
What?UFO! | UFO-ViT用X-Norm让你的Transformer模型回归线性复杂度


在本文中提出了一种简单的方法,使自注意力具有线性复杂度而不损失性能。通过替换softmax函数,利用矩阵乘法的关联律消除二次运算。在早期的研究中,这种类型的因子分解通常会导致性能下降。在图像分类和目标检测方面,UFO-ViT模型优于大多数现有的基于Transformer和CNN模型的结果。
1简介
Vision transformers已成为计算机视觉任务的重要模型之一。虽然它们优于早期的卷积网络,但使用传统的自注意力算法时,其复杂度是。
在这里,本文提出了UFO-ViT(Unit Force Operated Vision Trnasformer),通过修改少数行自注意力消除一些非线性来减少自注意力的计算复杂度,UFO-ViT实现线性复杂性而不降低性能。该模型在图像分类和密集预测任务上优于大多数基于Transformer的模型。
本文方法的贡献:
提出了新的约束方案XNorm,它生成单元超球来提取关系特征,防止自注意力过度依赖于初始化方式。此外,它具有O(N)复杂度,能有效地处理高分辨率输入。 证明了UFO-ViT可以用于一般用途。模型在图像分类和密集预测任务上进行了实验。在较低的容量和FLOPS,UFO-ViT使用线性自注意力方案依然优于大多数基于Transformer模型。特别是,模型在轻量状态下表现良好。 提出了一种动态处理输入图像的新模块。这意味着权重的大小与输入分辨率无关。它适用于密集的预测任务,如目标检测或语义分割,这通常需要比训练前更高的分辨率。对于基于MLP的结构,如果模型在不同分辨率上预训练,则需要进行后处理。
2本文方法
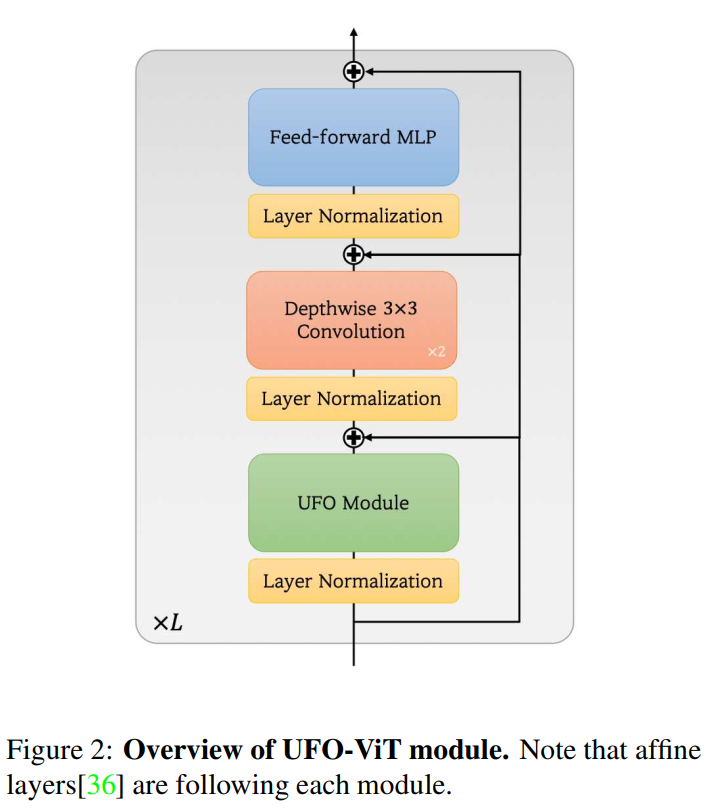
模型的结构如图2所示。它是一个混合的卷积层,UFO模块和一个简单的前馈MLP层。接下来将指出所提出的方法是如何取代softmax函数并确保线性复杂度的。
2.1 理论解释
对于输入,传统的自注意力机制表示为:
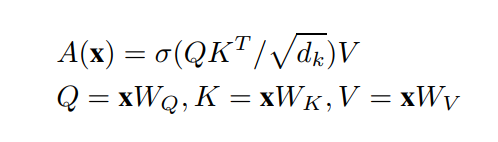
A表示注意力操作符。
由于softmax的非线性导致不能分解为O(N×h+h×N)。本文方法是先用结合律消去softmax来计算。由于应用identity反而会导致退化,所以作者建议使用简单的约束来防止它退化。
本文提出方法叫XNorm,定义如下:
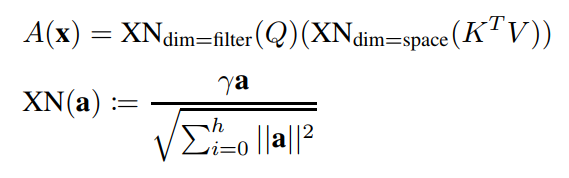
式中,γ为可学习参数,h为嵌入维数。它是简单的l2范数,但它可以适用于的空间维数和q的通道维数,这就是为什么它被称为交叉归一化。
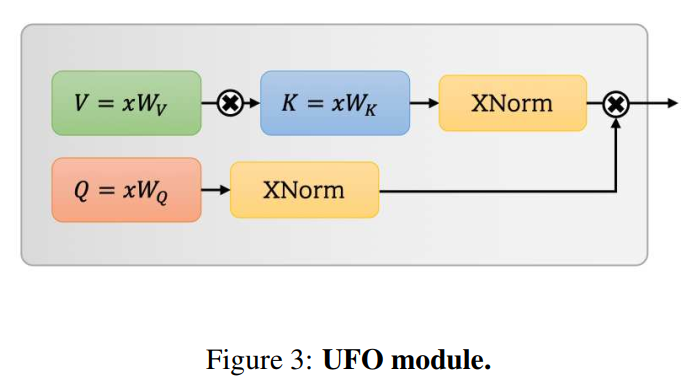
使用关联法则,key和value先相乘,query再相乘。如图3所示。这两个乘法的复杂度都是O(hNd),所以这个过程与n是线性的。
2.2 XNorm
将softmax替换为XNorm
在过程中,key和value直接相乘。与线性核方法相同生成h个聚类。

