
TTFNet:改进CenterNet,训练缩短7倍
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
导读
本文是对CenterNet的一种改进,主要是增加了训练时参与回归的样本,提升了收敛速度,加快了训练时间,同时使用了椭圆高斯核来代替CenterNet中的圆形高斯核,感觉更加合理。
Training-Time-Friendly Network for Real-Time Object Detection
摘要:目前的物体检测器很少既有短的训练时间,短的推理时间,以及同时具有高的准确率。为了找到这些的平衡点,我们提出了一个Training-Time-Friendly Network(TTFNet)。在这个工作中,我们使用了light-head,单阶段,anchor free的设计,来得到快速的推理速度。然后,我们聚焦于缩短训练时间,我们发现,从标注框中编码出更多的训练样本和增大batch size可以得到相似的效果。最后,我们介绍了一种使用高斯核来编码训练样本的方法。另外,我们还设计了启发性的样本权重来更好的利用信息。
代码:https://github.com/ZJULearning/ttfnet
1. 介绍
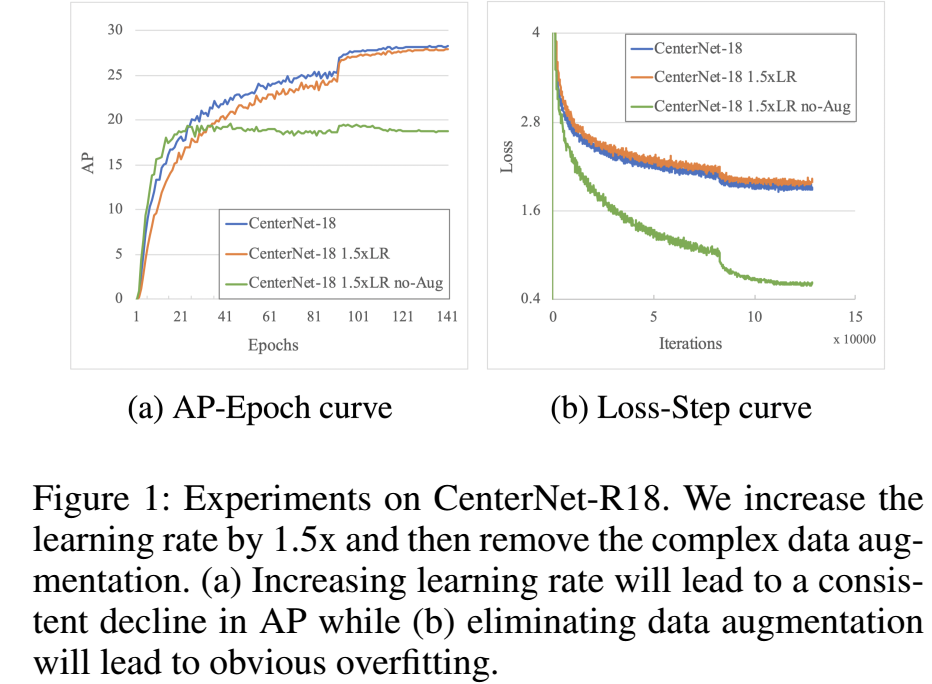
为了加速推理,研究人员致力于在保持准确率的情况下,使用简单的检测头和后处理。CenterNet就具有很短的推理时间,几乎和backbone的时间是一样的,但是,这个方法的训练时间确很长,原因在于这个网络太过于简单了,因此训练起来很困难,训练的时候非常依赖于数据增强和长训练时间。比如,在COCO上,CenterNet需要140个epochs,而有些方法只需要12个epochs。
本文致力于在保持模型推理时间和performance的情况下,缩短训练时间。之前的研究表明,如果使用大的batch size的话,可以线性同步增大学习率。我们发现,从标注框中编码出更多的训练样本和增大batch size可以得到相似的效果。由于编码特征和计算loss的时间可以几乎忽略不计,因此,可以在不增加任何额外计算的情况下,加快收敛速度。相比之下,CenterNet只用到了中心点一个点来进行尺寸的回归,并没有利用到目标中心附近的信息,这是训练慢的主要原因。
为了加速训练,我们提出了一个使用高斯核来编码定位和回归训练样本的方法。这使得网络可以更好的利用标注框来产生更多的监督信息,这样可以更快的收敛。具体来说,我们构建了一个围绕着目标中心的区域,训练样本从这个区域中密集采样,然后使用高斯概率值作为回归训练样本的权重。我们还进一步使用了归一化来利用大框的信息,同时可以保留小框的信息。我们的方法可以减少低质量的训练样本,同时,不需要FPN之类的组件。另外,也不需要预测offset来修正结果,更加的高效。
相比于CenterNet,我们的方法可以减少7倍的训练时间,我们的主要贡献如下:
我们讨论和验证了batch size和标注框编码出的样本数量之间的关系,另外,我们的实验也验证了CenterNet训练慢的主要原因。 我们提出了一个新的方法,利用高斯核来为定位和回归生成训练样本。 我们的方法在保持了推理时间和performance的前提下,可以稳定的提升7倍的训练速度。 我们的方法在资源受限的条件下可用,特别适合时间敏感的任务,如NAS。
2. 动机
我们发现,编码更多的训练样本和增大batch size具有相似的作用,两者都可以提供更多的监督信号。我们可以近似得到这样的结论,当每个mini batch中的训练样本数量乘以k,学习率也可以乘上,其中。
CenterNet的推理速度很快,但是训练时间很长,在训练时需要复杂的数据增强,这会导致收敛慢,为了搞清楚收敛慢的原因,我们去掉了数据增强,增大了学习率。结果如图1,增大学习率并不能加快收敛,去掉了数据增强会使得performance下降很多。我们认为,CenterNet收敛慢,主要是因为在训练的时候,在回归坐标的时候,每个目标只使用了一个点去回归,这使得CenterNet强依赖数据增强,而且训练时间长。
3. 方法
CenterNet将物体检测看成是2个部分,中心点的定位和尺寸的回归,对于定位,它使用了高斯核来产生一个heatmap,让网络去生成在目标周围具有高激活值的结果。对于回归,它将物体中心点作为训练样本,去回归物体的宽和高,它还回归了一个offset,用来弥补降采样的误差。由于最后能生成在物体中心具有更高激活值的heatmap,因此,可以不需要耗时的NMS等后处理操作。
我们对于定位,也采用了类似的方式,但是,我们考虑了物体的长宽比,而原来的CenterNet是没有考虑长宽比的。
对于尺寸的回归,主流的方法是将物体框中的所有像素或者是部分像素作为训练样本,而我们将物体框中的高斯核部分作为训练样本,另外,我们还为这些样本添加了权重,更好的利用了信息。注意,我们的方法不需要额外的预测来纠正定位误差,更加的高效。总体结构如图2。

训练中的高斯核
我们用r来表示最后特征图的stride,我们用α和β分别控制高斯核的尺寸。
物体定位
给定第m个标注框的类别是,先将这个标注框线性映射到特征图的尺寸,高斯核为,其中,,这里α=0.54。
高斯分布的峰值,也就是框的中心点,作为正样本,而其他作为负样本,我们使用modified focal loss:

这里,我们采用,。
尺寸回归
对于尺寸回归,我们使用β来控制高斯核的大小,我们也可以将α和β设置成同样的大小,特征图中的非0区域叫做高斯区域,如图3。高斯区域中的每个点都是一个回归样本,回归的目标是当前点距离4个边的距离,用一个4d向量来表示,因此,预测框可以表示为:

这里,s是一个固定的尺度值,这里取s=16,是为了方便收敛。注意,这里的预测框是在原始图像尺度上的,而不是特征图尺度上的。
如果像素点不在高斯区域内,训练时忽略。如果某个像素点属于多个高斯区域,目标值设定为更小的那个区域。我们使用GIoU来计算Loss:

这里,是样本权重。
由于目标的尺度各不相同,大的目标可能产生几千个样本,小的目标可能只有几个样本,如果直接训练的话,小目标的loss会被淹没掉,这使得小目标检测变得困难。样本权重是非常重要的:
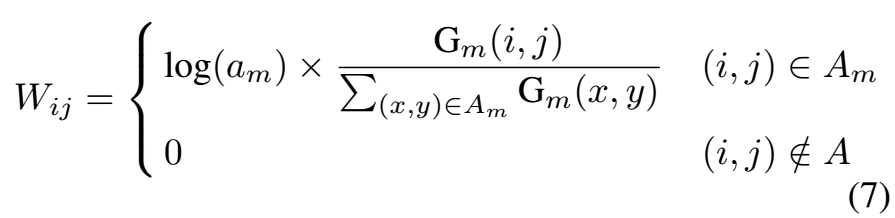
其作用会在后面的实验中表明。

