
GPT-3难以复现,为什么说PyTorch走上了一条“大弯路”?

2020 年,最轰动的 AI 新闻莫过于 OpenAI 发布的 GPT-3 了。它的 1750 亿参数量及其在众多 NLP 任务上超过人类的出众表现让人们开始坚信:大模型才是未来。但与之带来的问题是,训练超大模型所需的算力、存储已不再是单机就能搞定。
据 NVIDIA 估算,如果要训练 GPT-3 ,即使单个机器的显存 / 内存能装得下,用 8 张 V100 的显卡,训练时长预计要 36 年;即使用 512 张 V100 ,训练也需要将近 7 个月;如果拥有 1024 张 80GB A100, 那么完整训练 GPT-3 的时长可以缩减到 1 个月。
除去硬件资源这个经济问题,在技术层面,意味着训练大模型一定是一个分布式问题。因为算力需求还是一个相对容易解决的问题,毕竟拥有大集群的组织并不只 OpenAI 一家,而如何解决上千块 GPU 的分布式训练问题才是关键。
根据目前业界已有的分布式训练方案,即便你是一位非常优秀的数据科学家,知晓并能解决 Transformer 相关的所有算法问题,但如果你不知道如何解决分布式训练时上百台服务器之间的通信、拓扑、模型并行、流水并行等问题,你甚至都无法启动这次训练。一定程度上,这解释了 GPT-3 发布时隔一年,却只有 NVIDIA 、微软等大企业可以复现 GPT-3 。
目前,开源的 GPT 模型库主要是 NVIDIA 开发的 Megatron-LM 和经过微软深度定制开发的 DeepSpeed,其中,DeepSpeed 的模型并行等内核取自 Megatron,它们都是专门为支持 PyTorch 分布式训练 GPT 而设计。
不过在实际训练中,PyTorch 、 Megatron、DeepSpeed 都走了一条非常长的弯路。不仅是弯路,你会发现 Megatron 的代码只能被 NVIDIA 的分布式训练专家所复用,它对于 PyTorch 的算法工程师而言门槛极高,以至于任何想要用 PyTorch 复现一个分布式大模型的算法工程师,都得先等 NVIDIA 开发完才能再使用 Megatron 提供的模型。
作为新一代深度学习开源框架,致力于“大模型分布式”高效开发的 OneFlow 框架用一套通用设计非常简单清晰地解决了 GPT 模型的分布式训练难题,同时还在已有的测试规模上性能超过 NVIDIA 的 Megatron,这为大规模分布式训练框架提出了更优的设计理念和路径。
一、PyTorch 分布式训练 GPT 的痛点是什么?
此前,NVIDIA 放出了一篇重量级的论文:Efficient Large-Scale Language Model Training on GPU Clusters ,用 3072 张 80 GB A100 训练 GPT,最大规模的模型参数量达到了 1T,这是 GPT-3 原版规模的 5 倍。
 NVIDIA 训练 GPT-3 最大到 1T 参数规模
NVIDIA 训练 GPT-3 最大到 1T 参数规模
论文里,NVIDIA 介绍了分布式训练超大规模模型的三种必须的并行技术:
数据并行(Data Parallelism)
模型并行(Tensor Model Parallelism)
流水并行(Pipeline Model Parallelism)
其中,数据并行是最常见的并行方式。而模型并行是对某一层(如 Linear/Dense Layer 里的 Variable )的模型 Tensor 切分,从而将大的模型 Tensor 分成多个相对较小的 Tensor 进行并行计算;流水并行,是将整个网络分段(stage),不同段在不同的设备上,前后阶段流水分批工作,通过一种“接力”的方式并行。
对于 1T 规模的模型,NVIDIA 一共使用了 384 台 DGX-A100 机器(每台装有 8 张 80GB A100 GPU),机器内部各 GPU 间使用超高速 NVLink 和 NVSwitch 互联,每台机器装有 8 个 200Gbps 的 InfiniBand (IB) 网卡,可以说是硬件集群顶配中的顶配。