XNorm应用于query和输出。
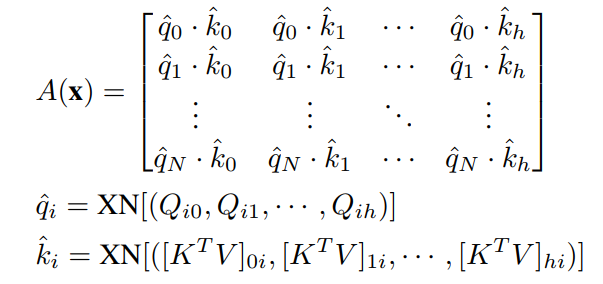
其中x为输入。最后,投影权重标度,加权求和。
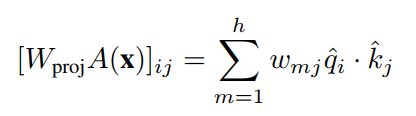
在这个公式中,关系特征是由patches和聚类之间的余弦相似度定义的。XNorm将query和clusters限制为单位向量。它通过规范化它们以缩小范围,防止它们的value抑制关系属性。如果它们有任意值,则注意力区域太依赖于初始化。
然而,这种解释不足以解释原因XNorm必须是l2标准化形式。在这里介绍另一种理论观点,考虑简单的物理模拟。
考虑残差连接,任意模块的输出公式为:
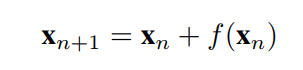
其中n和x表示当前深度和输入图像。假设x为某物体的位移,n为时间,则上式重新定义为:

大部分神经网络是离散的,所以∆t是常数。(简便起见,设∆t=1)残差项表示速度,与力相同,∆t=1。
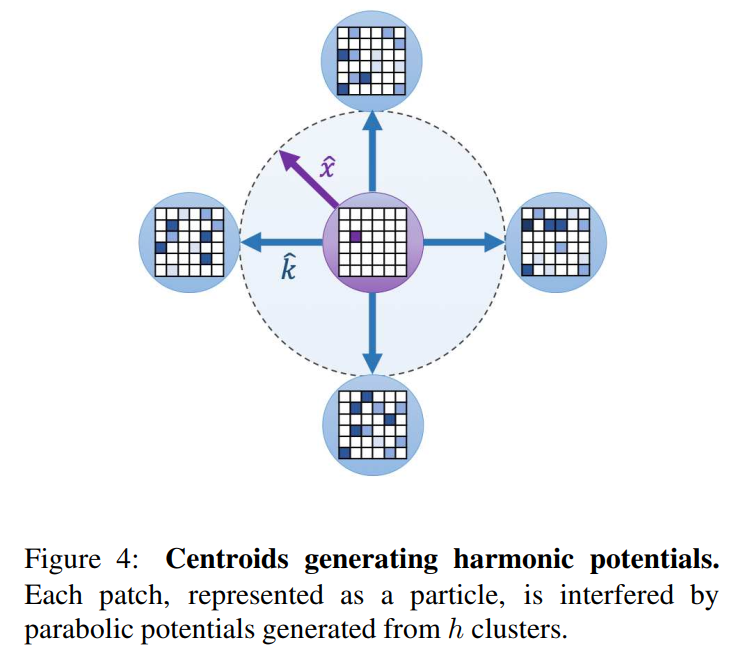
在物理学中,胡克定律被定义为弹性向量k与位移向量x的点积。弹性力产生调和势U是的函数。从物理上讲,势能干扰了粒子通过它的运动路径。(为了便于理解,想象一个球沿着抛物线形状的轨道移动)
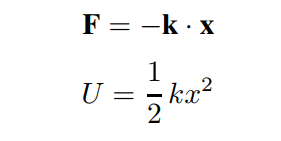
以上公式一般用来近似分子在x≈0处的势能。对于多分子,利用弹性的线性,
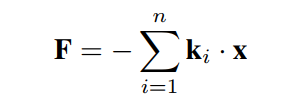
除了上面的公式没有归一化。假设k的个数很小,那么k就太大了。如果某个粒子绕着它们运动,它就不容易逃脱。在这种情况下,只存在两种情况。1. 崩溃了。粒子沿最大k方向排列。关系特征被忽略了。一些x大的粒子在坍缩中幸存下来。
Collapsed。粒子沿最大k的方向排列。 Relational features are neglected。一些x大的粒子在坍缩中幸存下来。
这与前一部分提到的情况完全相同。XNorm强制所有向量为单位向量,以防止这种情况发生。换句话说,XNorm不是标准化,而是约束。
在注意力模块中,FFN是不可忽视的。然而,这里有一个简单的解释。FFN是静态的,不依赖于空间维度。在物理上,这类函数表示谐振子方程的驱动力。
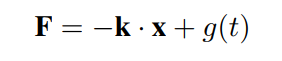
这就起到了放大器或减速器的作用,增强或消除与空间关系无关的特征。
3UFO-ViT
构建UFO-ViT模型采用了早期视觉转换器模型中的一些架构策略。在本节将介绍几种架构优化技术。总体结构如图2所示。
1、Patch embedding with convolutions
最近的一些研究表明Patch embedding with convolutions可以较好地训练ViT,而不是线性投影。
2、Positional encoding
使用位置编码作为可学习参数。
3、Multi-headed attention
本文所设计的模块是多方向的,以便更好的正则化。将公式3中的γ参数应用于所有Head以衡量每个Head的重要性。
4、Local patch interaction
为自注意力模块设计额外的模块来提取局部特征,目前已不是什么特别的想法。作者选择其中最简单的方法,3×3深度可分离卷积。采用早期在xCiT中提出的LPI,使用堆叠的2个conv-bn-GELU层。
5、Feed-forward network
与传统基于Transformer的模型一样,本文的模型使用4维隐藏MLP的point-wise feed-forward。
6、Class attention
在ImageNet1k实验中使用了CaiT中提供的类注意力层。它帮助Class Token收集空间信息。为了减少计算,只在Class Token上计算Class attention。这与原始文件是一样的。注意,Class Attention由UFO模块组成,而CaiT使用正常的自注意力模块来进行Class attention。
4实验
4.1 Image Classification
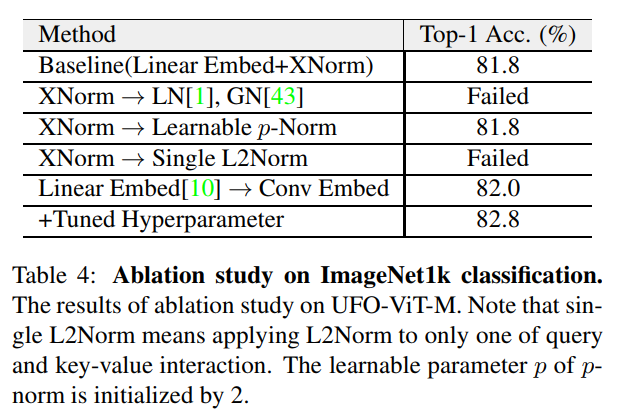
消融研究重点是XNorm的重要性,以及在3.3节中解释过的架构优化。作者试验了各种归一化方法。大多数其他归一化方法都不能减少损失。它可以是证明本文的理论解释是合理的隐性证据之一。有趣的是,应用single L2Norm的性能也很差。
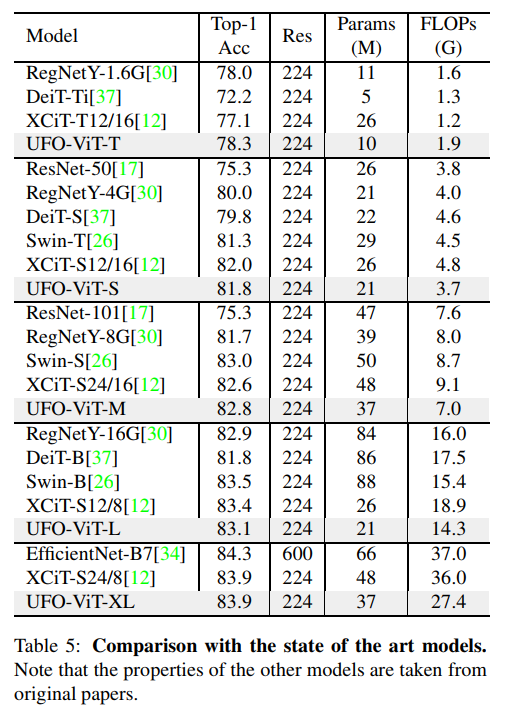
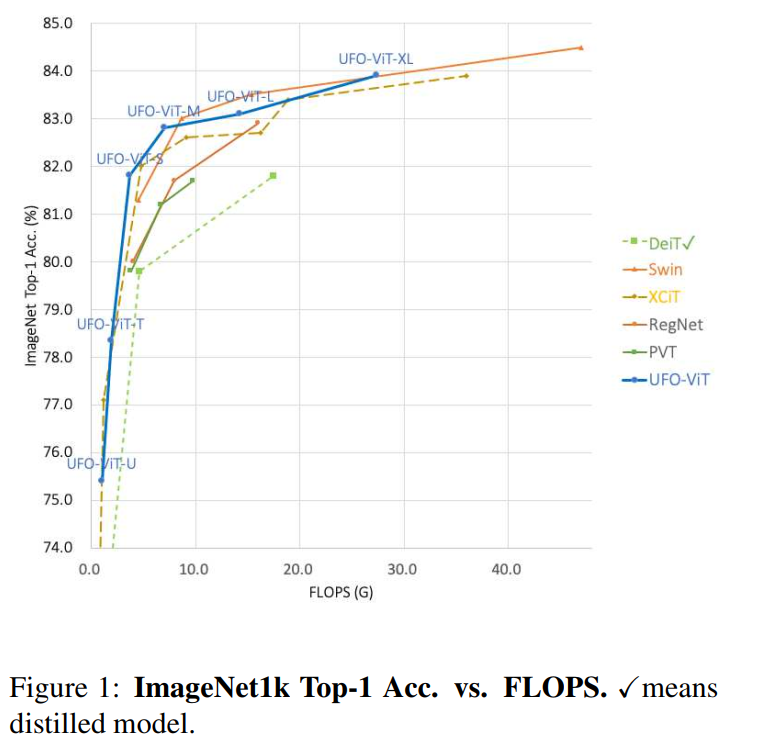
用DeiT对三种具有相同结构设计方案的模型进行了实验。如图1所示,所有的模型都显示出比大多数基于Transformer的并发模型更高的性能和参数效率。此外,本文提出的模型在复杂性和数据效率方面有优势,而原始的ViT需要更大的额外数据集,如JFT-300M或ImageNet21k。

4.2 Object Detection with Mask R-CNN

比较CNN和基于Transformer的目标检测和实例分割任务。为了公平比较,所有结果的实验环境都是相同的。所有模型都是在ImageNet1k数据集上预训练的。
本文模型明显优于基于CNN的模型。而且,与容量较低的最先进的视觉Transformer相比,它们取得了更高或更有竞争力的结果。但是使用相同的设计空间,XCiT显示的结果稍微好一些。可能是XCiT模型有更大的嵌入空间d。UFO-ViT-B在bbox检测任务上的表现略低于UFO-ViT-M,但在较小的bbox和整体实例分割得分上更好。
5参考
[1].UFO-ViT: High Performance Linear Vision Transformer without Softmax
6推荐阅读

Transformer-Unet | 如何用Transformer一步一步改进 Unet?

高效Transformer | 85FPS!CNN + Transformer语义分割的又一境界,真的很快!

【书童的学习笔记】集智小书童建议你这么学习Transformer,全干货!!!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题