总的Loss
总的loss包括了定位loss和回归loss,定位loss权重为1.0,回归loss权重为5.0。
总体设计
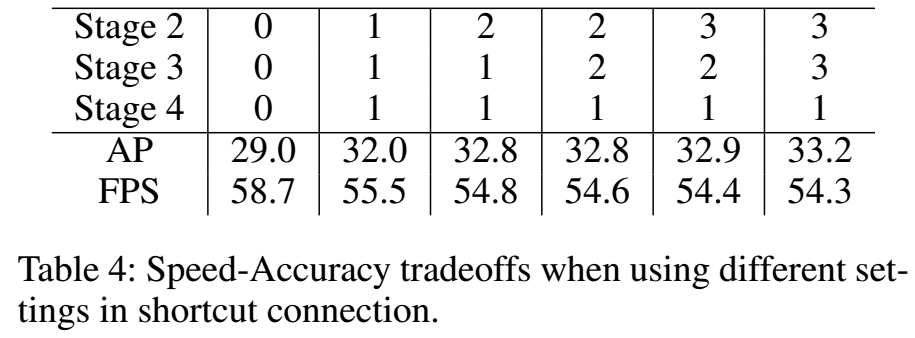
TTFNet的总体结构如图2,我们的方法在大物体和中等物体的时候,可以很有效的利用标注信息,但是对于小物体则提升不大,因此为了提升小目标的能力,我们从主干上增加了short cut到高分辨率特征图上。
4. 实验
消融实验:
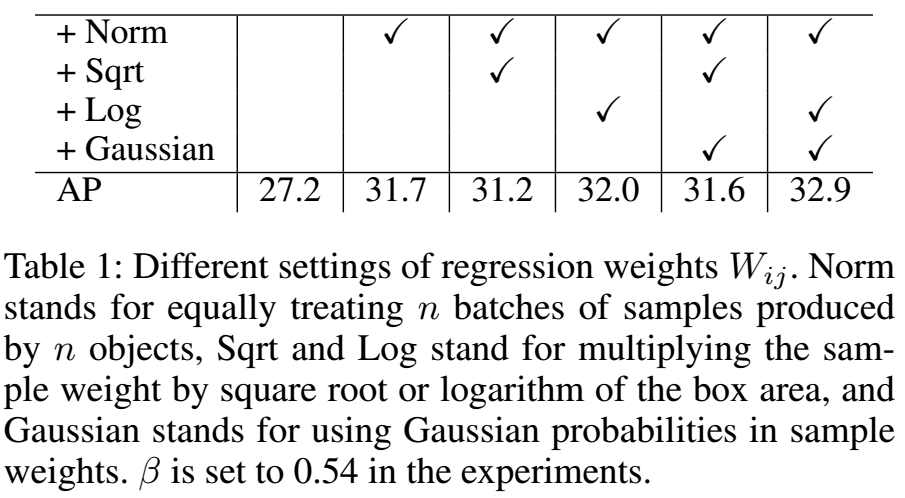
高斯核在回归中的作用:
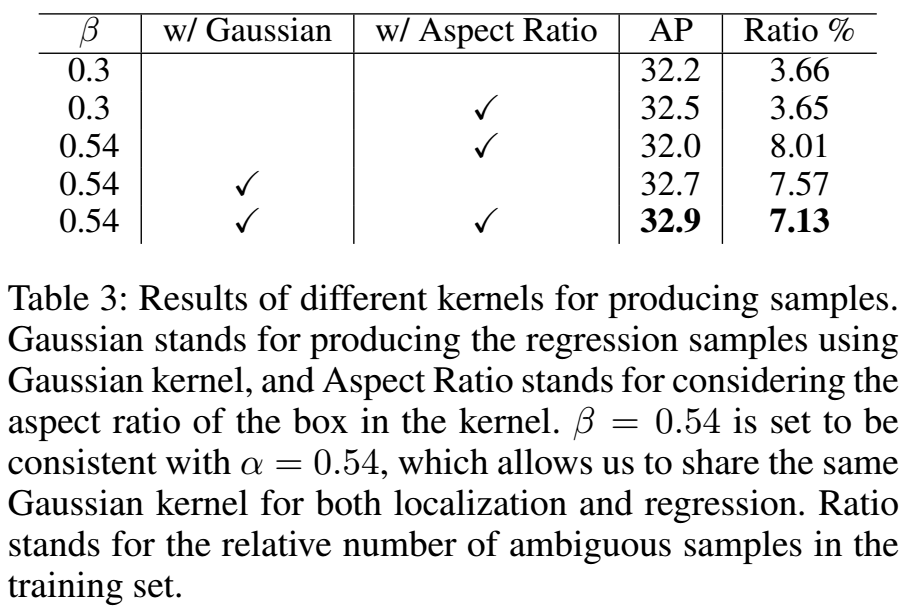
高斯核的大小由β来控制,β越大,可利用的标注信息越多,同时低质量的样本也越多,不同β的效果:

