
0代码训练GPT-5?MIT微软证实GPT-4涌现自我纠错能力,智能体循环...

新智元报道
编辑:编辑部【新智元导读】谁能想到,训练GPT-5竟不用手写代码。MIT微软最新研究发现,GPT-4在代码修复中的有效性。以后,OpenAI工程师能做的只有——Critique is all you need。
我们都知道,大模型具有自省能力,可以对写出的代码进行自我纠错。
这种自我修复背后的机制,究竟是怎样运作的?
对代码为什么是错误的,模型在多大程度上能提供准确反馈?
近日,MIT和微软的学者发现,在GPT-4和GPT-3.5之中,只有GPT-4表现出了有效的自修复。并且,GPT-4甚至还能对GPT-3.5生成的程序提供反馈。

论文地址:https://arxiv.org/pdf/2306.09896.pdf
英伟达科学家Jim Fan强烈推荐了这项研究。
在他看来,即使是最专业的人类程序员也无法一次性正确编写程序。他们需要查看执行结果,推理出问题所在,给出修复措施,反复尝试。这是一个智能体循环:根据环境反馈迭代改进代码。
很有可能,OpenAI正在通过雇佣大量软件工程师来训练下一代GPT。而他们不需要输出代码——Critique is all you need。

- GPT-4能够进行自我修复的核心原因是其强大的反馈能力。它能够有效地自我反思代码的问题所在,其他模型无法与之竞争。
- 反馈模型和代码生成模型不必相同。事实上,反馈模型是瓶颈。
- 基于GPT-4的反馈,GPT-3.5能够编写更好的代码。
- 基于专业人员的反馈,GPT-4本身能够编写更好的代码。
揭秘用于代码生成GPT修复
我们都知道,大语言模型在生成代码方面,表现出了非凡的能力。
然而,在具有挑战性的编程任务(比如竞赛和软件工程师的面试)中,它们却完成得并不好。
好在,很多模型会通过一种自修复工作流来「自省」,来自我纠正代码中的错误。
研究者很希望知道,这些模型在多大程度上能提供正确的反馈,并且说明自己生成的代码为什么是错误的。
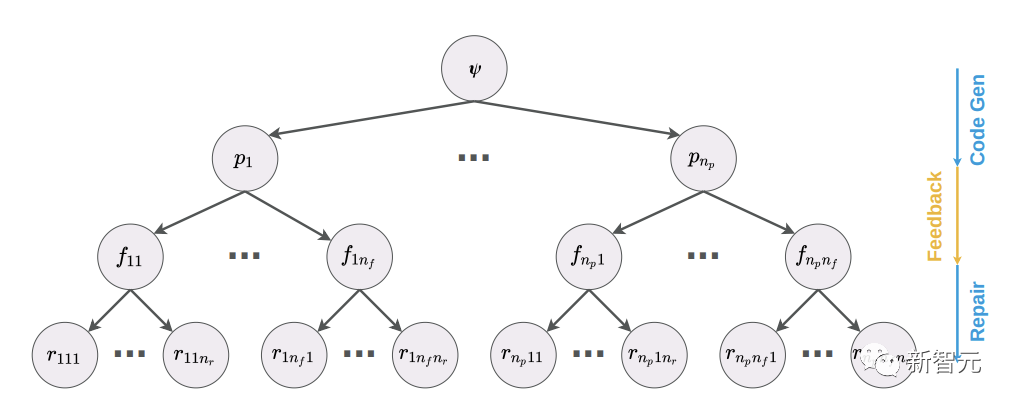
如图显示的是,基于自我修复方法的经典工作流程。
首先,给定一个规范,从代码生成模型中采样一个程序,然后在规范中提供的一组单元测试上执行该程序。
如果程序在任何单元测试中失败,那么错误的消息和程序会被提供给一个反馈生成模型,该模型再输出代码失败原因的简短解释。
最后,反馈被传递给一个修复模型,该模型生成程序的一个固定版本。
表面上看,这个工作流似乎非常完美。 它让系统在解码过程中克服由于不良样本引起的错误,在修复阶段容易地合并来自符号系统(编译器、静态分析工具和执行引擎等)的反馈。
并且模仿人类软件工程师编写代码的试错方式。

然而,工作流有一个问题:自修复需要对模型进行更多的调用,从而增加了计算成本。
而且,研究者们发现了一个很有意思的现象:大模型自修复的有效性不仅取决于模型生成代码的能力,还取决于它对于代码如何在任务中犯错的识别能力。
目前还没有任何工作对此进行详细调查,因此,作者们研究了GPT-3.5和GPT-4在解决竞赛级代码生成任务时的自修复有效性。
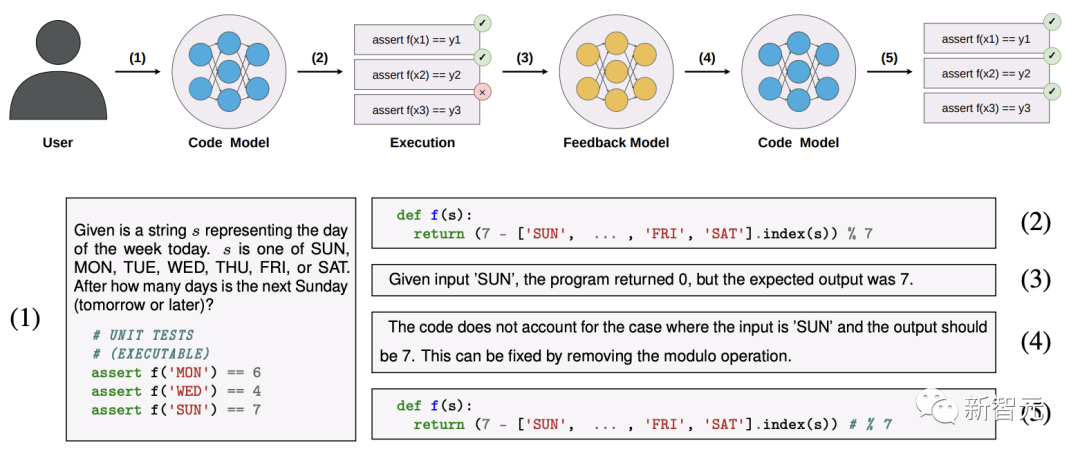
研究人员提出了一个新的评估策略,称为 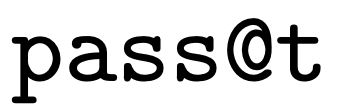 ,在这个策略中,根据从模型中采样的token总数来衡量任务的通过率。
,在这个策略中,根据从模型中采样的token总数来衡量任务的通过率。
因为使用的是pass@t,而不是传统的pass@k(根据实验数量衡量通过率),这样就能与纯粹基于采样的方法进行公平的比较。
从实验中,研究者发现:
1. GPT-4才能实现自我修复带来的性能提升;对于GPT-3.5,在所有预算下,修复后的通过率要低于或等于基准的无修复方法。
2. 即使对于GPT-4模型,性能提升也最多只能算是适度的(在预算为7000个token的情况下,通过率从66%提高到71%,约等于45个独立同分布的GPT-4样本的成本),并且取决于初始程序的多样性足够丰富。
3. 使用GPT-4生成的反馈替换GPT-3.5对错误的解释,可以获得更好的自修复性能,甚至超过基准的无修复GPT-3.5方法(在7000个token下,从50%提高到54%)。
4. 使用人类程序员提供的解释替换GPT-4自己的解释,可以显著改善修复效果,修复并通过测试的程序数量增加了57%。
自我修复四阶段
自修复方法涉及4个阶段:代码生成、代码执行、反馈生成和代码修复。对此,研究人员正式定义了这四个阶段。
阶段一:代码生成
给定规范 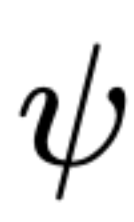 ,一个程序模型
,一个程序模型 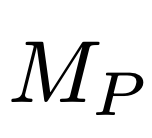 ,首先生成
,首先生成 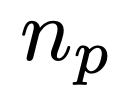 样本
样本 
用一个公式来表示:
阶段二:代码执行
然后在测试平台上执行 代码示例,并假设可以以可执行形式的访问完整测试集。
如果任何样本通过了所有的测试,就会停止,因为此时已经找到了令人满意的程序。
否则,收集执行环境返回的错误信息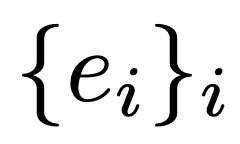 。
。
这些错误消息要么包含编译/运行时错误信息,要么包含程序输出与预期不同的示例输入。
阶段三:反馈生成
在此,研究人员使用反馈模型来生成更详细的错误解释。
在这个阶段,为每个错误的程序生成 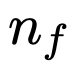 反馈字符串,
反馈字符串, 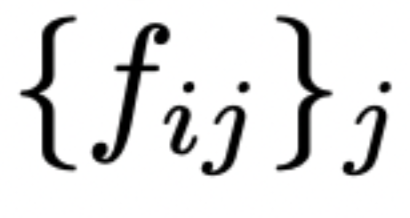 ,如下所示:
,如下所示:
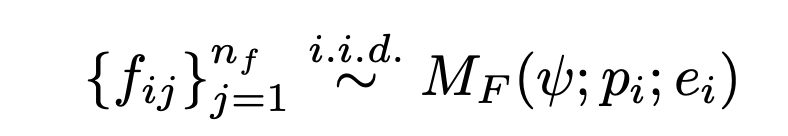
阶段四:代码修复
在最后一步中,对于每个初始程序 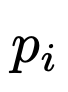 和反馈
和反馈 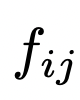 ,
, 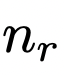 候选修复程序从
候选修复程序从 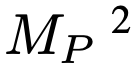 中采样:
中采样:
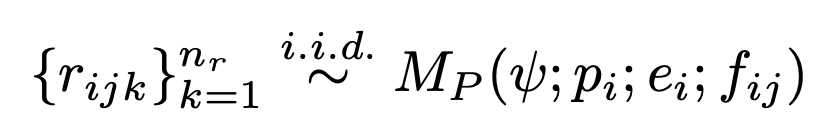
研究人员称这个过程产生的交错文本和程序树修复树T
——植根于规范 ,然后分支到初始程序 ,每个程序分支到反馈 ,然后修复 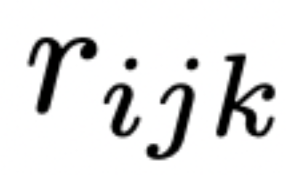 。
。
具体如图所示:
由于自我修复需要几个非一致成本的相关模型调用,在这种设置中, 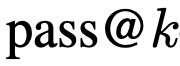 (在
(在 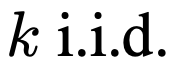 样本中获得正确程序的可能性)不是比较和评估自我修复的各种超参数选择的合适度量。
样本中获得正确程序的可能性)不是比较和评估自我修复的各种超参数选择的合适度量。
相反,研究人员将通过率作为从模型中采样总token数量的函数来衡量,将其称之为 的度量。
实验过程
研究人员又进一步针对3个问题进行了测试:
1. 对于更加有挑战的编程任务中,这些模型的自我修复是否比不进行修复的i.i.d.有更好的采样?
2. 更强的反馈模型会提高模型的修复性能吗?
3. 如果让人类参与功能最强模型的自我修复循环,提供人工反馈,是否可以解锁更好的修复性能?
首先研究团队引入了一个很有挑战的编程任务:Automated Programming Progress Standard (APPS)数据集中的编程任务。
这个数据集中的任务包括从入门级到大学竞赛级的编程任务,可以用来评估人类程序员解决问题和代码能力。
研究人员选取了300个任务,包括60个入门级别的任务和60个竞赛级别的任务。
研究人员选取了GPT-3.5和GPT-4作为模型,使用模板字符串连接和单次提示词来进行自我修复。
下图为提示词的实例之一。
自修复需要强大的模型和多样化的初始样本
研究人员让单个模型分别进行代码的修复生成和反馈生成。
在右边的图中,我们沿轴显示了具有两个超参数的热图,其中每个单元格中的值表示平均通过率,当给定相同的token预算(即t的相同值pass@t)时,自我修复由基线的平均通过率归一化。
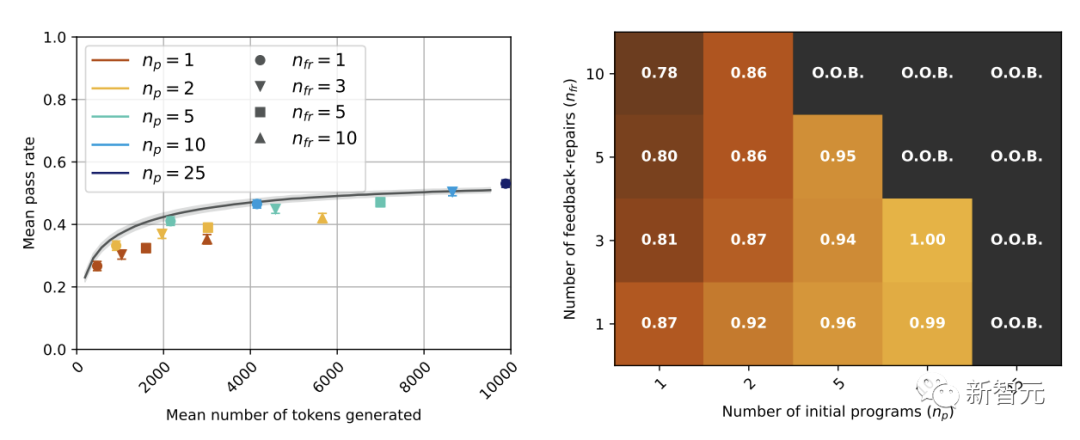
从图中可以看到,对于GPT-3.5模型,pass@t在所有设置下都低于或等于相应的基线(黑),清楚地表明自我修复对GPT-3.5并不是一种有效的策略。
而在GPT-4(下图)中,有几个值的自修复通过率明显优于基线。
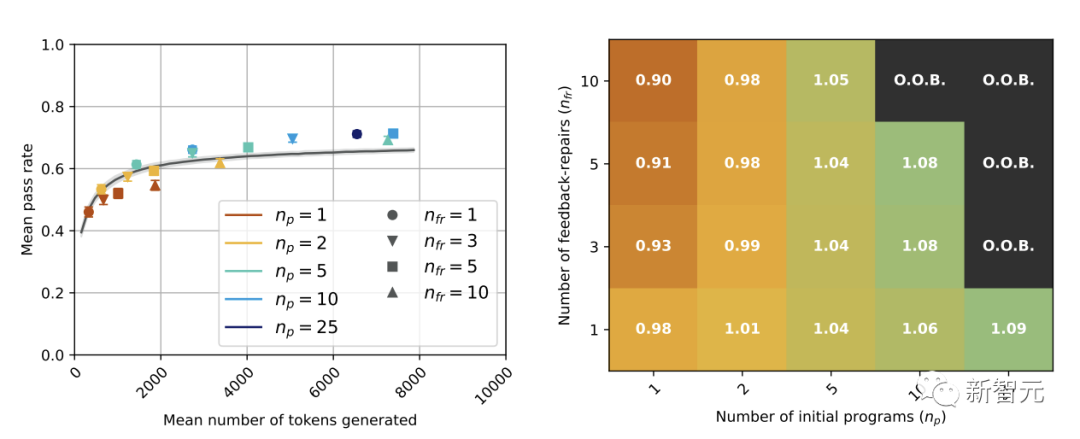
下图是 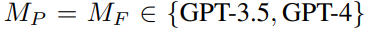 和基线的无修复方法。
和基线的无修复方法。
GPT-4反馈改进了GPT3.5的修复结果
研究人员又进一步进行了新的实验,评估使用单独的、更强的模型来生成反馈的效果,目的是为了测试一个假设:由于模型无法内省和调试自己的代码,阻碍了自我修复(比如说对于GPT-3.5)。
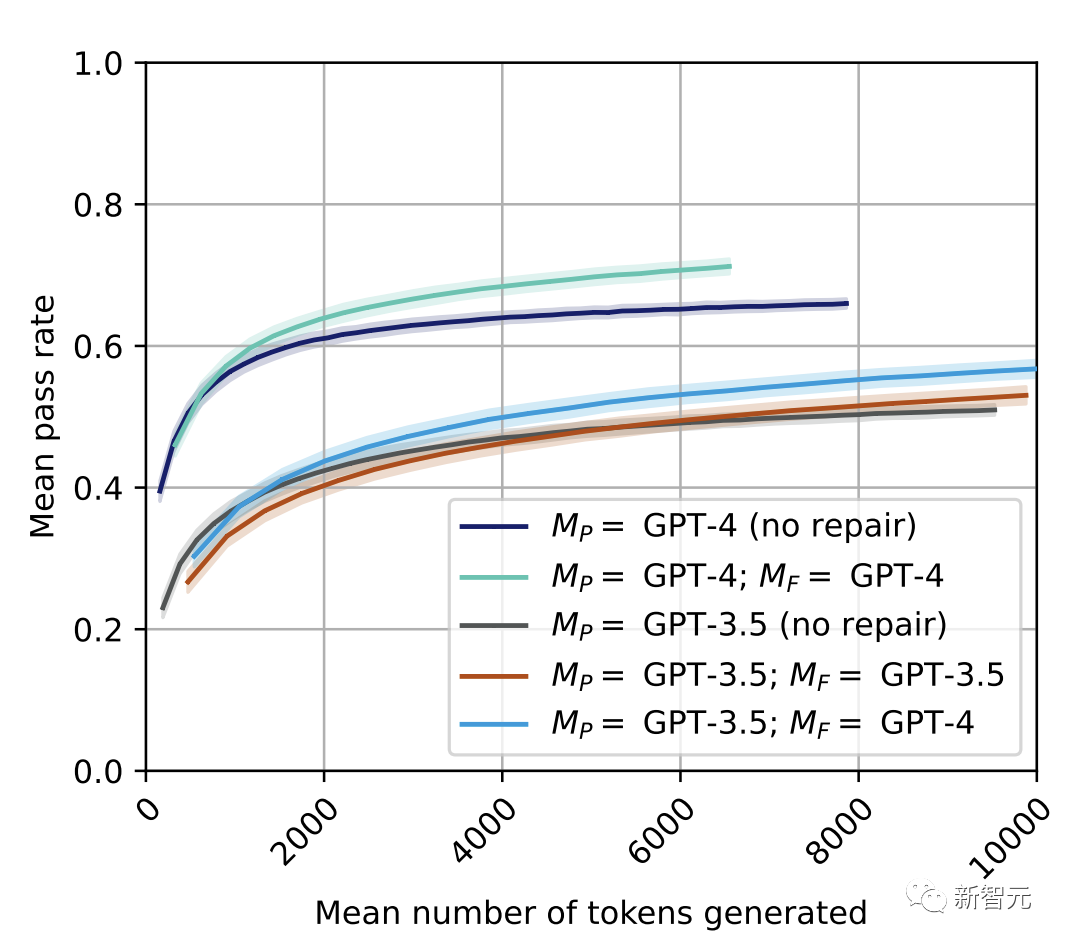
这个实验的结果如上图(亮蓝色)所示。
在绝对性能方面,GPT-3.5,GPT-4确实突破了性能障碍,并且比GPT-3.5的i.i.d.采样略微更高效。
这表明文本反馈阶段本身是至关重要的,改进它可以缓解GPT-3.5自修复的瓶颈。
人工反馈显著提高了GPT-4修复的成功率
在最后一项实验中,想要研究在用更强的模型(GPT-4)进行修复时,加入专家人类程序员的反馈的影响。
研究目的是了解模型识别代码中错误的能力与人类的能力相比如何,以及这如何影响自修复的下游性能。
研究人员研究人员招募了16名参与者,包括15名研究生和1名专业机器学习工程师。
每个参与者都有五种不同的基础程序,基于他们的Python经验编写代码。
每个程序都取自不同的任务,参与者永远不会看到属于同一个任务的两个不同的程序。
然后,参与者被要求用他们自己的话解释这个程序做错了什么。
实验结果如下图所示:
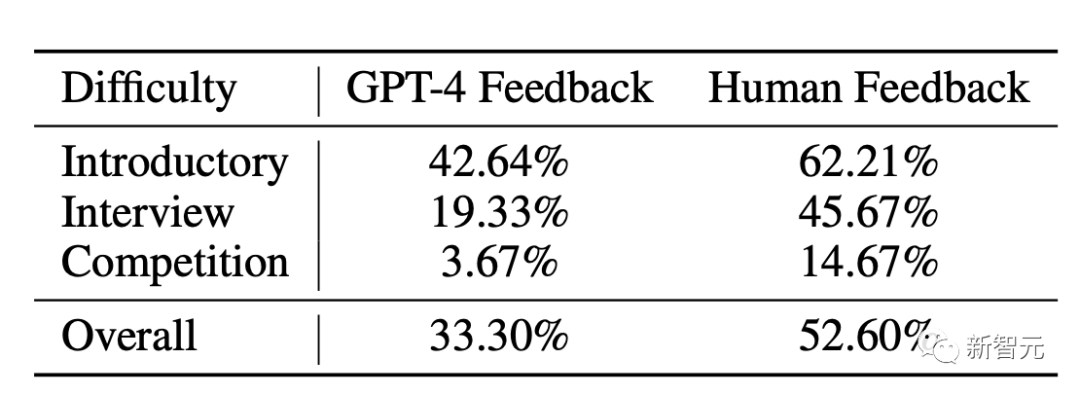
研究人员发现,当我们用人类参与者的调试替换GPT-4自己的调试时,总体成功率提高了1.57×以上。
不出意外的是,随着问题变得更难,相对差异也会增加,这表明当任务(和代码)变得更复杂时,GPT-4产生准确和有用反馈的能力远远落后于人类参与者。

作者介绍
Jianfeng Gao(高剑锋)

高剑锋是微软的杰出科学家和副总裁,也是IEEE Fellow。
在微软研究院,他是Redmond分部深度学习(DL)组的负责人。该组的使命是推进DL的最新技术,并将其应用于自然语言和图像理解以及构建对话代理。他领导了构建大规模基础模型的研究,这些模型为微软的重要人工智能产品提供了支持。
从2022年开始,他负责自我改进人工智能的研究,其中包括对LLM(如ChatGPT/GPT4)进行增强和适应,以用于商业人工智能系统的开发。
在此之前,他于1999年在上海交通大学获得博士学位。
Chenglong Wang

Chenglong Wang是微软研究院的研究员,此前在华盛顿大学获得了博士学位,并曾就读于北京大学。
参考资料: https://twitter.com/DrJimFan/status/1675916565823516673 https://arxiv.org/pdf/2306.09896.pdf