那么,这些机器是如何协同工作的?GPT 网络是由很多层 Transformer Layer 组成,每一层内部是一个由多层 MLP 和 attention 机制组成的子图,对于参数规模 1T 的 GPT 而言就有 128 层的 Transformer Layer,这个超大超深的网络被分割成了 64 个 stage (阶段),每个 stage 跑在 6 台 DGX-A100 上,其中 6 台机器之间进行数据并行,每台机器内部的 8 张卡之间做模型并行,整个集群的 3072 张 A100 按照机器拓扑被划分成了 [6 x 8 x 64] 的矩阵,同时使用数据并行 & 模型并行 & 流水并行进行训练。
 3072 张 A100 集群拓扑
3072 张 A100 集群拓扑
GPipe、梯度累加、重计算(Checkpointing)和 1F1B(One Forward pass followed by One Backward pass)是分布式训练 GPT 的流水并行的核心技术。无论是 NVIDIA 的 Megatron(PyTorch),还是 OneFlow、PaddlePaddle、MindSpore ,都是通过不同的设计实现了上述相同的功能。
基于 PyTorch 开发的 Megatron,本质上是一个专用于 GPT 的模型库,所有的代码都是 Python 脚本,NVIDIA 为 GPT 专门定制了分布式训练所需的算子、流水并行调度器、模型并行所需的通信原语等功能,在 GPU 上的性能表现上,Megatron 已经非常优异。可以说,NVIDIA 在使用 PyTorch 做分布式训练上已经做到极致了。
但是,用 PyTorch 做分布式训练,真的好用吗?
具体来说,从 PyTorch 在分布式并行上的设计以及开放给用户的接口来看,PyTorch 分布式的有以下困境:
PyTorch 只有物理视角(Physical View),没有逻辑视角(Logical View)。
PyTorch 的用户想要做分布式并行,任何时候都需要自己推导深度学习模型中哪处需要跟其他的物理设备进行通信和数据同步操作,既要推导通信所在的位置,又要推导通信的操作类型,还要推导跟其他哪些设备通信。这个在简单的数据并行下可以使用 DDP 或 Horovod 来实现,但是在复杂的模型并行、混合并行下,做并行的门槛非常高。
 NVIDIA 模型并行通信推导
NVIDIA 模型并行通信推导
PyTorch 没有将模型网络的算法逻辑和分布式并行训练的通信逻辑解耦出来,导致用户需要在算子的 kernel 实现中,搭网络的脚本里到处插入通信原语。这些手写通信原语的操作不仅繁琐、易错、而且没法复用,是根据特定模型、特定脚本位置、特定算子特判得到的。
PyTorch 在非对称的并行方式里(如流水并行,PyTorch 需要人工排线和精细控制流水),各个设备的调度逻辑需要用户自己手写。用户需要自己精细的控制每个设备上的启动以及执行逻辑,且执行逻辑把前后向执行和 send/recv 通信操作糅合在一起,即使在最规整的 Transformer Layer 的流水并行下也很复杂,想要扩展到其他模型上的工作量也很大。
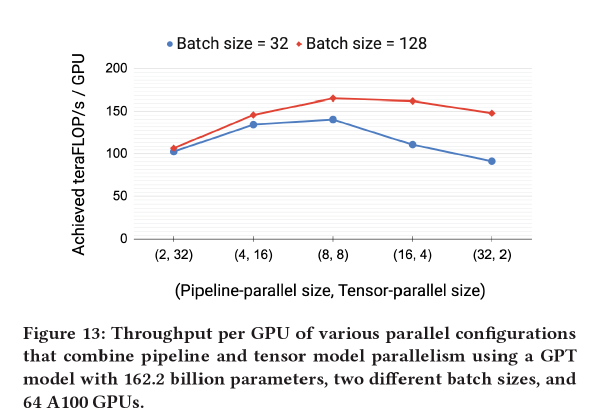 模型并行度和流水并行度对性能的影响
模型并行度和流水并行度对性能的影响
PyTorch 没有机制保证分布式并行训练中的正确性和数学一致性。即使用户写错了通信操作,插错了位置, 跟错误的设备进行通信,PyTorch 也检查不出来。
上述困境使得普通算法工程师使用 PyTorch 开发复杂分布式训练的脚本极为困难。其实,NVIDIA、 微软、 PyTorch 都被绕进了一个大坑:在没有一致性视角( Consistent View )的情况下做复杂的分布式并行非常困难,往往只能做一些具体网络、具体场景、具体算子的特判和分析,通过简单的通信原语来实现分布式。
那么,OneFlow 如何解决这些困境?