使用长宽比生成高斯核的作用,使用长宽比确实要好一些:
shortcut连接的作用,shortcut和上采样后的层的连接是通过3x3卷积实现的,表中的数字表示3x3卷积的数量:
样本数量以及学习率的作用:

不使用预训练模型,从头训练的结果:

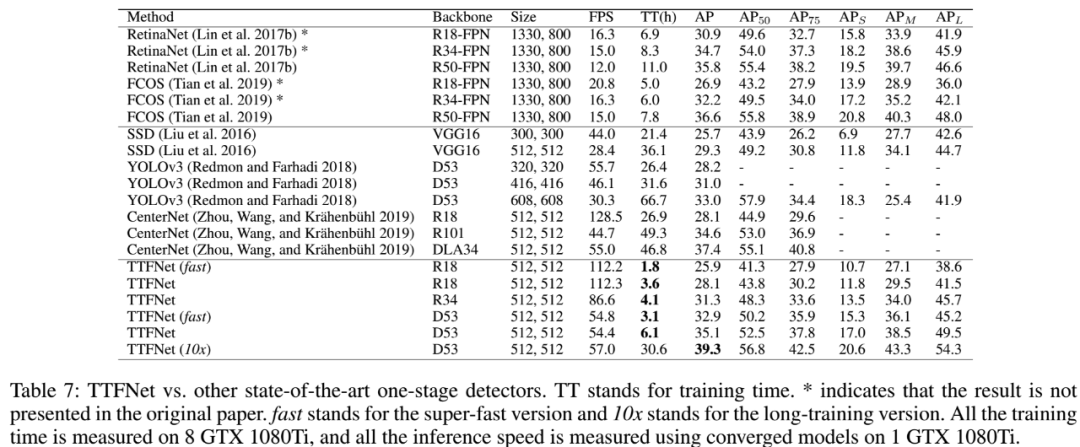
和其他方法的对比:
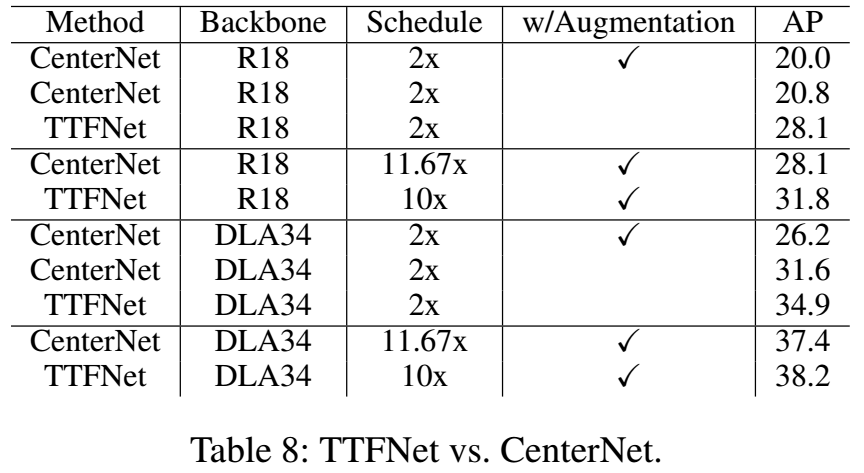
和CenterNet的更多对比:

论文链接:https://arxiv.org/abs/1909.00700
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、NeRF、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
