
YOLOX-ViT来啦|怎么才有效?YOLOX与Transformer用知识蒸馏交出完美答卷
点击下方卡片,关注「集智书童」公众号

在本文中,作者提出了YOLOX-ViT这一新型目标检测模型,并研究了在不牺牲性能的情况下,知识蒸馏对模型尺寸减小的有效性。聚焦于水下机器人领域,作者的研究解决了关于较小模型的可行性以及视觉Transformer层在YOLOX中影响的关键问题。此外,作者引入了一个新的侧扫声纳图像数据集,并使用它来评估作者的目标检测器的性能。
结果显示,知识蒸馏有效减少了墙体检测中的误报。另外,引入的视觉Transformer层在水下环境中显著提高了目标检测的准确性。
YOLOX-ViT中的知识蒸馏源代码:https://github.com/remaro-network/KD-YOLOX-ViT
1 Introduction
在过去的几十年里,探索海洋环境的兴趣日益增长,这导致了水下活动范围的扩大,如基础设施开发[1]和考古探索[2]。由于水下条件的不可预测和通常是未知的特点,自主水下航行器(AUVs)在执行从调查到维护等各种任务中变得至关重要。AUVs能够根据预定义计划进行数据收集和执行水下操作。
然而,水下环境的复杂性要求提高决策能力,因此需要深入了解航行器所处的环境。基于深度学习的计算机视觉技术为这种场景下的嵌入式实时检测提供了一个有前景的解决方案[3]。然而,标准DL模型的大尺寸对于AUVs来说在电力消耗、内存分配以及实时处理需求方面提出了重大挑战。最近的研究集中在了模型简化上,以促进在嵌入式系统上实施DL模型[4]。
本文通过对以下方面的贡献,为这项工作添砖加瓦:
提升当前最先进的目标检测模型YOLOX,通过整合一个视觉Transformer层,形成了YOLOX-ViT模型。
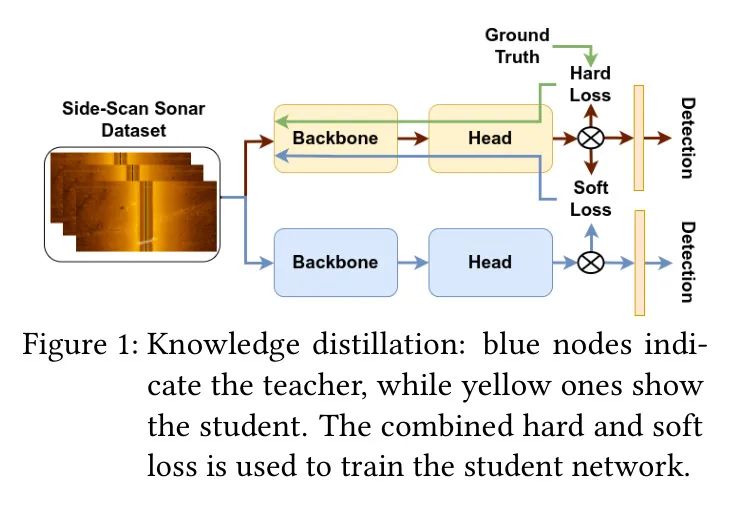
实现一种知识蒸馏(KD)方法,以提高较小型的YOLOX-ViT模型(如YOLOX-Nano-ViT,见图1)的性能。
引入一种新型的侧扫声纳(SSS)数据集,专门用于墙壁检测。
2 Related Work
目标检测。 目标检测是计算机视觉(CV)中的基本任务,旨在数字图像中检测特定类别的视觉目标[5]。其目标是开发高效的算法,为CV应用提供必要的信息:_“哪些目标在哪里?”_。这些方法的质量通过检测准确性(分类和定位)和效率(预测时间)来衡量。这些方法力求在准确性和效率之间找到一个实用的折中方案。深度学习[6, 7]的日益普及,在目标检测方面取得了显著突破。因此,它被广泛应用于许多实际应用中,如自动驾驶[8]、机器人视觉[9]和视频监控[10]。