二、OneFlow 用一致性视角轻松填平分布式训练难的鸿沟
对于分布式集群环境(多机多卡训练场景),OneFlow 会把整个分布式集群抽象成一个超级设备,用户只需要在这个超级设备上搭建深度学习模型即可。这个虚拟出来的超级设备称之为逻辑视角,而实际上的分布式集群的多机多卡就是物理视角,OneFlow 维护逻辑视角和物理视角之间的数学上的正确性就称之为一致性视角。
基于分布式训练难的鸿沟,OneFlow 通过一致性视角下的 Placement(流水并行) + SBP (数据和模型的混合并行),非常简单的实现了通用的复杂并行支持。当然,这离不开 OneFlow 的两大独特设计:
运行时 Actor 机制
编译期一致性视角,通过 Placement + SBP + Boxing 解决分布式易用性的问题。
 一致性视角(Consistent View)抽象
一致性视角(Consistent View)抽象
理想情况下,抽象出来的超级设备(逻辑视角)的算力是所有物理视角下的设备算力之和(如果算力完全用满,就是线性加速比);逻辑视角下的显存资源也是所有物理设备的显存资源之和。
总体而言,基于一致性视角的 OneFlow 分布式有以下易用性体现:
OneFlow 的一致性视角将分布式训练下的多机通信和算法逻辑解耦,使得用户可以不用关心分布式训练的细节,降低了分布式训练的使用门槛。
相比其他框架和高级定制用户在所有分布式并行上的努力,OneFlow 通过 Placement + SBP 机制解决了分布式训练中任意并行场景的需求。用户只需要配置 op 的 Placement 就可以完成流水并行,只需要配置 Tensor 的 SBP 就可以实现数据并行、模型并行和混合并行。并且,任何并行方式都是 Placement + SBP 的一种特例, OneFlow 从系统层面不需要做任何的特判,SBP 才是各种分布式并行的本质。
 上图展示了一个 Placement 例子,用于 GPU0 和 GPU1 之间的流水并行。图中负责在 CPU 和 GPU、GPU 与 GPU 之间进行数据搬运的 Op(CopyH2D、CopyD2D)是 OneFlow 系统自动添加的。
上图展示了一个 Placement 例子,用于 GPU0 和 GPU1 之间的流水并行。图中负责在 CPU 和 GPU、GPU 与 GPU 之间进行数据搬运的 Op(CopyH2D、CopyD2D)是 OneFlow 系统自动添加的。
OneFlow 的通信逻辑可以复用,不需要为任何特定网络和特定算子实现相应的通信逻辑。通信逻辑由 OneFlow 的 Boxing 机制完成,与具体的算子和模型无关。
OneFlow 的 SBP 还保证了数学上的一致性。相同的逻辑上的模型脚本,使用任意的并行方式(数据并行、模型并行、流水并行)、使用任意的集群拓扑,OneFlow 都从数学上保证了模型分布式训练的正确性。
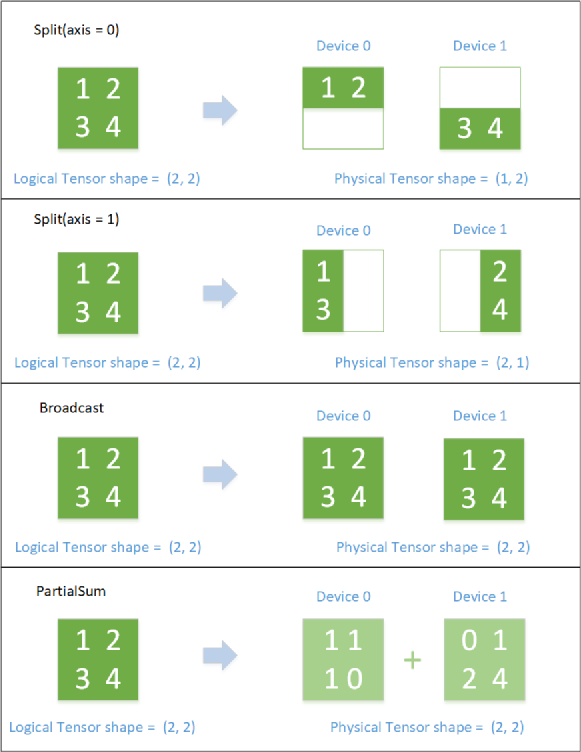 SBP 逻辑与物理 Tensor 的对应关系(SBP 描述了 逻辑上的 Tensor 和 物理上的 Tensor 的映射关系。SBP 全称叫做 SbpParallel,是三种基础映射的首字母组合:Split、Broadcast、Partial,其中 Partial 是一个 reduce 操作,包括 PartialSum、PartialMin、PartialMax 等)
SBP 逻辑与物理 Tensor 的对应关系(SBP 描述了 逻辑上的 Tensor 和 物理上的 Tensor 的映射关系。SBP 全称叫做 SbpParallel,是三种基础映射的首字母组合:Split、Broadcast、Partial,其中 Partial 是一个 reduce 操作,包括 PartialSum、PartialMin、PartialMax 等)
采用这样一套简洁设计可解决分布式并行的各种难题,OneFlow 使得每一位算法工程师都有能力训练 GPT 模型。它让你不需要成为一位分布式训练的专家也有能力做复杂的分布式训练, 只要有硬件资源,任何一位算法工程师都可以训练 GPT, 都可以开发一个新的大规模分布式训练的模型。
三、为什么分布式深度学习框架要像 OneFlow 这样设计?
上述内容从用户角度分析和比较了 OneFlow 和 PyTorch(Megatron)的分布式易用性,那么从框架设计和开发者的角度,它又是如何具体实现分布式并行的?为什么说 OneFlow 会是分布式训练更为本质的设计?
OneFlow 如何实现流水并行?
OneFlow 的运行时 Actor 机制有以下几个特点:
天然支持流水线, Actor 通过内部的状态机和产出的 Regst 个数以及上下游的 Regst 消息机制解决了流控问题(Control Flow)。
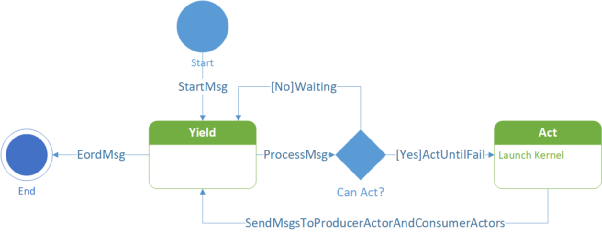 Actor 状态机
Actor 状态机
Actor 组成的计算图运行时调度是去中心化的,每个 Actor 当前是否可以执行都仅与自己的状态、空闲 Regst 数量以及收到的消息有关。
所以使用 Actor 做流水并行,本身就不需要自己定制复杂的调度逻辑。以数据加载的 Pipeline 为例, 当一个由 Actor 组成的数据预处理流程如下图所示:
 数据预处理流程
数据预处理流程
当这 4 个 Actor 之间的 RegstNum 均为 2 时,如果训练时间比较长(训练是整个网络的瓶颈),就会得到如下这种流水线的时间线:
 数据预处理 pipeline 时间线
数据预处理 pipeline 时间线
在执行几个 Batch 之后, 4 个阶段的执行节奏完全被最长的那个阶段所控制,这就是 OneFlow 使用背压机制(Back Pressure)解决流控问题。
所以流水并行问题,在 OneFlow 中就是 Regst 数量的问题。在实际实现中, OneFlow 采用了一个更通用的算法实现了 Megatron 的流水并行:插入 Buffer Op。在逻辑计算图上, 会给后向消费前向的边插入一个 Buffer Op, Buffer 的 Regst 数量 和 Stage 相关。由于后向对前向的消费经过 Checkpointing 优化后,每个 Placement Group 下只会有非常少的几条消费边。
 OneFlow 通过插入 Buffer Op 实现流水并行
OneFlow 通过插入 Buffer Op 实现流水并行
与 Megatron 复杂的手写调度器和手写通信原语相比, OneFlow 系统层面只需要插入 Buffer 就可以实现流水并行。
OneFlow 如何实现数据 + 模型的混合并行?
