
用Python来理一理红楼梦里的那些关系
教程、案例源码、学习资料、读者群
请访问: python666.cn
大家好,欢迎来到 Crossin的编程教室 !
今天,我们一起用 Python 来理一理红楼梦里的那些关系。
不要问我为啥是红楼梦,而不是水浒三国或西游,因为我也坚定地认为,红楼才是无可争议的中国古典小说只巅峰,且不接受反驳!而红楼梦也是我多次反复品读的为数不多的小说,对它的感情也是最深的。
好了,不酸了,开干。
数据准备
红楼梦 TXT 文件一份
金陵十二钗 + 贾宝玉 人物名称列表
人物列表内容如下:
宝玉 nr
黛玉 nr
宝钗 nr
湘云 nr
凤姐 nr
李纨 nr
元春 nr
迎春 nr
探春 nr
惜春 nr
妙玉 nr
巧姐 nr
秦氏 nr
这份列表,同时也是为了做分词时使用,后面的 nr 就是人名的意思。
数据处理
读取数据并加载词典
with open("红楼梦.txt", encoding='gb18030') as f:
honglou = f.readlines()
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]
这样,我们就把红楼梦读取到了 honglou 这个变量当中,同时也通过 load_userdict 将我们自定义的词典加载到了 jieba 库中。
对文本进行分词处理并提取
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("贾妃", "元春")
h.replace("李宫裁", "李纨")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
首先,因为文中"贾妃", "元春","李宫裁", "李纨" 混用严重,所以这里直接做替换处理。
然后使用 jieba 库提供的 pseg 工具来做分词处理,会返回每个分词的词性。
之后做判断,只有符合要求且在我们提供的字典列表里的分词,才会保留。
一个人每出现一次,就会增加一,方便后面画关系图时,人物 node 大小的确定。
对于存在于我们自定义词典的人名,保存到一个临时变量当中 tmpNames。
处理人物关系
for name in tmpNames:
for name1 in name:
for name2 in name:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] += 1
对于出现在同一个段落中的人物,我们认为他们是关系紧密的,每同时出现一次,关系增加1.
保存到文件
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")
文件1:人物关系表,包含首先出现的人物、之后出现的人物和一同出现次数
文件2:人物比重表,包含该人物总体出现次数,出现次数越多,认为所占比重越大。
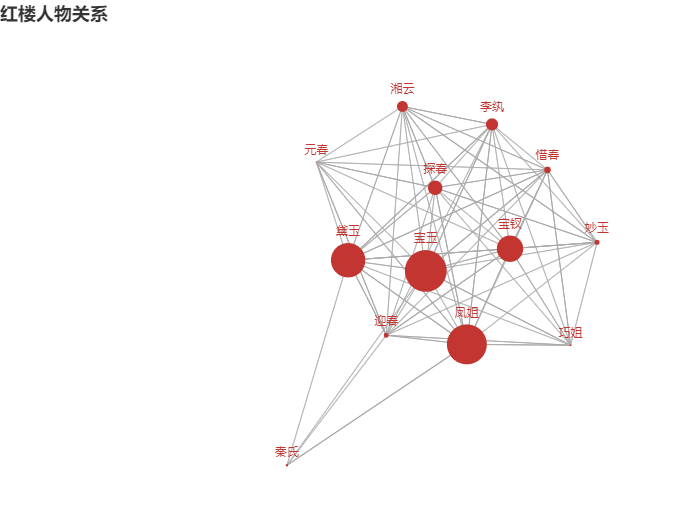
制作关系图表
使用 pyecharts 作图
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "宝玉":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="红楼人物关系"))
)
return g
首先把两个文件读取成列表形式
对于“宝玉”,由于其占比过大,如果统一进行缩放,会导致其他人物的 node 过小,展示不美观,所以这里先做了一次缩放
最后得出的关系图
所有代码已经上传至 Github:
https://github.com/zhouwei713/data_analysis/tree/master/honglou
最后,我还准备了一份更加全面的红楼人物字典,可以在代码仓库中找到-“renwu_total”,感兴趣的小伙伴也可以尝试下,制作一个全人物的关系图。
作者:萝卜大杂烩
来源:萝卜大杂烩
Crossin的第2本书《码上行动:利用Python与ChatGPT高效搞定Excel数据分析》已经上市了。
点此查看上一本《码上行动:零基础学会Python编程》介绍

本书从 Python 和 Excel 结合使用的角度讲解处理分析数据的思路、方法与实战应用。不论是希望从事数据分析岗位的学习者,还是其他职业的办公人员,都可以通过本书的学习掌握 Python 分析数据的技能。书中创新性地将 ChatGPT 引入到教学当中,用 ChatGPT 答疑并提供实训代码,并介绍了使用 ChatGPT 辅助学习的一些实用技巧,给学习者带来全新的学习方式。
公众号的读者朋友们购买后可在后台联系我,加入读者交流群,Crossin会为你开启陪读模式,解答你在阅读本书时的一切疑问。
感谢转发和点赞的各位~
_往期文章推荐_
一文搞懂Python私有属性&私有方法
如需了解付费精品课程及教学答疑服务
请在Crossin的编程教室内回复: 666