
干货,主流大数据技术总结

作者:justcodeit
数据量不断增加,企业需要灵活快速地处理这些数据。 处理器主频和散热遇到瓶颈,多核处理器成为主流,并行化计算应用不断增加。 开源软件的成功使得大数据技术得以兴起。

批量处理:单位是上百MB的数据块而非一条条数据,这样在数据读写时能够整体操作,减少IO寻址的时间消耗。 最终线性一致性:大数据技术很多都放弃线性一致性,这主要是跨行/文档(关系型模型叫行,文档型模型叫文档)时非原子操作,在一行/一个文档内还是会做到原子的。为了读写性能而允许跨行/文档出现读写延迟。 增加数据冗余:规范化的数据能够减少数据量,但在使用时需要关联才能获得完整数据,而在大数据下进行多次关联的操作是十分耗时的。为此,一些大数据应用通过合并宽表减少关联来提高性能。 列式存储:读取数据时只读取业务所关心的列而不需要把整行数据都取出再做进行截取,而且列式的压缩率更高,因为一列里一般都是同类的数据。
副本:大数据存储通常都会有副本设置,这样即便其中一份出现丢失,数据也能从副本找到。 高可用:大数据应用通常都会考虑高可用,即某个节点挂了,会有其他的节点来继续它的工作。
架构原理
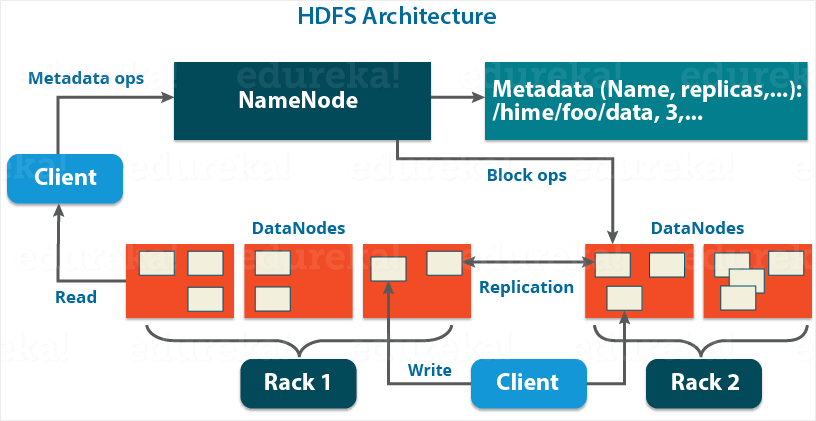
NameNode:作为master,管理元数据,包括文件名、副本数、数据块存储的位置,响应client的请求,接收workers的heartbeating和blockreport。 DataNode:管理数据(data block,存储在磁盘,包括数据本身和元数据)和处理master、client端的请求。定期向namenode发送它们所拥有的块的列表。 secondary namenode:备用master Block:默认128MB,但小于一个block的文件只会占用相应大小的磁盘空间。设置100+MB是为了尽量减少寻址时间占整个数据读取时间的比例,但如果block过大,又不适合数据的分散存储或计算。将数据抽象成block,还有其他好处,比如分离元数据和数据的存储、存储管理(block大小固定方便计算)、容错等。
读写流程
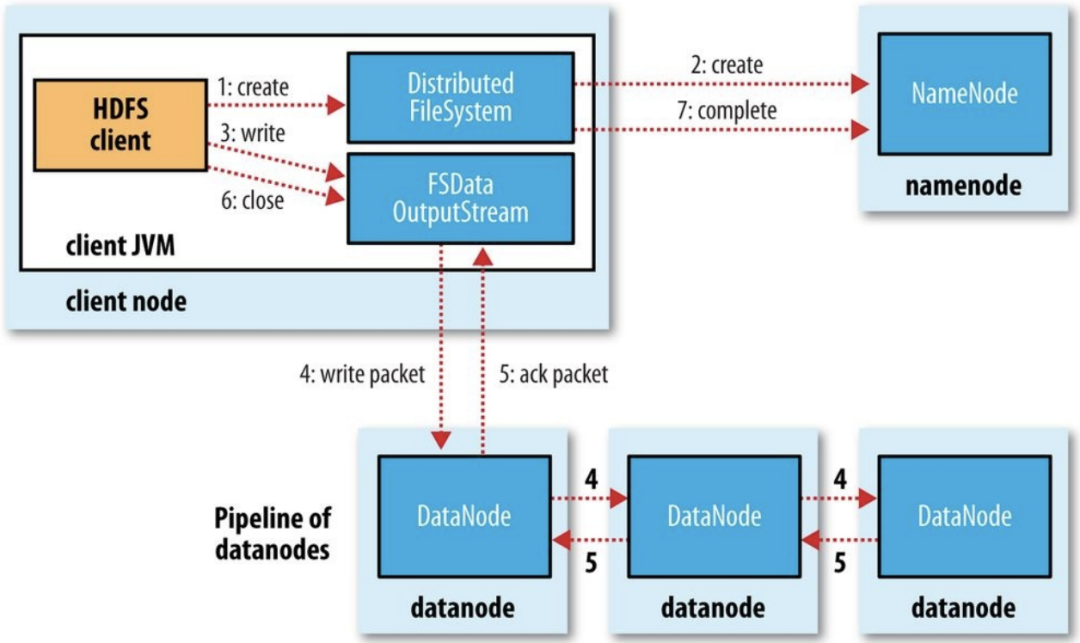
写入:client端调用filesystem的create方法,后者通过RPC调用NN的create方法,在其namespace中创建新的文件。NN会检查该文件是否存在、client的权限等。成功时返回FSDataOutputStream对象。client对该对象调用write方法,这个对象会选出合适存储数据副本的一组datanode,并以此请求DN分配新的block。这组DN会建立一个管线,例如从client node到最近的DN_1,DN_1传递自己接收的数据包给DN_2。DFSOutputStream自己还有一个确认队列。当所有的DN确认写入完成后,client关闭输出流,然后告诉NN写入完成。
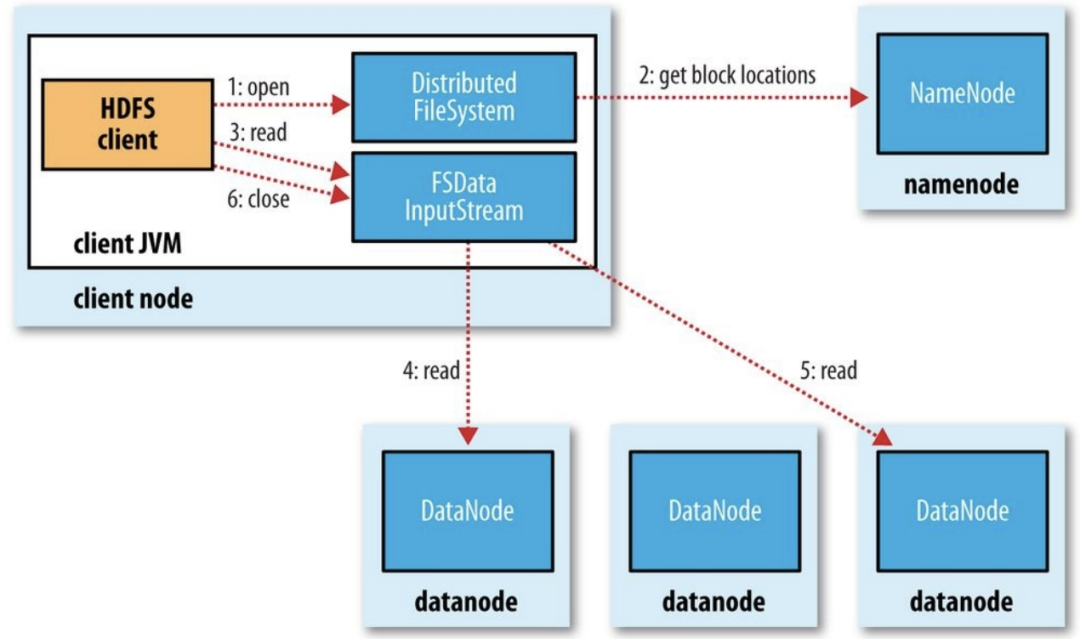
索引
| 哈希 | SSTables/LSM树 | BTree/B+Tree | |
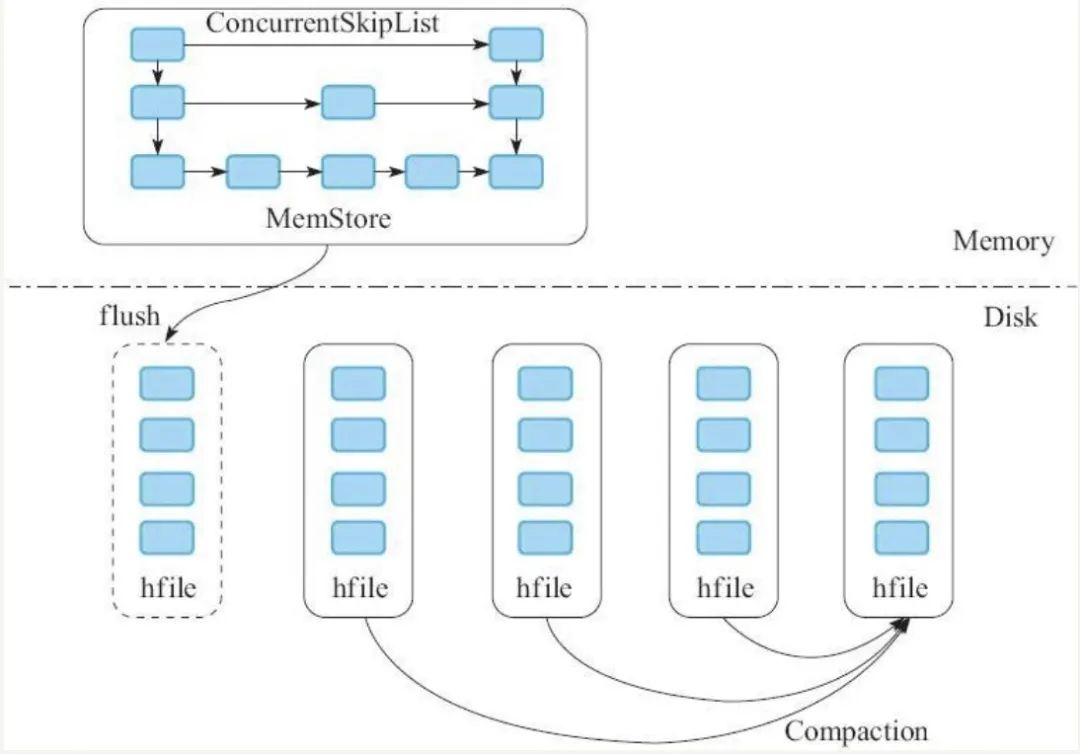
磁盘:一个个独立文件,里面包含一个个数据块。 写入:内存维护一个有序集合,数据大小达到一定阈值写入磁盘。后台会按照特定策略合并segment。 读取:先查询内存,然后磁盘中的最新segment,然后第二新,以此类推。 | |||
简介
特点
适合: 数据量大,单表至少超千万。对稀疏数据尤其适用,因为文档型数据库的 null 就相当于整个字段没有,是不需要占用空间的。 高并发写入,正如上面 LSM 树所说。 读取近期小范围数据,效率较高,大范围需要计算引擎支持。 数据多版本 不适合: 小数据 复杂数据分析,比如关联、聚合等,仅支持过滤 不支持全局跨行事务,仅支持单行事务
场景
对象存储:新闻、网页、图片 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上 消息/订单等历史数据:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上 Feeds流:典型的应用就是xx朋友圈类似的应用
架构原理

Client:发送DML、DDL请求,即数据的增删改查和表定义等操作。 ZooKeeper(类似微服务中的注册中心) 实现Master的高可用:当active master宕机,会通过选举机制选取出新master。 管理系统元数据:比如正常工作的RegionServer列表。 辅助RS的宕处理:发现宕机,通知master处理。 分布式锁:方式多个client对同一张表进行表结构修改而产生冲突。 Master 处理 client 的 DDL 请求 RegionServer 数据的负载均衡、宕机恢复等 清理过期日志 RegionServer:处理 client 和 Master 的请求,由 WAL、BlockCache 以及多个 Region 构成。 Store:一个Store存储一个列簇,即一组列。 MemStore和HFile:写缓存,阈值为128M,达到阈值会flush成HFile文件。后台有程序对这些HFile进行合并。 HLog(WAL):提高数据可靠性。写入数据时先按顺序写入HLog,然后异步刷新落盘。这样即便 MemoStore 的数据丢失,也能通过HLog恢复。而HBase数据的主从复制也是通过HLog回放实现的。 BlockCache Region:数据表的一个分片,当数据表大小达到一定阈值后会“水平切分”成多个Region,通常同一张表的Region会分不到不同的机器上。
读写过程
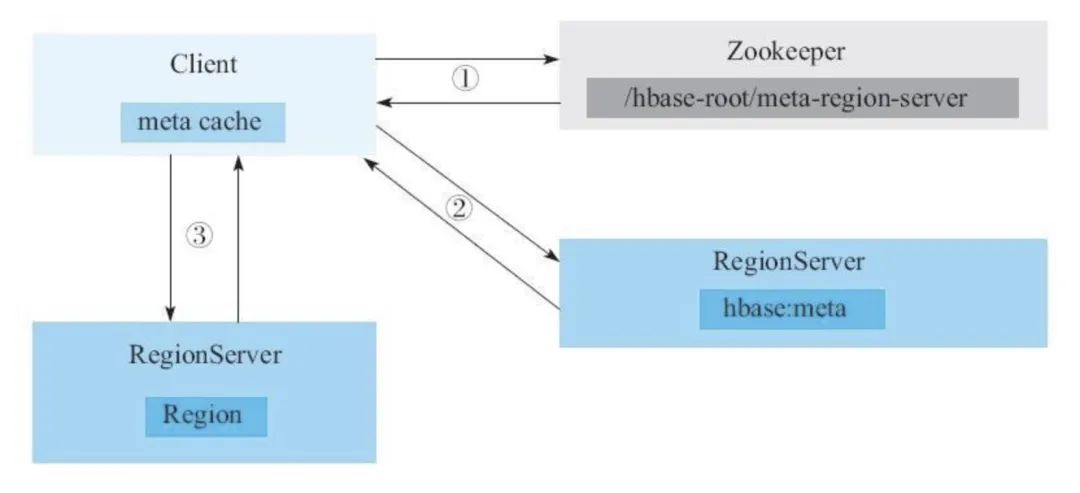
client 根据待写入数据的主键(rowkey)寻找合适的 RegionServer 地址,如果没有符合的,就向 zookeeper 查询存储HBase元数据表的 RegionServer 地址。 client 从第一步找到的 RegionServer 查询HBase元数据表,找出合适的写入地址。 将数据写入对应的 RegionServer 的 Region。
简介
利用 Logstash 同步 Mysql 数据时并非使用 binlog,而且不支持同步删除操作。
特点
适合: 全文检索,like "%word%" 一定写入延迟的高效查询 多维度数据分析 不合适: 关联 数据频繁更新 不支持全局跨行事务,仅支持单行事务
场景
数据分析场景 时序数据监控 搜索服务
框架原理
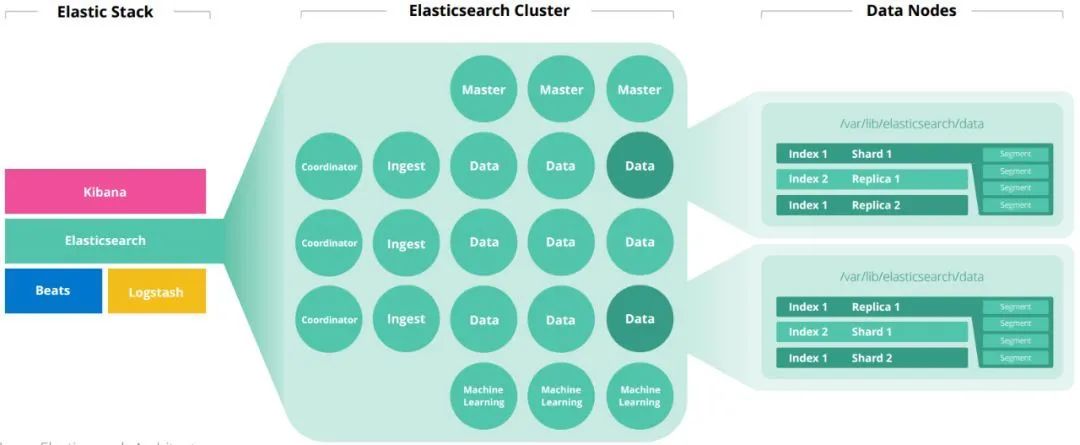
Master:主要负责集群中索引的创建、删除以及数据的Rebalance等操作。 Data:存储和检索数据 Coordinator:请求转发和合并检索结果 Ingest:转换输入的数据
增删改查原理
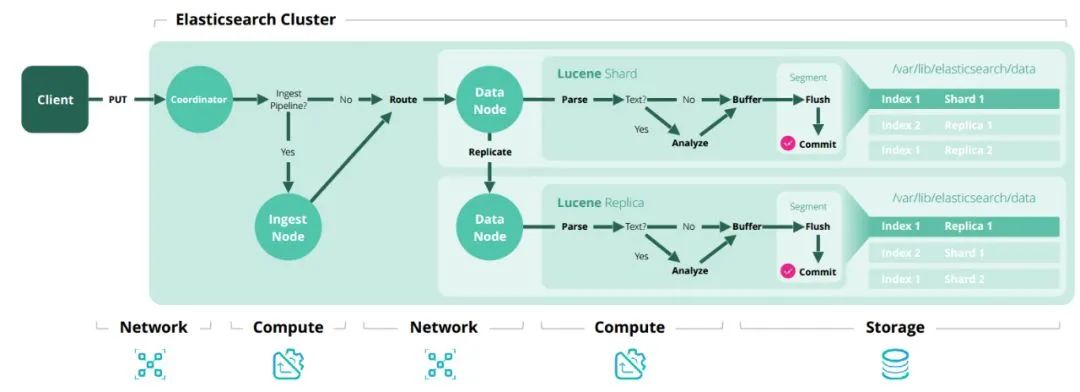
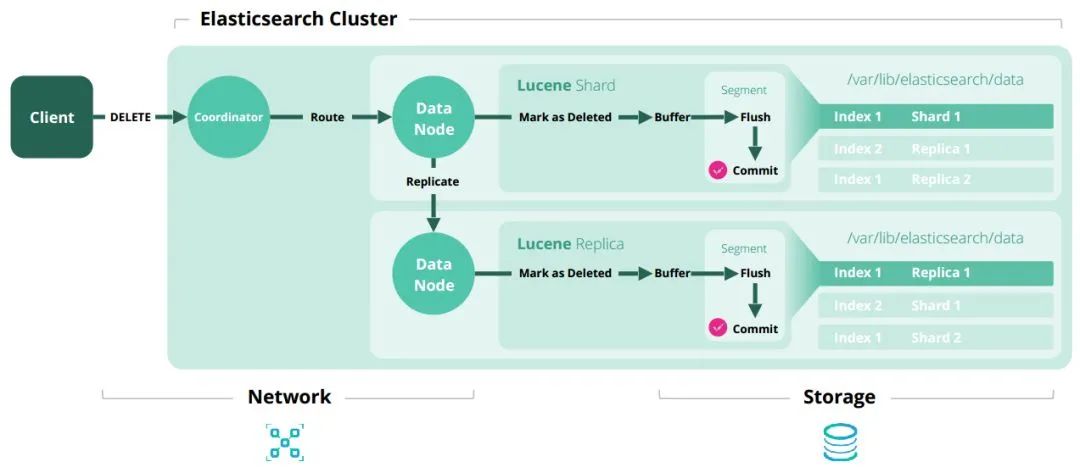
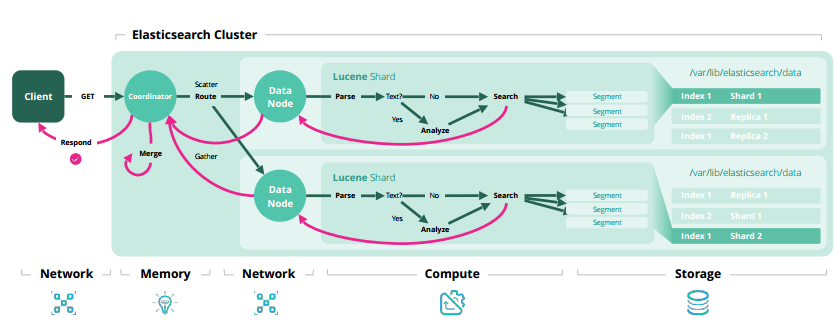
细节补充
倒排索引
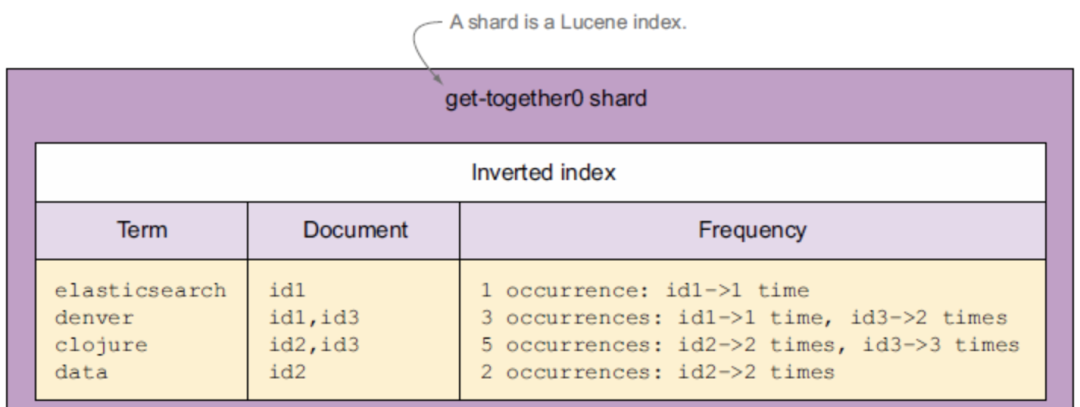
为什么全文检索中 ES 比 Mysql 快?
select field1, field2
from tbl1
where field2 = a
and field3 in (1,2,3,4)
这里如果 field2 和 field3 都建立了索引,理论上速度跟 es 差不多。es最多把 field2 和 field3 concat 起来,做到查询时只走一次索引来提高查询效率。
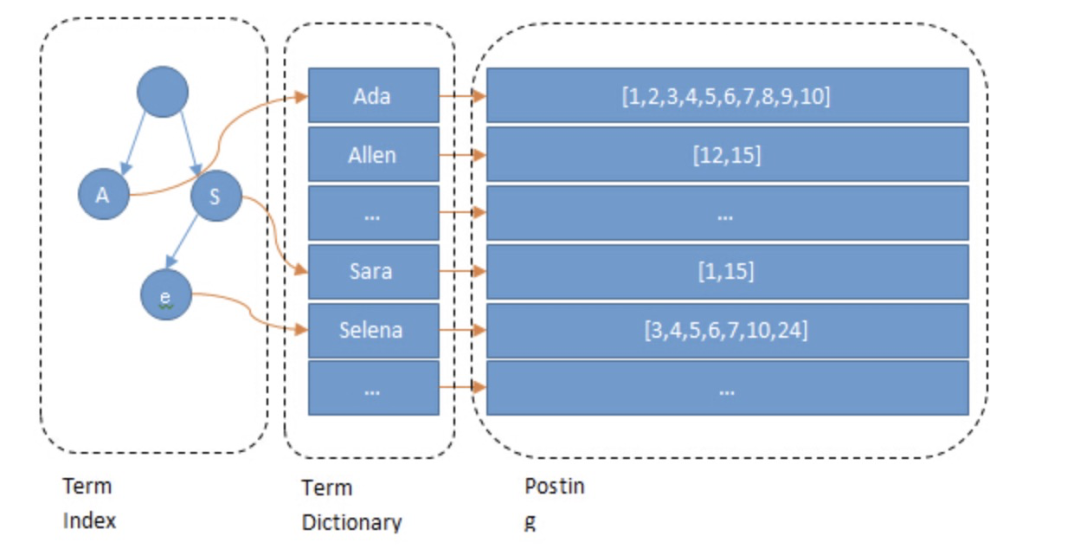
内存消耗大
目前触漫 ES 情况
适合:大批量数据的灵活计算,包括关联、机器学习、图计算、实时计算等。 不适合:小量数据的交互式计算。
Spark
架构原理
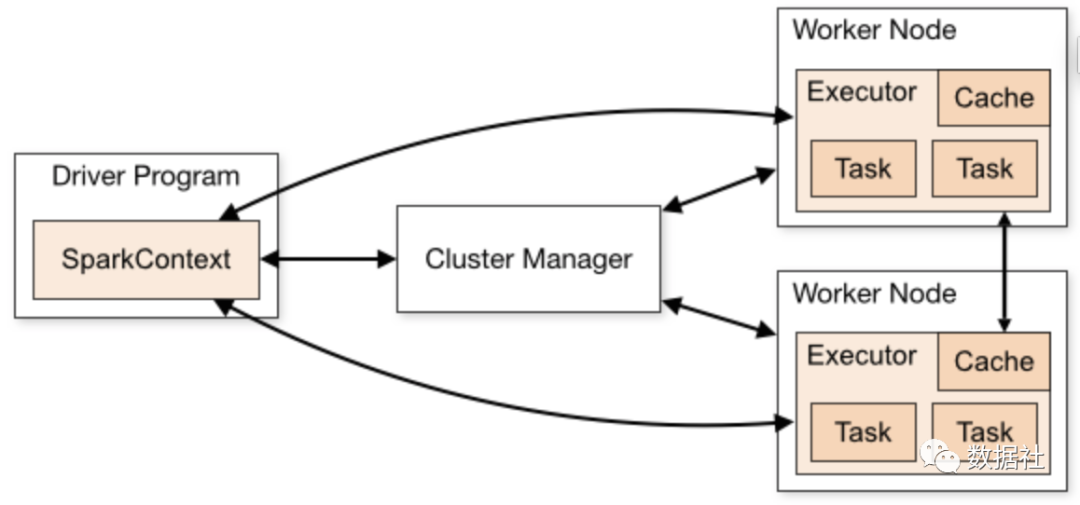
作业例子
object SparkSQLExample {def main(args: Array[String]): Unit = {// 创建 SparkSession,里面包含 sparkcontextval spark = SparkSession.builder().appName("Spark SQL basic example").getOrCreate()import spark.implicits._// 读取数据val df1 = spark.read.load("path1...")val df2 = spark.read.load("path2...")// 注册表df1.createOrReplaceTempView("tb1")df2.createOrReplaceTempView("tb2")// sqlval joinedDF = sql("""|select tb1.id, tb2.field|from tb1 inner join tb2|on tb1.id = tb2.id""".stripMargin)// driver 终端显示结果joinedDF.show()// 退出 sparkspark.stop()}}
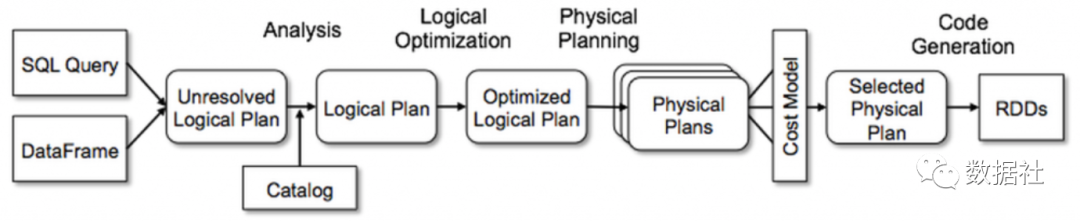
文档型数据库:大部分都不支持关联,因为效率低。关联基本都要全文档扫描。因为文档是 schemaless 的,并不确定某个文档是否有关联所需字段。而且个文档的读取都是整个对象的读取,并不会只读某个字段来减少内存开销。另外,这两个组件在内存中本身就有各自的数据结构来服务读写,所以额外的内存用于这类大开销计算也是不现实的。因此,HBase 本身只支持简单的过滤,不支持关联。ES 即便支持过滤、聚合,但依然不支持关联。 传统关系型数据库:可以完成较大数据关联,然而效率低,这主要是受到其大量的磁盘 IO、自身服务(读写、事务等、数据同步)的干扰。在真正大数据情况下,这关联还涉及数据在不同机器的移动,数据库需要维持其数据结构,如 BTree,数据的移动效率较低。 计算引擎: 基于内存:计算引擎留有大量内存空间专门用于计算,尽量减少磁盘 IO。 计算并行化 算法优化
BroadcastJoin:当一个大表和一个小表进行Join操作时,为了避免数据的Shuffle,可以将小表的全部数据分发到每个节点上。算法复杂度:O(n). ShuffledHashJoinExec:先对两个表进行hash shuffle,然后把小表变成map完全存储到内存,最后进行join。算法复杂度:O(n)。不适合两个表都很大的情况,因为其中一个表的hash部分要全部放到内存。 SortMergeJoinExec:先hash shuffle将两表数据数据相同key的分到同一个分区,然后sort,最后join。由于排序的特性,每次处理完一条记录后只需要从上一次结束的位置开始继续查找。算法复杂度:O(nlogn),主要来源于排序。适合大表join大表。之所以适合大表,是因为 join 阶段,可以只读取一部分数据到内存,但其中一块遍历完了,再把下一块加载到内存,这样关联的量就能突破内存限制了。
数据流动
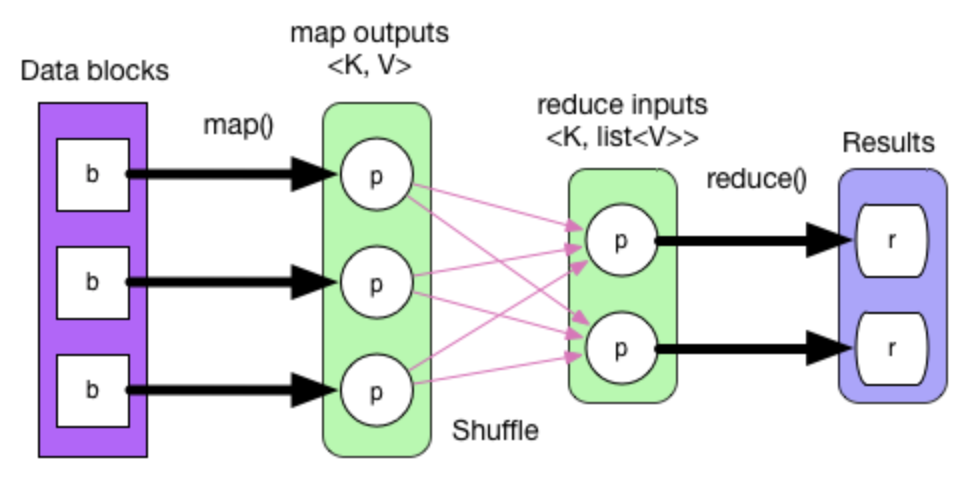
这是一张简单的数据流程图。描述了一个 WorkCount 的数据流向。其主要代码如下:
val textFile = sc.textFile("hdfs://...")val counts = textFile.map(word => (word, 1)).reduceByKey(_ + _)counts.saveAsTextFile("hdfs://...")
Flink
实时分析/BI指标:比如某天搞活动或新版本上线,需要尽快根据用户情况来调整策略或发现异常。 实时监控:通过实时统计日志数据来尽快发现线上问题。 实时特征/样本:模型预测和训练
架构原理
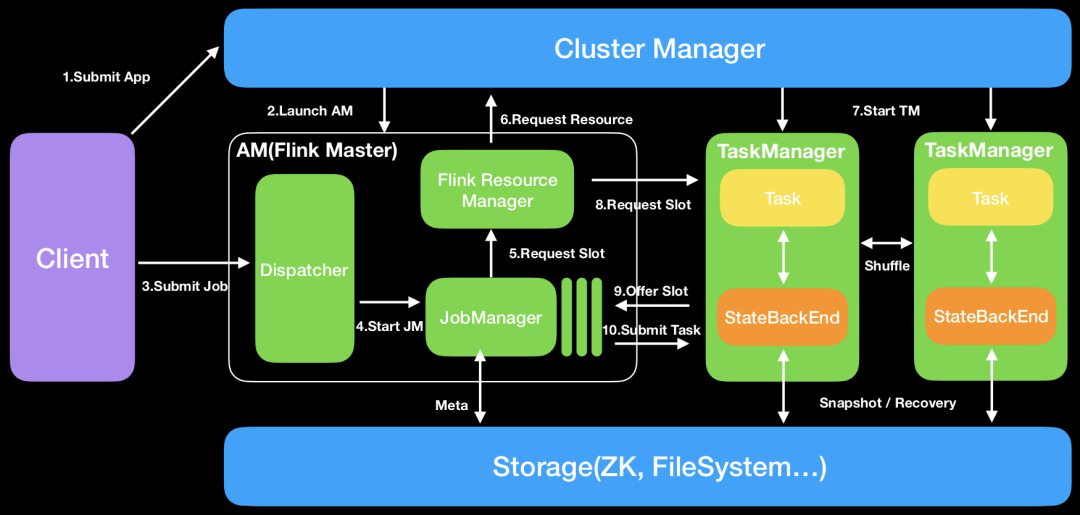
细节补充
