基于 Prometheus 的监控系统实践

单位时间接收到的请求数量 单位时间内请求的成功率/失败率 请求的平均处理耗时
支持 PromQL(一种查询语言),可以灵活地聚合指标数据
部署简单,只需要一个二进制文件就能跑起来,不需要依赖分布式存储
Go 语言编写,组件更方便集成在同样是Go编写项目代码中
原生自带 WebUI,通过 PromQL 渲染时间序列到面板上
生态组件众多,Alertmanager,Pushgateway,Exporter……
使用基础 Unit(如 seconds 而非 milliseconds)
指标名以 application namespace 作为前缀,如:
process_cpu_seconds_total
http_request_duration_seconds
用后缀来描述 Unit,如:
http_request_duration_seconds
node_memory_usage_bytes
http_requests_total
process_cpu_seconds_total
foobar_build_info
Prometheus 提供了以下基本的指标类型:
Counter:代表一种样本数据单调递增的指标,即只增不减,通常用来统计如服务的请求数,错误数等。
Gauge:代表一种样本数据可以任意变化的指标,即可增可减,通常用来统计如服务的CPU使用值,内存占用值等。
Histogram 和 Summary:用于表示一段时间内的数据采样和点分位图统计结果,通常用来统计请求耗时或响应大小等。
Prometheus 是基于时间序列存储的,首先了解一下什么是时间序列,时间序列的格式类似于(timestamp,value)这种格式,即一个时间点拥有一个对应值,例如生活中很常见的天气预报,如:[(14:00,27℃),(15:00,28℃),(16:00,26℃)],就是一个单维的时间序列,这种按照时间戳和值存放的序列也被称之为向量(vector)。

每一组唯一的标签集合对应着一个唯一的向量(vector),也可叫做一个时间序列(Time Serie),当在某一个时间点来看它时,它是一个瞬时向量(Instant Vector),瞬时向量的时序只有一个时间点以及它对于的一个值,比如:今天 12:05:30 时服务器的 CPU 负载;而在一个时间段来看它时,它是一个范围向量(Range Vector),范围向量对于着一组时序数据,比如:今天11:00到12:00时服务器的CPU负载。
类似的,可以通过指标名和标签集来查询符合条件的时间序列:
http_requests{host="host1",service="web",code="200",env="test"}
查询结果会是一个瞬时向量:
http_requests{host="host1",service="web",code="200",env="test"} 10http_requests{host="host2",service="web",code="200",env="test"} 0http_requests{host="host3",service="web",code="200",env="test"} 12
而如果给这个条件加上一个时间参数,查询一段时间内的时间序列:
http_requests{host="host1",service="web",code="200",env="test"}[:5m]
结果将会是一个范围向量:
http_requests{host="host1",service="web",code="200",env="test"} 0 4 6 8 10http_requests{host="host2",service="web",code="200",env="test"} 0 0 0 0 0http_requests{host="host3",service="web",code="200",env="test"} 0 2 5 9 12
rate(http_requests{host="host1",service="web",code="200",env="test"}[:5m])
比如要求最近5分钟请求的增长量,可以用以下的 PromQL:
increase(http_requests{host="host1",service="web",code="200",env="test"}[:5m])
要计算过去10分钟内第90个百分位数:
histogram_quantile(0.9, rate(employee_age_bucket_bucket[10m]))
在 Prometheus 中,一个指标(即拥有唯一的标签集的 metric)和一个(timestamp,value)组成了一个样本(sample),Prometheus 将采集的样本放到内存中,默认每隔2小时将数据压缩成一个 block,持久化到硬盘中,样本的数量越多,Prometheus占用的内存就越高,因此在实践中,一般不建议用区分度(cardinality)太高的标签,比如:用户IP,ID,URL地址等等,否则结果会造成时间序列数以指数级别增长(label数量相乘)。
除了控制样本数量和大小合理之外,还可以通过降低 storage.tsdb.min-block-duration 来加快数据落盘时间和增加 scrape interval 的值提高拉取间隔来控制 Prometheus 的占用内存。
relabel_configs:- source_labels: [__address__]modulus: 3target_label: __tmp_hashaction: hashmod- source_labels: [__tmp_hash]regex: $(PROM_ID)action: keep
