
快手基于 RocketMQ 的在线消息系统建设实践
为什么建设在线消息系统
业务希望个别消费失败以后可以重试,并且不堵塞后续其它消息的消费。 业务希望消息可以延迟一段时间再投递。 业务需要发送的时候保证数据库操作和消息发送是一致的(也就是事务发送)。 为了排查问题,有的时候业务需要一定的单个消息查询能力。
部署模式和落地策略
大集群 vs 小集群 选择副本数 同步刷盘 vs 异步刷盘 同步复制 vs 异步复制 SSD vs 机械硬盘
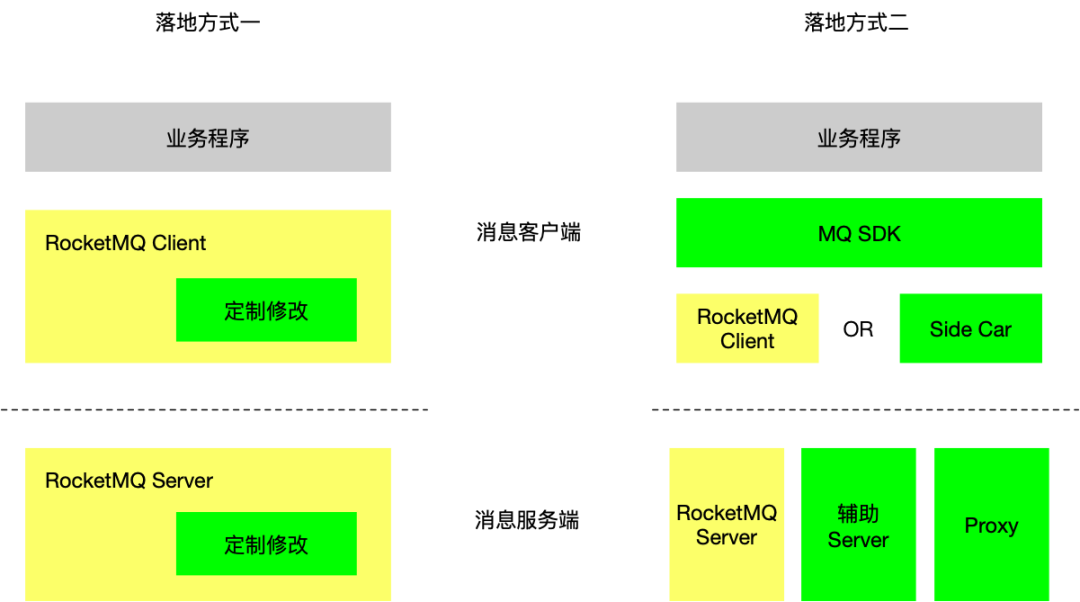
客户端封装策略
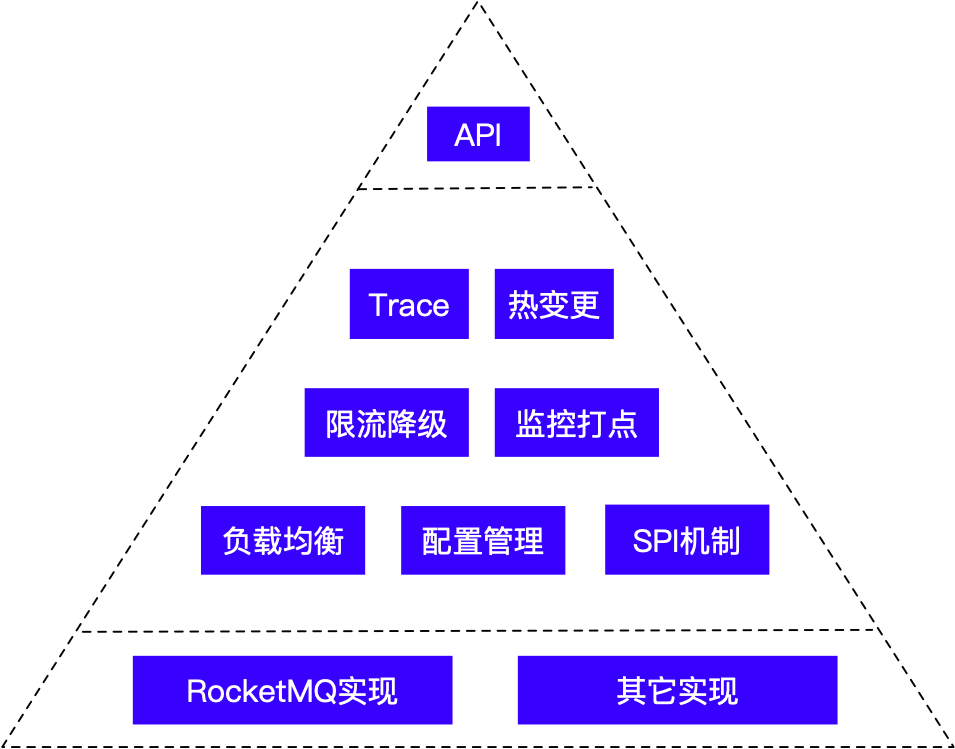
集群负载均衡 & 机房灾备
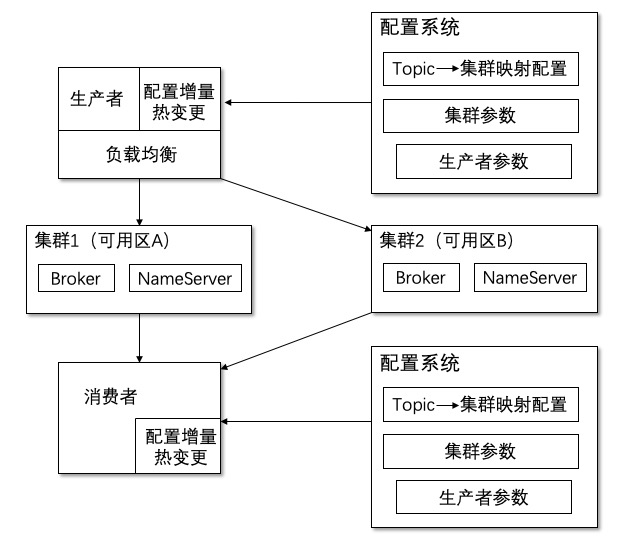
千万级 OPS
灵活的权重调整策略
健康检查支持/事件通知
并发度控制(自动降低响应慢的服务器的请求数)
资源优先级(类似 Envoy,实现本地机房优先,或是被调服务器很多的时候选取一个子集来调用)
自动优先级管理
增量热变更
多样的消息功能
延迟消息
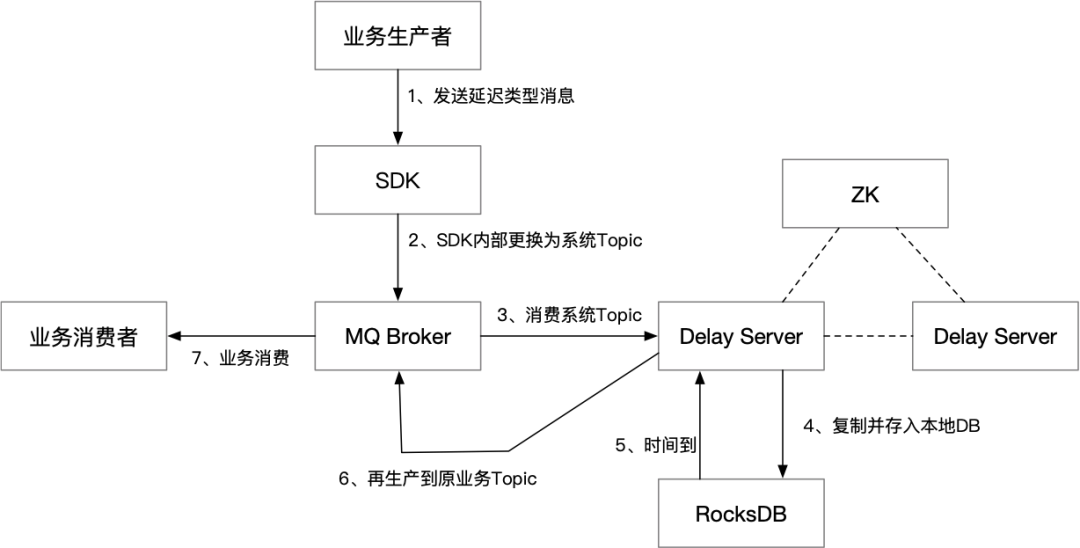
事务消息
transientStorePoolEnable 这个参数必须保持默认值 false,否则会有严重的问题。 endTransactionThreadPoolNums是事务消息二阶段处理线程大小,sendMessageThreadPoolNums 则指定一阶段处理线程池大小。如果二阶段的处理速度跟不上一阶段,就会造成二阶段消息丢失导致大量回查,所以建议 endTransactionThreadPoolNums 应该大于 sendMessageThreadPoolNums,建议至少 4 倍。 useReentrantLockWhenPutMessage 设置为 true(默认值是 false),以免线程抢锁出现严重的不公平,导致二阶段处理线程长时间抢不到锁。 transactionTimeOut 默认值 6 秒太短了,如果事务执行时间超过 6 秒,就可能导致消息丢失。建议改到 1 分钟左右。
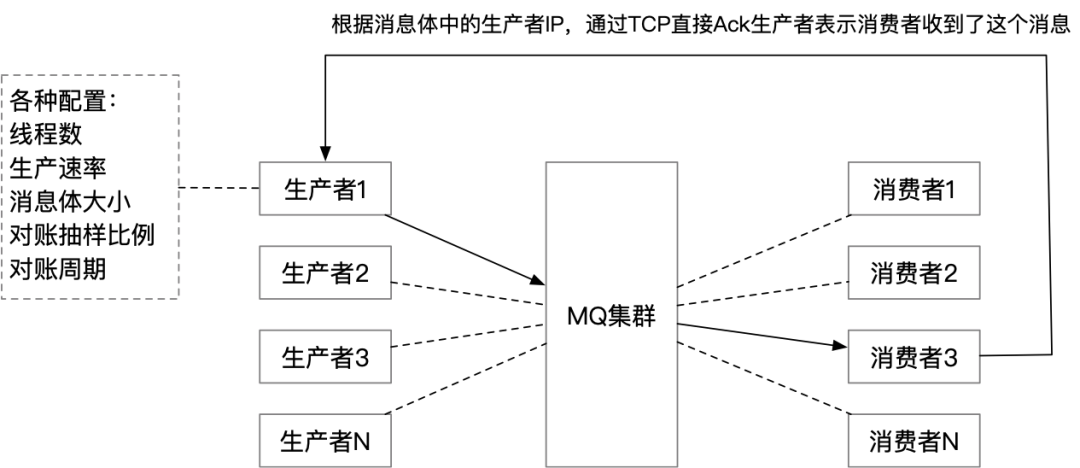
分布式对账监控
发送成功 | 成功 |
刷盘超时 | |
Slave 超时 | |
Slave 不可用 | |
发送失败 | 具体错误码 |
收到消息 消息丢失(或超时未收到消息) 重复收到消息 消息生成到最终消费的时间差 ACK 生产者失败(由消费者打点)
性能优化

评论