征的元数据,例如它们来自哪个特征组、该特征组的提交 ID 以及训练数据集中特征的顺序。所有这些信息使 HSFS 能够在稍后的时间点重新创建训练数据集,并在服务时透明地构建特征向量。
# create a queryfeature_join = rain_fg.select_all() \.join(temperature_fg.select_all(), on=["location_id"]) \.join(location_fg.select_all())td = fs.create_training_dataset("rain_dataset",version=1,label=”weekly_rain”,data_format=”tfrecords”)# materialize query in the specified file formattd.save(feature_join)# we can also use the training dataset for serving# this serving code typically runs in a Python environmenttd = fs.get_training_dataset(“rain_dataset”, version=1)# get serving vectortd.get_serving_vector({“location_id”: “honolulu”})
在线特征库的使用方要么是使用 ML 模型的应用程序,要么是模型服务基础设施,这些基础设施通过缺失的特征来丰富特征向量。Hopsworks 为在线库提供了一个基于 JDBC 的 API。JDBC 具有提供高性能协议、网络加密、客户端身份验证和访问控制的优势。HSFS 为 Python 和 Scala/Java 提供语言级别的支持。但是,如果您的服务应用程序在不同的编程语言或框架中运行,您总是可以直接使用 JDBC。
6. Benchmarks
Mikael Ronstrom(NDB 集群的发明者和逻辑时钟的数据负责人,领导 RonDB 团队)为 RonDB 提供了 sysbench 基准测试,并提供了针对 Redis 的比较性能评估。在本节中我们展示了 OnlineFS 服务的性能,能够处理和维持写入在线特征存储的高吞吐量,以及对 Hopsworks 中典型托管 RonDB 设置的特征向量查找延迟和吞吐量的评估。
在此基准测试中,Hopsworks 设置了 3xAWS m5.2xlarge(8 个 vCPU,32 GB)实例(1 个头,2 个工作器)。Spark 使用 worker 将数据帧写入在线库。此外相同的工作人员被重新用作客户端,在在线特征存储上执行读取操作以进行读取基准测试。
RonDB 设置了 1x AWS t3.medium(2 vCPU,4 GB)实例作为管理节点,2x r5.2xlarge(8 vCPU,64 GB)实例作为数据节点,3x AWS c5.2xlarge(8 vCPU,16 GB) ) MySQL 服务器的实例。这种设置允许我们在具有 2 倍复制的在线特征存储中存储 64GB 的内存数据。MySQL 服务器为在线特征存储提供 SQL 接口,在此基准测试中,我们没有使 RonDB 数据节点完全饱和,因此可以潜在地添加更多 MySQL 服务器和客户端,以增加超出此处所示水平的吞吐量。
写吞吐
我们对 OnlineFS 服务中写入 RonDB 的吞吐量进行了基准测试。此外,我们测量了从 Kafka 主题中获取记录到提交到 RonDB 之间处理记录所需的时间。对于这个基准测试,我们部署了两个 OnlineFS 服务,一个在头节点上,一个在 MySQL 服务器节点之一上。
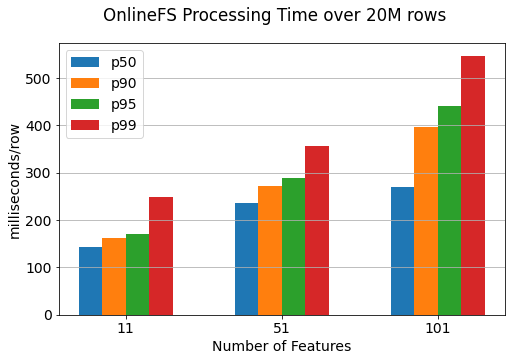
我们通过将 20M 行从 Spark 应用程序写入在线特征存储来运行实验。经过短暂的预热期后,两个服务实例的吞吐量稳定在约 126K 行/秒(11 个特征)、约 90K 行/秒(51 个特征)和最大特征向量约 60K 行/秒。由于其设计,这可以通过添加更多服务实例轻松扩展。
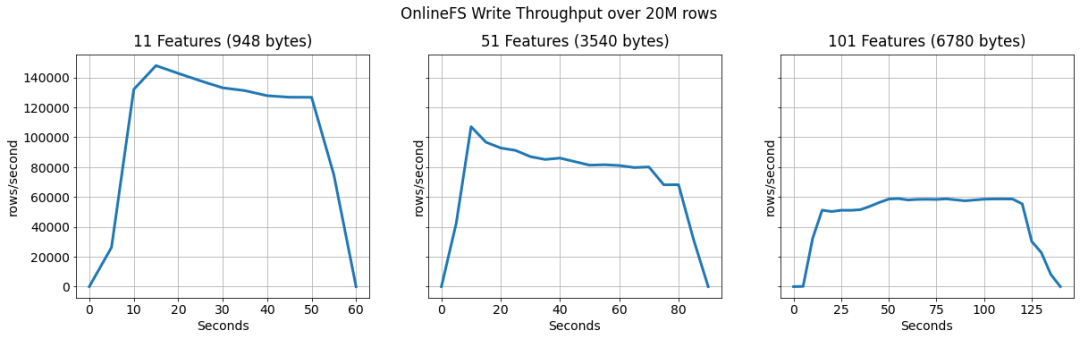
其次,我们输出了在 OnlineFS 服务中处理特征向量所需的时间。这个时间不包括一条记录在 Kafka 中等待处理的时间,原因是等待时间在很大程度上取决于写入 Kafka 的 Spark 执行程序的数量。
处理时间是按行报告的,但 OnlineFS 中的部分管道是并行化的,例如,行以 1000 的批次提交给 RonDB。通过这种设置,我们实现了 11 个特征的 p99 约为 250 毫秒,行大小为 948 字节。
服务查找吞吐量和延迟
我们对与越来越多的并行执行请求的客户端相关的不同特征向量大小的吞吐量和延迟进行了基准测试。请注意,客户端被分成两个工作节点(每个 8vCPU)。
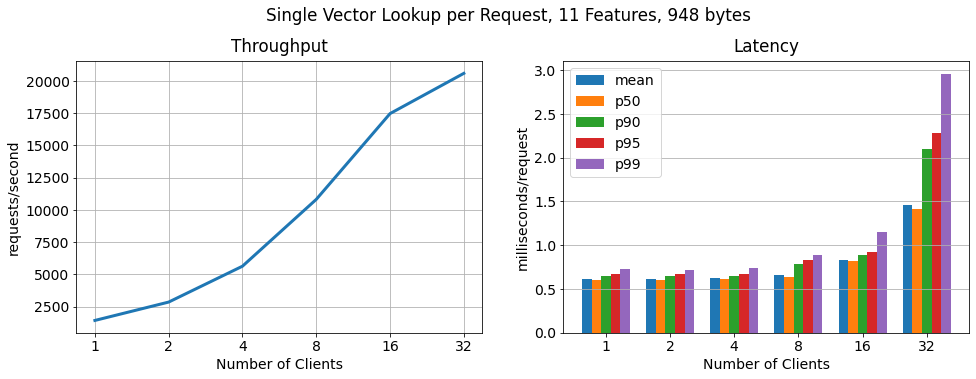
每个请求的单个向量
在这个基准测试中,每个请求都包含一个主键值查找(一个特征向量)。吞吐量和延迟可线性扩展至 16 个客户端,同时保持低延迟。对于超过 16 个客户端,我们观察到运行客户端的主机达到其最大 CPU 和网络利用率。此外,我们没有看到 RonDB 数据节点或 MySQL 服务器的过度使用,这意味着我们可以通过从更大的工作实例运行客户端或添加更多工作主机来运行客户端来进一步线性扩展。
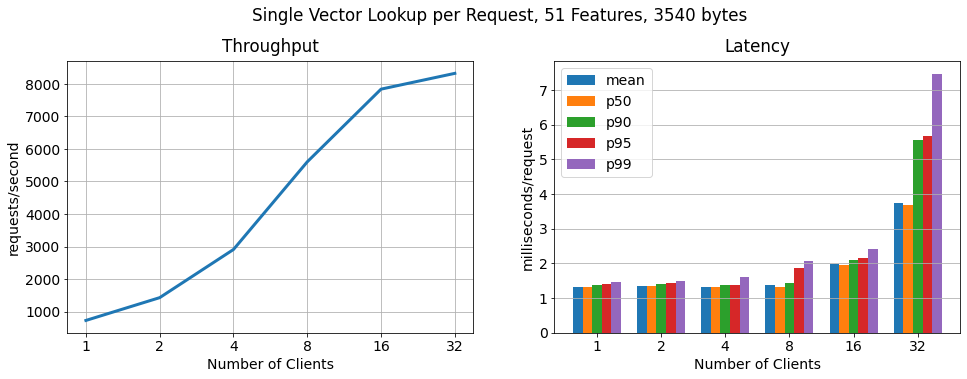
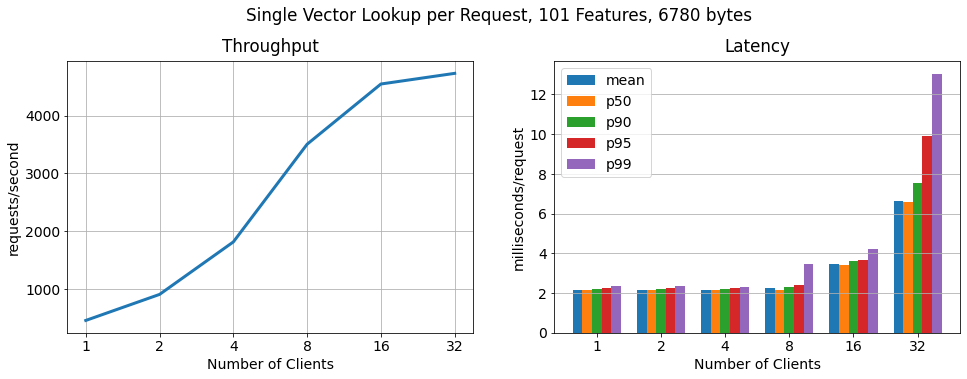
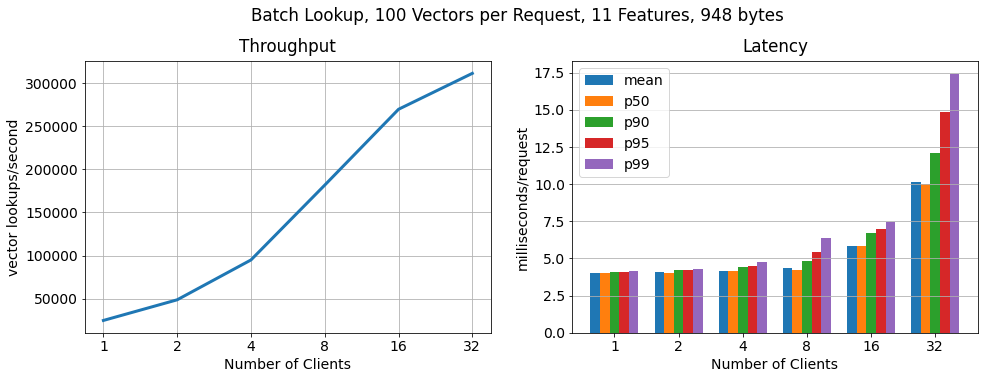
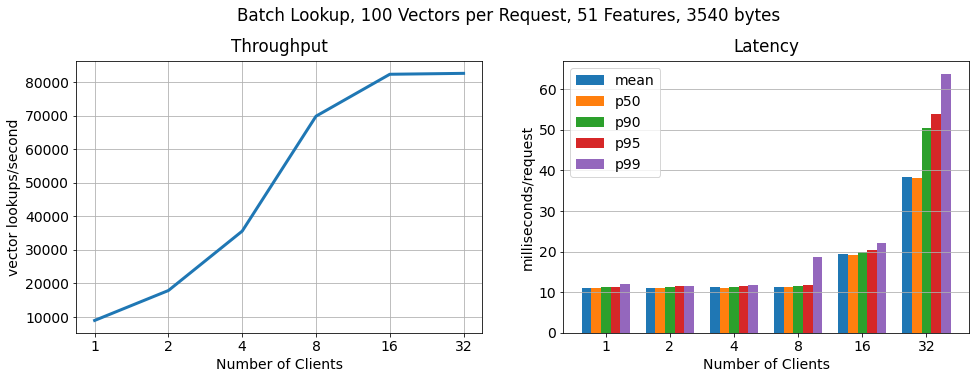
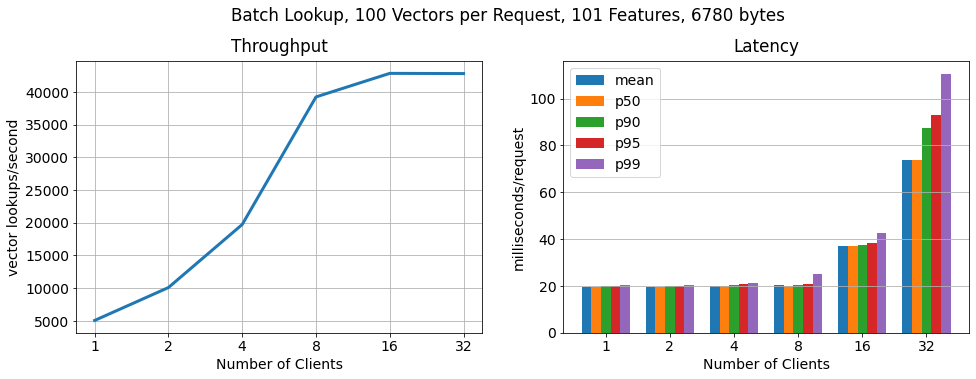
批处理,每个请求 100 个向量
为了证明 RonDB 每秒可扩展到更多的关键查找,我们运行了另一个基准测试,其中每个客户端以 100 个批次请求特征向量。正如我们所看到的查找数量仍然线性扩展,查找吞吐量增加了 15 倍,而 每个请求的延迟仅适度增加。
7. 结论
Hopsworks 附带托管 RonDB,为 Hopsworks 和在线特征提供统一的元数据存储。在这篇博客中,我们展示了一个高度可用的双节点 RonDB 集群(r5.2xlarge VM)线性扩展到 >250k ops/sec,特征向量查找的 11 个特征的大小约为 1KB,p99 延迟为 7.5 毫秒。因此Hopsworks 提供了当今市场上性能最高的在线特征库。
引用链接
[1] 世界上最快的具有 SQL 功能的键值存储: https://www.logicalclocks.com/blog/rondb-the-worlds-fastest-key-value-store-is-now-in-the-cloud