relabel_configs:- source_labels: ["__meta_consul_dc"]regex: "dc1"action: keep
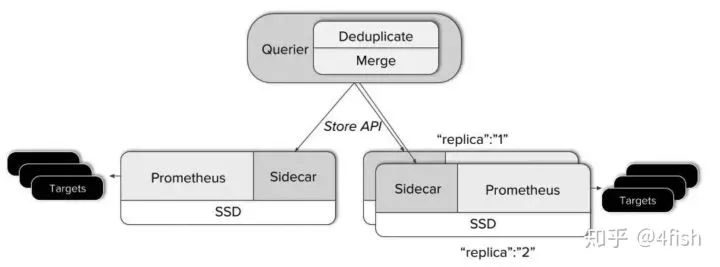
Querier 收到一个请求时,它会向相关的 Sidecar 发送请求,并从他们的 Prometheus 服务器获取时间序列数据。 它将这些响应的数据聚合在一起,并对它们执行 PromQL 查询。它可以聚合不相交的数据也可以针对 Prometheus 的高可用组进行数据去重。
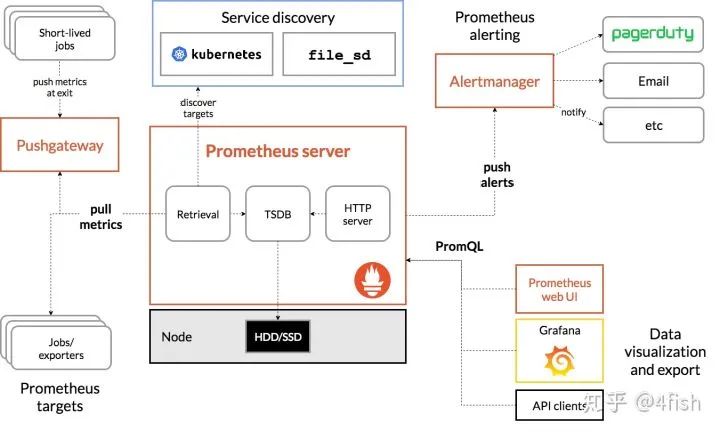
Pushgateway可以替代拉模型来作为指标的收集方案,但在这种模式下会带来许多负面影响:
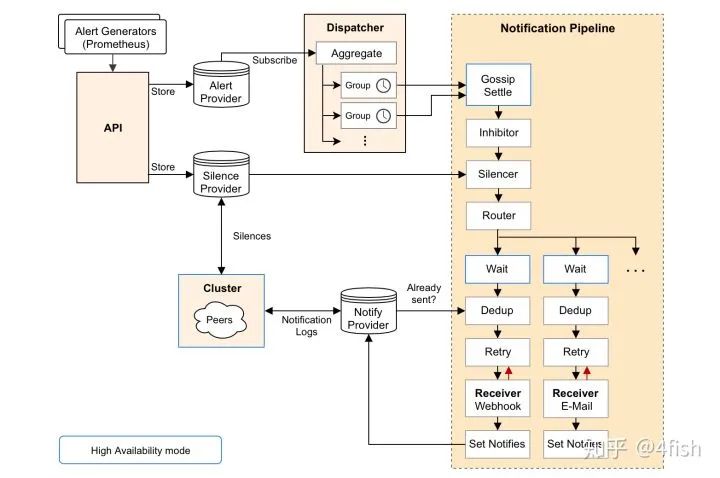
最后再来聊一下Alertmanager,简单说 Alertmanager 是与 Prometheus 分离的告警组件,主要接收 Promethues 发送过来的告警事件,然后对告警进行去重,分组,抑制和发送,在实际中可以搭配 webhook 把告警通知发送到企业微信或钉钉上,其架构图如下:
为了部署 Prometheus 实例,需要声明 Prometheus 的 StatefulSet,Pod 中包括了三个容器,分别是 Prometheus 以及绑定的 Thanos Sidecar,最后再加入一个 watch 容器,来监听 prometheus 配置文件的变化,当修改 ConfigMap 时就可以自动调用Prometheus 的 Reload API 完成配置加载,这里按照之前提到的数据分区的方式,在Prometheus 启动前加入一个环境变量 PROM_ID,作为 Relabel 时 hashmod 的标识,而 POD_NAME 用作 Thanos Sidecar 给 Prometheus 指定的 external_labels.replica 来使用:
apiVersion: apps/v1kind: StatefulSetmetadata:name: prometheuslabels:app: prometheusspec:serviceName: "prometheus"updateStrategy:type: RollingUpdatereplicas: 3selector:matchLabels:app: prometheustemplate:metadata:labels:app: prometheusthanos-store-api: "true"spec:serviceAccountName: prometheusvolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-datahostPath:path: /data/prometheus- name: prometheus-config-sharedemptyDir: {}containers:- name: prometheusimage: prom/prometheus:v2.11.1args:- --config.file=/etc/prometheus-shared/prometheus.yml- --web.enable-lifecycle- --storage.tsdb.path=/data/prometheus- --storage.tsdb.retention=2w- --storage.tsdb.min-block-duration=2h- --storage.tsdb.max-block-duration=2h- --web.enable-admin-apiports:- name: httpcontainerPort: 9090volumeMounts:- name: prometheus-config-sharedmountPath: /etc/prometheus-shared- name: prometheus-datamountPath: /data/prometheuslivenessProbe:httpGet:path: /-/healthyport: http- name: watchimage: watchargs: ["-v", "-t", "-p=/etc/prometheus-shared", "curl", "-X", "POST", "--fail", "-o", "-", "-sS", "http://localhost:9090/-/reload"]volumeMounts:- name: prometheus-config-sharedmountPath: /etc/prometheus-shared- name: thanosimage: improbable/thanos:v0.6.0command: ["/bin/sh", "-c"]args:- PROM_ID=`echo $POD_NAME| rev | cut -d '-' -f1` /bin/thanos sidecar--prometheus.url=http://localhost:9090--reloader.config-file=/etc/prometheus/prometheus.yml.tmpl--reloader.config-envsubst-file=/etc/prometheus-shared/prometheus.ymlenv:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.nameports:- name: http-sidecarcontainerPort: 10902- name: grpccontainerPort: 10901volumeMounts:- name: prometheus-configmountPath: /etc/prometheus- name: prometheus-config-sharedmountPath: /etc/prometheus-shared