以 Linear Layer 的数据 + 模型并行为例,来解释所有的数据并行和模型并行的组合,本质上都是被 SBP 所描述的 Signature。任何并行方式的设备间通信操作,该在整个网络的哪里插入、该插入什么通信操作、每个设备该和谁通信,完全都是 SBP 自动推导得到的,而且还保证数学上的一致性。
可以说,OneFlow 的设计使得算法工程师告别了分布式并行中的通信原语。不仅如此,OneFlow 的框架开发者绝大多数时候也不需要关心分布式里的通信原语,SBP 这层抽象使得算子 / 网络跟分布式通信解耦。
以 1-D SBP 为例,1-D SBP 下的数据并行,对于一个 Linear Layer 而言,主要是其中的 MatMul(矩阵乘法)计算。假设矩阵乘法计算在逻辑视角上是一个 (m, k) x (k, n) = (m, n) 的计算,m 表示一共有多少个样例, k 和 n 分别是 Linear Layer 中的隐藏层神经元数量以及输出神经元数量。
数据并行的逻辑计算图 -> 物理计算图 的映射关系如下图所示:
 数据并行下逻辑计算图转物理计算图
数据并行下逻辑计算图转物理计算图
数据并行下,每个设备上都有全部的模型(Tensor b, Shape = (k, n)),假设共有两张卡,则 GPU0 上有前一半的数据 (Tensor a,Shape = (m/2, k)),GPU1 上有后一半的数据, 则 Tensor a 的 SBP Parallel = Split(0)。同时可以看到矩阵乘的输出 Tensor out,也是按照第 0 维切分的。
模型并行对于 Linear Layer 而言,有两种,分别是切模型 Tensor 的第 0 维(行切分,对应 Megatron 里的 RowParallelLinear)和 第 1 维(列切分,对应 Megatron 里的 ColumnParallelLinear)。
第一种行切分(RowParallelLinear)模型并行的 逻辑计算图 -> 物理计算图 的映射关系如下图所示:
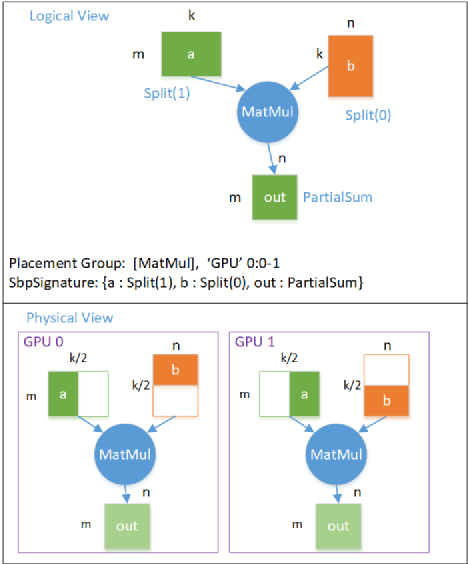 模型并行(行切分) 逻辑图转物理图
模型并行(行切分) 逻辑图转物理图
模型并行下,每个设备都只有一部分的模型,在这个例子中, GPU 0 上有前一半的模型, GPU 1 上有后一半的模型,每个设备上的模型大小 Tensor b 的 Shape = (k/2, n)。在这种情况下, 每个设备输出的 Tensor out 都是完整的数据大小, Shape = (m, n), 但每个位置上的元素的值,都是逻辑上的输出 out 对应位置的值的一部分,即 out 的 SBP Parallel = PartialSum 。
第二种列切分(ColumnParallelLinear)模型并行的 逻辑计算图 -> 物理计算图 的映射关系如下图所示:
 模型并行(列切分)逻辑图转物理图
模型并行(列切分)逻辑图转物理图
这个例子中,模型 Tensor b 是按照 Split(1) 切分的,输出 Tensor out 也是按照 Split(1) 切分的,每个设备都需要全部的数据。
