
一张900w的数据表,干脆把花费17s执行的SQL优化到300ms了
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包
真爱,请设置“星标”或点个“在看”

-- 优化前SQL
SELECT 各种字段
FROM `table_name`
WHERE 各种条件
LIMIT 0,10;
-- 优化后SQL
SELECT 各种字段
FROM `table_name` main_tale
RIGHT JOIN
(
SELECT 子查询只查主键
FROM `table_name`
WHERE 各种条件
LIMIT 0,10;
) temp_table ON temp_table.主键 = main_table.主键
一,前言
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
select * from test where val=4 limit 300000,5;的查询过程:
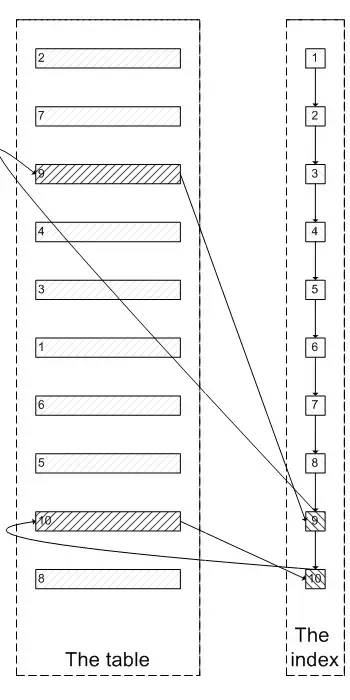
证实
select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。更多参考:索引很难么?带你从头到尾捋一遍MySQL索引结构,不信你学不会!select * from test a inner join (select id from test where val=4 limit 300000,5); 之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。select * from test where val=4 limit 300000,5mysql> select index_name,count(*) from
information_schema.INNODB_BUFFER_PAGE where
INDEX_NAME in('val','primary') and TABLE_NAME like '%test%'
group by index_name;Empty set (0.04 sec)
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+|
3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+2 rows in set (0.04 sec)
select * from test a inner join (select id from test where val=4 limit 300000,5) ;为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。参考资料:
1.https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
2.https://dev.mysql.com/doc/refman/5.7/en/innodb-information-schema-buffer-pool-tables.html
---END--- 重磅!码农突围-技术交流群已成立 扫码可添加码农突围助手,可申请加入码农突围大群和细分方向群,细分方向已涵盖:Java、Python、机器学习、大数据、人工智能等群。 一定要备注:开发方向+地点+学校/公司+昵称(如Java开发+上海+拼夕夕+猴子),根据格式备注,可更快被通过且邀请进群 ▲长按加群 推荐阅读
• GitHub宣布已将所有代码永久封存于北极地底1000年!网友炸锅了:我写的bug终于能流传永世了! • 优秀!94年出生的她,受聘为深圳大学正教授! • 使用 IDEA 几分钟就重构了同事800 行"又臭又长" 的类!真香! • 雷军1994年写的老代码曝光,被称像诗一样优雅 • 推荐 33 个 IDEA 最牛配置,好用到飞起来! • 同事:你居然还在用 try catch 处理异常?有点Low啊 最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 BAT 领取,更多内容陆续奉上。 如有收获,点个在看,诚挚感谢 明天见(。・ω・。)ノ♡
评论