因为 Prometheus 默认是没办法访问 Kubernetes 中的集群资源的,因此需要为之分配RBAC:
apiVersion: v1kind: ServiceAccountmetadata:name: prometheus---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: prometheusnamespace: defaultlabels:app: prometheusrules:- apiGroups: [""]resources: ["services", "pods", "nodes", "nodes/proxy", "endpoints"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["configmaps"]verbs: ["create"]- apiGroups: [""]resources: ["configmaps"]resourceNames: ["prometheus-config"]verbs: ["get", "update", "delete"]- nonResourceURLs: ["/metrics"]verbs: ["get"]---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata:name: prometheusnamespace: defaultlabels:app: prometheussubjects:- kind: ServiceAccountname: prometheusnamespace: defaultroleRef:kind: ClusterRolename: prometheusapiGroup: ""
接着 Thanos Querier 的部署比较简单,需要在启动时指定 store 的参数为dnssrv+thanos-store-gateway.default.svc来发现Sidecar:
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: thanos-queryname: thanos-queryspec:replicas: 2selector:matchLabels:app: thanos-queryminReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: thanos-queryspec:containers:- args:- query- --log.level=debug- --query.timeout=2m- --query.max-concurrent=20- --query.replica-label=replica- --query.auto-downsampling- --store=dnssrv+thanos-store-gateway.default.svc- --store.sd-dns-interval=30simage: improbable/thanos:v0.6.0name: thanos-queryports:- containerPort: 10902name: http- containerPort: 10901name: grpclivenessProbe:httpGet:path: /-/healthyport: http---apiVersion: v1kind: Servicemetadata:labels:app: thanos-queryname: thanos-queryspec:type: LoadBalancerports:- name: httpport: 10901targetPort: httpselector:app: thanos-query---apiVersion: v1kind: Servicemetadata:labels:thanos-store-api: "true"name: thanos-store-gatewayspec:type: ClusterIPclusterIP: Noneports:- name: grpcport: 10901targetPort: grpcselector:thanos-store-api: "true"部署Thanos Ruler:apiVersion: apps/v1kind: Deploymentmetadata:labels:app: thanos-rulename: thanos-rulespec:replicas: 1selector:matchLabels:app: thanos-ruletemplate:metadata:labels:labels:app: thanos-rulespec:containers:- name: thanos-ruleimage: improbable/thanos:v0.6.0args:- rule- --web.route-prefix=/rule- --web.external-prefix=/rule- --log.level=debug- --eval-interval=15s- --rule-file=/etc/rules/thanos-rule.yml- --query=dnssrv+thanos-query.default.svc- --alertmanagers.url=dns+http://alertmanager.defaultports:- containerPort: 10902name: httpvolumeMounts:- name: thanos-rule-configmountPath: /etc/rulesvolumes:- name: thanos-rule-configconfigMap:name: thanos-rule-config