在 GPT 网络中,实际上的模型并行是组合使用 RowParallelLinear 和 ColumnParallelLinear 实现的(ColumnParallelLinear 后面接了 RowParallelLinear)。
因为 Column 的输出 Tensor SBP 是 Split(1), Row 的输入数据 Tensor SBP 也是 Split(1), 所以当 Column 后接 Row 时,两者之间是不需要插入任何通信的。但由于 Row 的输出是 PartialSum, 当后面消费该 Tensor (在网络中是 Add 操作)的 Op 需要全部的数据时(Broadcast), 此处就需要插入 AllReduce 实现通信了。
这在 OneFlow 中称之为 Boxing。当两个逻辑上的 Op 对于同一个逻辑上的 Tensor 看待的 SBP Parallel 不一致时, OneFlow 系统会自动插入通信节点以完成数据的切分 / 传输 / 拼接等操作,使得下游 Op 总能拿到按照自己期望 SBP 切分的 Tensor。
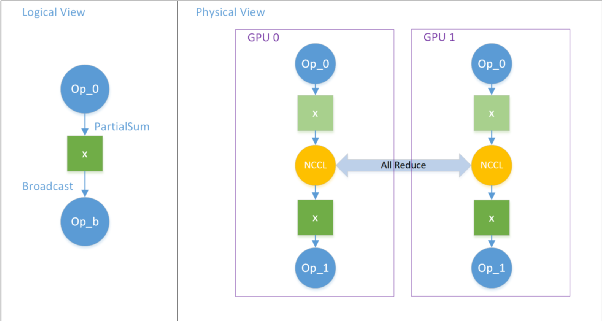 Boxing:通过 AllReduce 实现 PartialSum 转 Broadcast
Boxing:通过 AllReduce 实现 PartialSum 转 Broadcast
 Boxing:通过 AllGather 实现 Split(1) 转 Broadcast
Boxing:通过 AllGather 实现 Split(1) 转 Broadcast
在 OneFlow 中, 所有的分布式通信操作都是基于 SBP 的推导结果,按照需要插入。OneFlow 通过 Boxing 机制,就实现了任意的数据并行和模型并行。
2-D SBP 其实就是将两组 1-D SBP 按照设备拓扑的维度拼起来就可以得到。其实 GPT 中用到的 2-D SBP 只是最简单情形的特例, 分布式下的并行经过 2-D SBP 可以拓展出非常多复杂、灵活多边的组合出来。而针对复杂的组合, 再想用 Megatron 的设计就非常难做,但对于 OneFlow 而言,二者的难度是一样的,因为本质上是用 Boxing 完成一组 2-D SBP 的变换。
四、GPT 分布式训练性能对比:OneFlow vs Megatron
与 Megatron 相比,OneFlow 除了在用户接口(分布式易用性) 和框架设计上更简洁、更易用,在 4 机 32 卡 16GB V100 的测试规模上性能也超过 Megatron。值得一提的是,经过 NVIDIA 的深度优化, Megatron 在 GPU 上的分布式训练性能已经接近极致,DeepSpeed 也无法与之相比。
以下的所有实验数据均在相同的硬件环境、相同的第三方依赖(CUDA、 cuDNN 等)、使用相同的参数和网络结构下, 对比了 OneFlow 和 Megatron 在 GPT 模型下的性能表现。所有的性能结果均公开且可复现。(GPT 模型脚本在 Oneflow-Inc/OneFlow-Benchmark 仓库, 公开的评测报告、复现方式稍后在 Oneflow-Inc/DLPerf 仓库中可查看。)
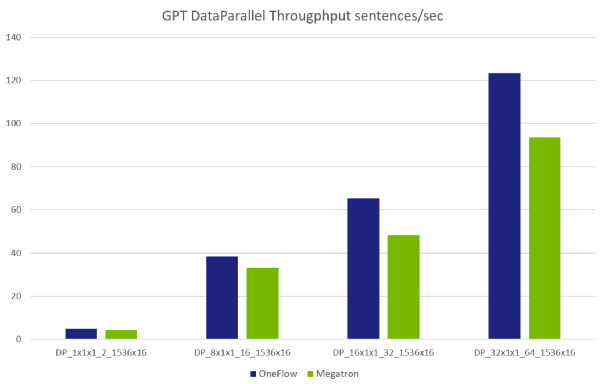 数据并行性能对比