保证数据刚好被处理一次,即便在计算过程中出现网络异常或者宕机。 event-time处理,即按照数据中的时间作为计算引擎的时间,这样即便数据上报出现一定的延迟,数据仍然可以被划分到对应的时间窗口。而且还能对一定时间内的数据顺序进行修正。 在版本升级,修改程序并行度时不需要重启。 反压机制,即便数据量极大,Flink 也可以通过自身的机制减缓甚至拒绝接收数据,以免程序被压垮。
拉模型 系统更加成熟,尤其是离线计算 生态更加完善
推模型 实时计算更优秀 阿里推动,正在迅速发展 生态对国内更为友好
小红书实时技术
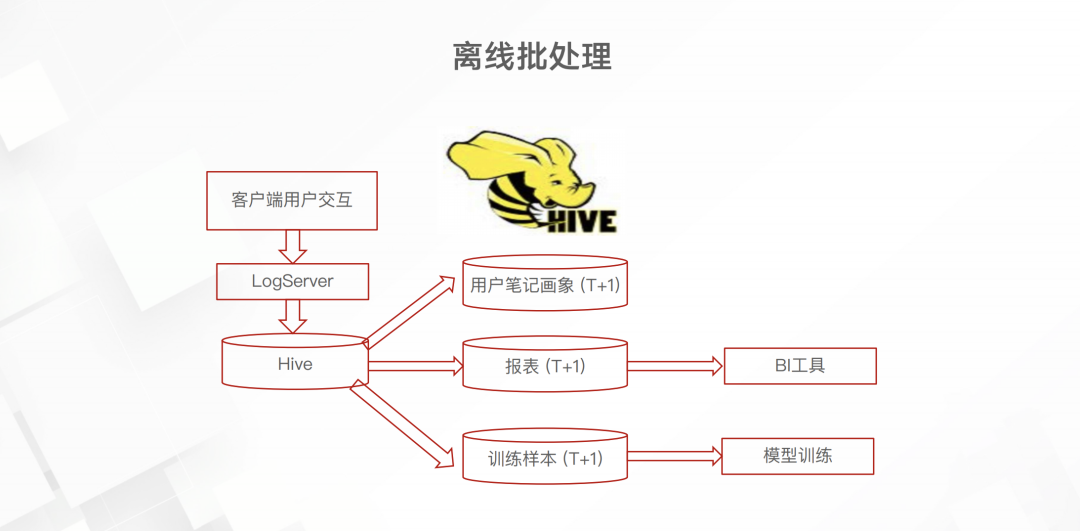
而后续的实时框架是这样的
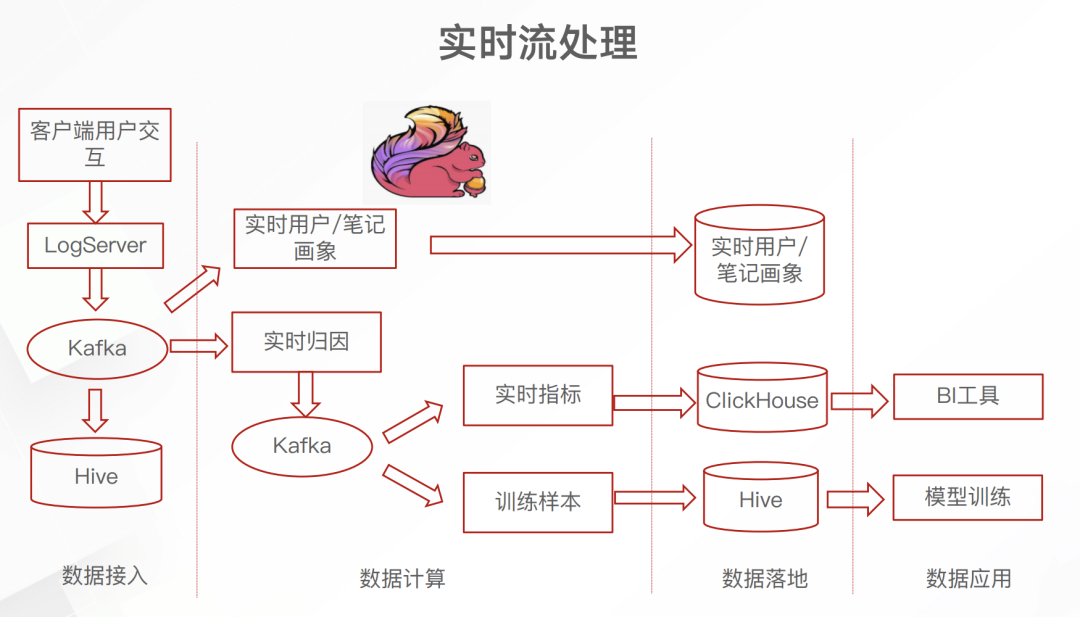
日志服务的埋点数据先进入 Kafka 这一消息队列里面。不太清楚为什么要加上 Kafka 这一中间件,或许当时并没有开源的 日志服务到Flink 的 connecter 吧。但总之,引入 Flink 之后就可以实时累计埋点中的数据,进而产生实时的画像、BI指标和训练数据了。下面介绍一下这个实时归因
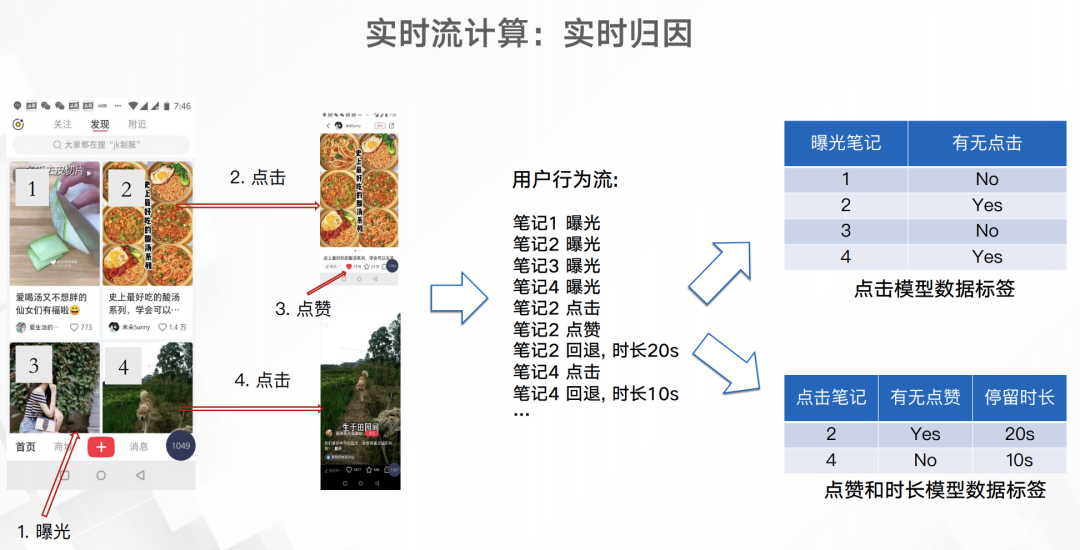
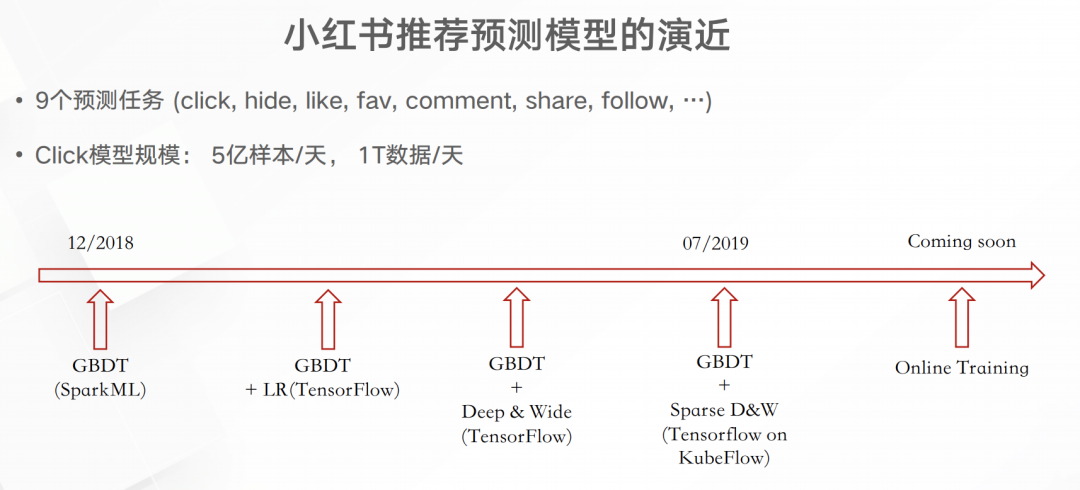
如上图所以,用户app屏幕展示了4个笔记,然后就会有4条曝光埋点,而如果点击笔记、点赞笔记以及从笔记中退出都会有相应的埋点。通过这些埋点就可以得出右面两份简单的训练或分析数据。这些数据跟原来已经积累的笔记/用户画像进行关联就能得出一份维度更多的数据,用于实时的分析或模型预测。实时模型训练这一块至少小红书在19年8月都还没有实现。下图是小红书推荐预测模型的演进
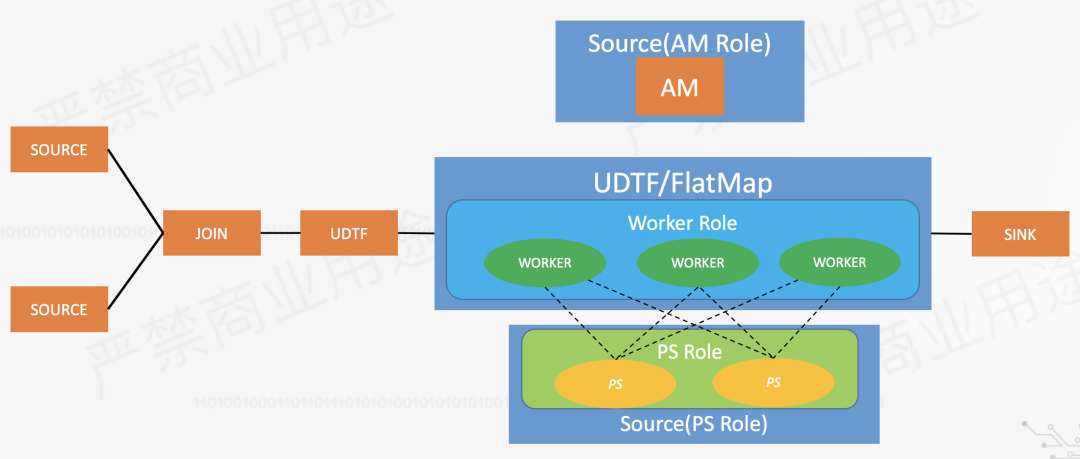
那么如何进行实时训练深度学习模型呢?以下是我的一些想法。借助一个阿里的开源框架flink-ai-extended。
Martin Kleppmann: “Designing Data-Intensive Applications”, O’Reilly Media, March 2017 Tom White: “Hadoop: The Definitive Guide”, 4th edition. O’Reilly Media, March 2015 胡争, 