部署 Pushgateway:
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: pushgatewayname: pushgatewayspec:replicas: 15selector:matchLabels:app: pushgatewaytemplate:metadata:labels:app: pushgatewayspec:containers:- image: prom/pushgateway:v1.0.0name: pushgatewayports:- containerPort: 9091name: httpresources:limits:memory: 1Girequests:memory: 512Mi---apiVersion: v1kind: Servicemetadata:labels:app: pushgatewayname: pushgatewayspec:type: LoadBalancerports:- name: httpport: 9091targetPort: httpselector:app: pushgateway
部署 Alertmanager:
apiVersion: apps/v1kind: Deploymentmetadata:name: alertmanagerspec:replicas: 3selector:matchLabels:app: alertmanagertemplate:metadata:name: alertmanagerlabels:app: alertmanagerspec:containers:- name: alertmanagerimage: prom/alertmanager:latestargs:- --web.route-prefix=/alertmanager- --config.file=/etc/alertmanager/config.yml- --storage.path=/alertmanager- --cluster.listen-address=0.0.0.0:8001- --cluster.peer=alertmanager-peers.default:8001ports:- name: alertmanagercontainerPort: 9093volumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanagermountPath: /alertmanagervolumes:- name: alertmanager-configconfigMap:name: alertmanager-config- name: alertmanageremptyDir: {}---apiVersion: v1kind: Servicemetadata:labels:name: alertmanager-peersname: alertmanager-peersspec:type: ClusterIPclusterIP: Noneselector:app: alertmanagerports:- name: alertmanagerprotocol: TCPport: 9093targetPort: 9093
最后部署一下 ingress,大功告成:
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: pushgateway-ingressannotations:kubernetes.io/ingress.class: "nginx"nginx.ingress.kubernetes.io/upstream-hash-by: "$request_uri"nginx.ingress.kubernetes.io/ssl-redirect: "false"spec:rules:- host: $(DOMAIN)http:paths:- backend:serviceName: pushgatewayservicePort: 9091path: /metrics---apiVersion: extensions/v1beta1kind: Ingressmetadata:name: prometheus-ingressannotations:kubernetes.io/ingress.class: "nginx"spec:rules:- host: $(DOMAIN)http:paths:- backend:serviceName: thanos-queryservicePort: 10901path: /- backend:serviceName: alertmanagerservicePort: 9093path: /alertmanager- backend:serviceName: thanos-ruleservicePort: 10092path: /rule- backend:serviceName: grafanaservicePort: 3000path: /grafana
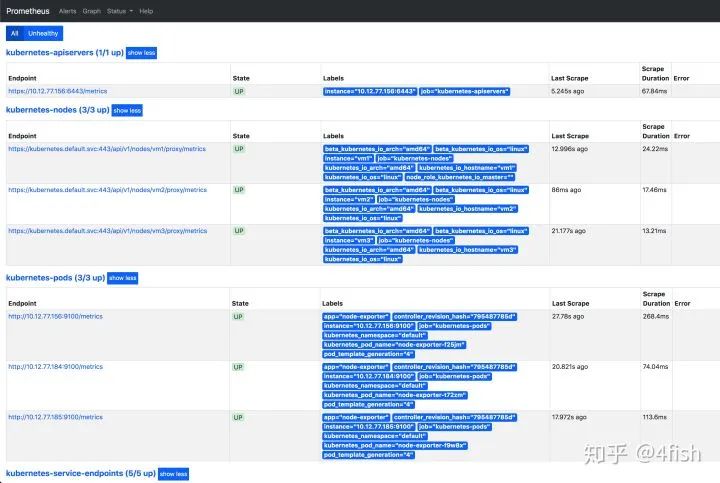
访问 Prometheus 地址,监控节点状态正常: