有一张财务流水表,未分库分表,目前的数据量为9555695,分页查询使用到了limit,优化之前的查询耗时16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms),按照下文的方式调整SQL后,耗时347 ms (execution: 163 ms, fetching: 184 ms);
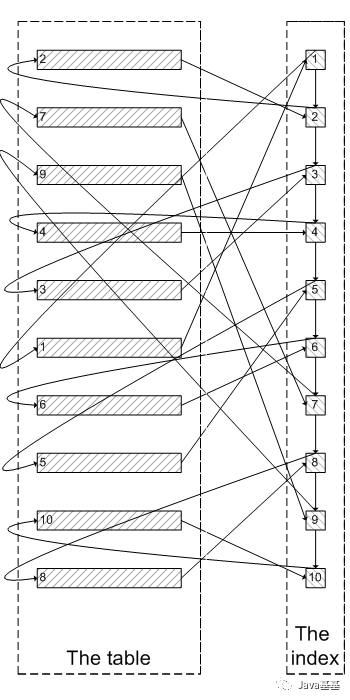
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
搜索公众号Linux中文社区后台回复“私房菜”,获取一份惊喜礼包。
我只能通过间接的方式来证实:
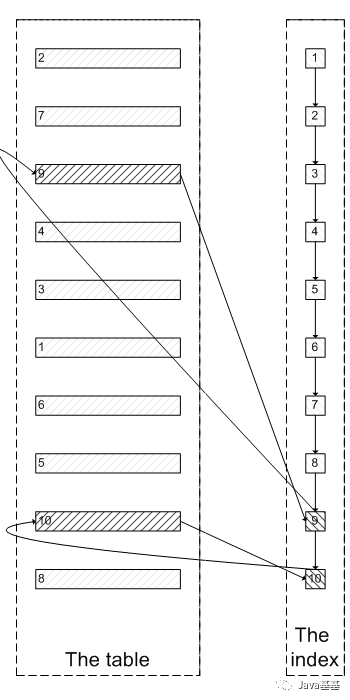
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5); 之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * fromtestwhere val=4limit300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name;Empty set (0.04 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name; +------------+----------+ | index_name | count(*) | +------------+----------+ | PRIMARY | 4098 | | val | 208 | +------------+----------+2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) ;为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown /usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name;
Empty set (0.03 sec)
运行sql:
mysql> select * fromtest a innerjoin (selectidfromtestwhere val=4limit300000,5) b on a.id=b.id; +---------+-----+--------+---------+ | id | val | source | id | +---------+-----+--------+---------+ | 3327622 | 4 | 4 | 3327622 | | 3327632 | 4 | 4 | 3327632 | | 3327642 | 4 | 4 | 3327642 | | 3327652 | 4 | 4 | 3327652 | | 3327662 | 4 | 4 | 3327662 | +---------+-----+--------+---------+ 5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name; +------------+----------+ | index_name | count(*) | +------------+----------+ | PRIMARY | 5 | | val | 390 | +------------+----------+ 2 rows in set (0.03 sec)