数据并行性能对比
注:每组参数的缩略版含义:· DP 数据并行;MP 模型并行;2D 数据 & 模型 的 混合并行;PP 流水并行· dxmxp_B_hxl 其中:· d = 数据并行度(data-parallel-size)· m = 模型并行度(tensor-model-parallel-size)· p = 流水并行度(pipeline-model-parallel-size)· B = 总的 BatchSize(global-batch-size)· h = 隐藏层大小(hidden-size)影响每层 Transformer Layer 的模型大小· l = Transformer Layer 层数(num-layers)
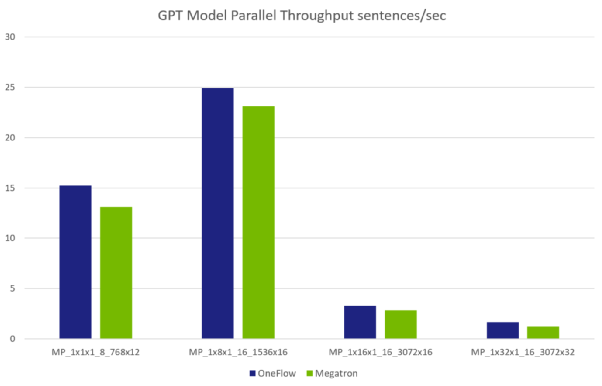 模型并行数据对比
模型并行数据对比
注:由于单卡 GPU 显存限制,各组参数里的模型大小是不同的,所以整体不像数据并行那样呈线性增加的关系。如第 4 组参数(MP_1x32x1_16_3072x32)的模型大小是第 2 组参数(MP_1x8x1_16_1536x16)的 8 倍以上。NVIDIA 论文中有模型规模跟各个参数的计算公式:
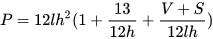
其中 l 表示 num-layers ,h 表示 hidden-size, V 表示词表大小(vocabulary size = 51200), S 表示句子长度(a sequence length = 2048), P 表示参数规模。
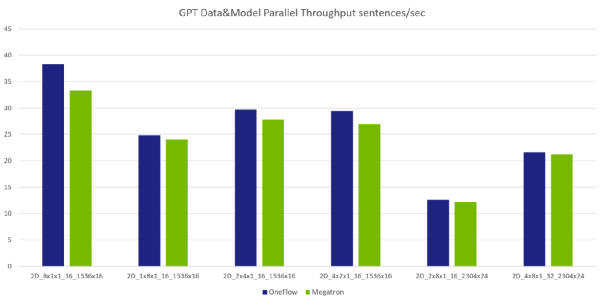 数据 + 模型并行性能对比(注:其中前 4 组的模型规模一致;后 2 组的模型规模一致。)
数据 + 模型并行性能对比(注:其中前 4 组的模型规模一致;后 2 组的模型规模一致。)
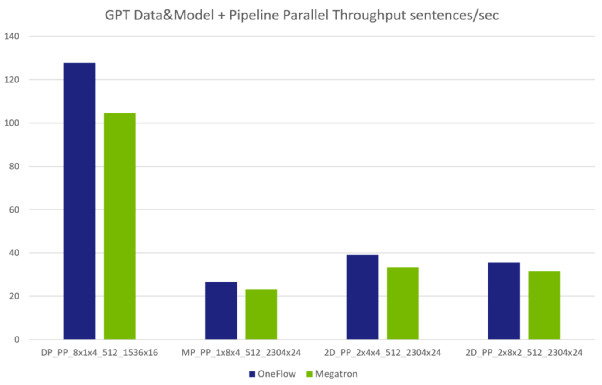
数据 + 模型 + 流水并行性能对比(注:第 1 组参数的模型比后 3 组的都要小,因为机器内的数据并行限制了参数规模。)
五、小结
在分布式训练领域拥有独特的设计和视角,OneFlow 解决了分布式训练中的各种并行难题,因此在大规模预训练模型场景下用 OneFlow 做分布式训练更易用也更高效。
同时,OneFlow 团队正在全力提升框架的单卡使用体验。据悉,OneFlow 即将在 5 月发布的大版本 OneFlow v0.4.0 起,将提供兼容 PyTorch 的全新接口以及动态图等特性。而在 v0.5.0 版本,OneFlow 预计全面兼容 PyTorch, 届时用户可将 PyTorch 的模型训练脚本一键迁移为 OneFlow 的训练脚本。此外, OneFlow 还会提供 Consistent 视角的分布式 Eager,用户可以既享受动态图的易用性,又可以非常方便的进行各种分布式并行训练。
OneFlow GitHub 链接:https://github.com/Oneflow-Inc/oneflow
内容详版请查看:https://mp.weixin.qq.com/s/YQshbDYgfYCO9POH7Ls3cw


你也「在看」吗?👇