范欣欣: “HBase原理与实践”, 机械工业出版社, 2019年9月 朱锋, 张韶全, 黄明: “Spark SQL 内核剖析”, 电子工业出版社, 2018年8月 Fabian Hueske and Vasiliki Kalavri: “Stream Processing with Apache Flink”, O’Reilly Media, April 2019
再谈 HBase 八大应用场景:https://cloud.tencent.com/developer/article/1369824 Elasticsearch读写原理:https://blog.csdn.net/laoyang360/article/details/103545432 ES文章集:https://me.csdn.net/wojiushiwo987 MySQL和Lucene索引对比分析:https://www.cnblogs.com/luxiaoxun/p/5452502.html 深入浅出理解 Spark:环境部署与工作原理:https://mp.weixin.qq.com/s/IdrX4Hh1HQaJZx-VnB7XsQ
ES官方文档:https://www.elastic.co/guide/index.html Spark官方文档:http://spark.apache.org/docs/latest/ Flink官方文档:https://flink.apache.org/
基于Flink的高性能机器学习算法库 https://www.bilibili.com/video/av57447841?p=4 “Redefining Computation” https://www.bilibili.com/video/av42325467?p=3 Flink 实时数仓的应用 https://www.bilibili.com/video/av66782142 Flink runtime 核心机制剖析 https://www.bilibili.com/video/av42427050?p=4 小红书大数据在推荐中的应用 https://mp.weixin.qq.com/s/o7JM7DDkUNuGZEGKBtAmIw TensorFlow 与 Apache Flink 的结合 https://www.bilibili.com/video/av60808586/