基于深度学习的目标检测器分为“两阶段检测器”和“一阶段检测器”[5]。值得注意的是,You Only Look Once(YOLO)是一种具有代表性的单阶段检测器[11],以其速度和有效性而闻名[12, 13]。YOLO的简单之处在于它能够直接通过神经网络输出边界框位置和类别[13]。在过去的几年中,引入了各种YOLO版本,如YOLO V2[14]、YOLO V3[15]、YOLO V4[16]、YOLO V5[17]和YOLOX[18]。YOLOX,一个 Anchor-Free 版本(附录B中提供详细解释),采用了更简单的设计,性能更优,旨在弥合研究与应用之间的差距[18]。
知识蒸馏。 如第1节所述,车载深度学习模型必须满足实际生活中的限制,如效率和准确性。较大的模型通常因为能够学习复杂的关系而获得更好的结果,但它们伴随着更高的计算资源消耗。在保持性能的同时减小模型尺寸的研究一直在进行中,包括专注于移除较不关键的神经元或权重[model pruning]的研究[19, 20]。
G. Hinton等人[21]引入了知识蒸馏(KD)用于图像分类,通过使用一种新的损失函数,将知识从训练良好的大模型(教师)传递到小模型(学生)。这个损失函数结合了_硬目标损失_
和_蒸馏损失_
,其中前者指导预测向真实标签靠近,后者利用大模型的知识来调整小模型的行为。损失函数表达为
,其中
是一个调节硬损失和软损失项的参数。
陈等人[4]证明了知识蒸馏(KD)在压缩单次射击检测器(SSD)模型中的有效性,并引入了一种改进方法,该方法使用基于中间 Backbone 逻辑的“提示”损失函数。魏等人[22]提出了一种新颖的方法,学生模型同时从教师模型的最终输出和中间特征表示中学习,这提高了复杂场景下的性能。张等人[23]为Faster R-CNN定制了KD技术,在不牺牲检测准确性的情况下实现了效率提升。杨等人[24]将KD应用于YOLOv5,使用YOLOv5-m作为教师模型,YOLOv5-n作为学生模型进行铃型检测,这使得YOLOv5-n的mAP
提高了大约
。
3 YOLOv-ViT
由Vaswani等人[25]提出的Transformers最初是为自然语言处理设计的,它在处理序列数据方面被证明是有效的,并且超越了当时的最新技术水平。Dosovitskiy等人[26]引入了名为ViT的视觉Transformer,这是首个计算机视觉Transformer模型,在没有卷积层的情况下,在图像识别任务上取得了最先进的表现。Carion等人[27]提出了DETR(DEtection TRansformer)用于目标检测,直接预测集合(边界框、类别标签和置信度得分),无需单独的区域 Proposal 和细化阶段。
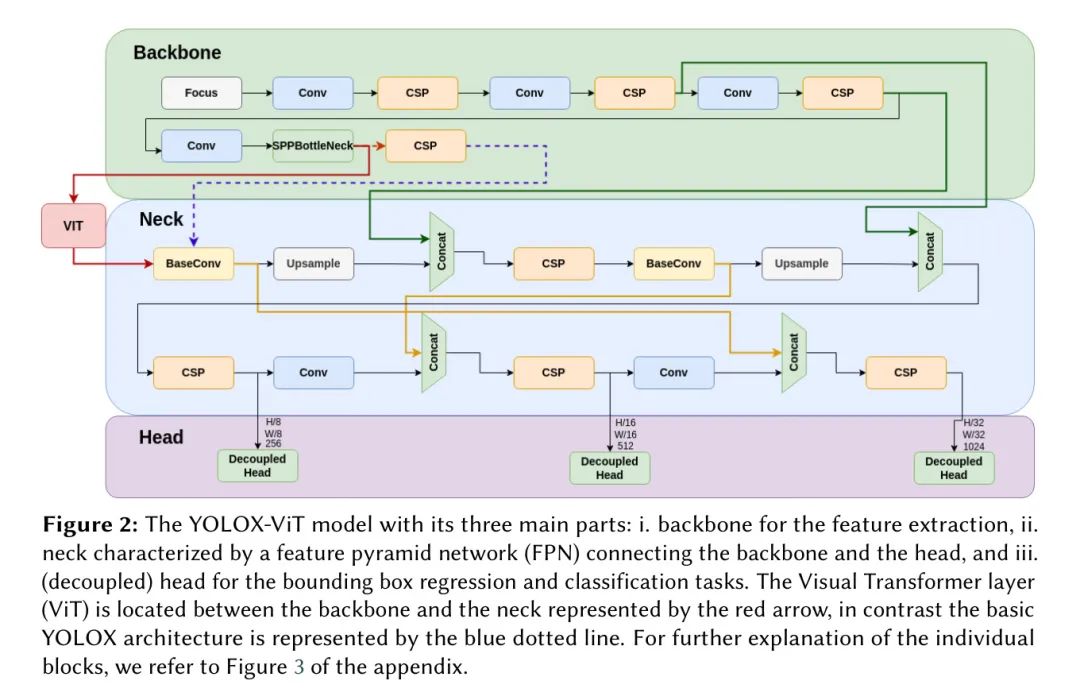
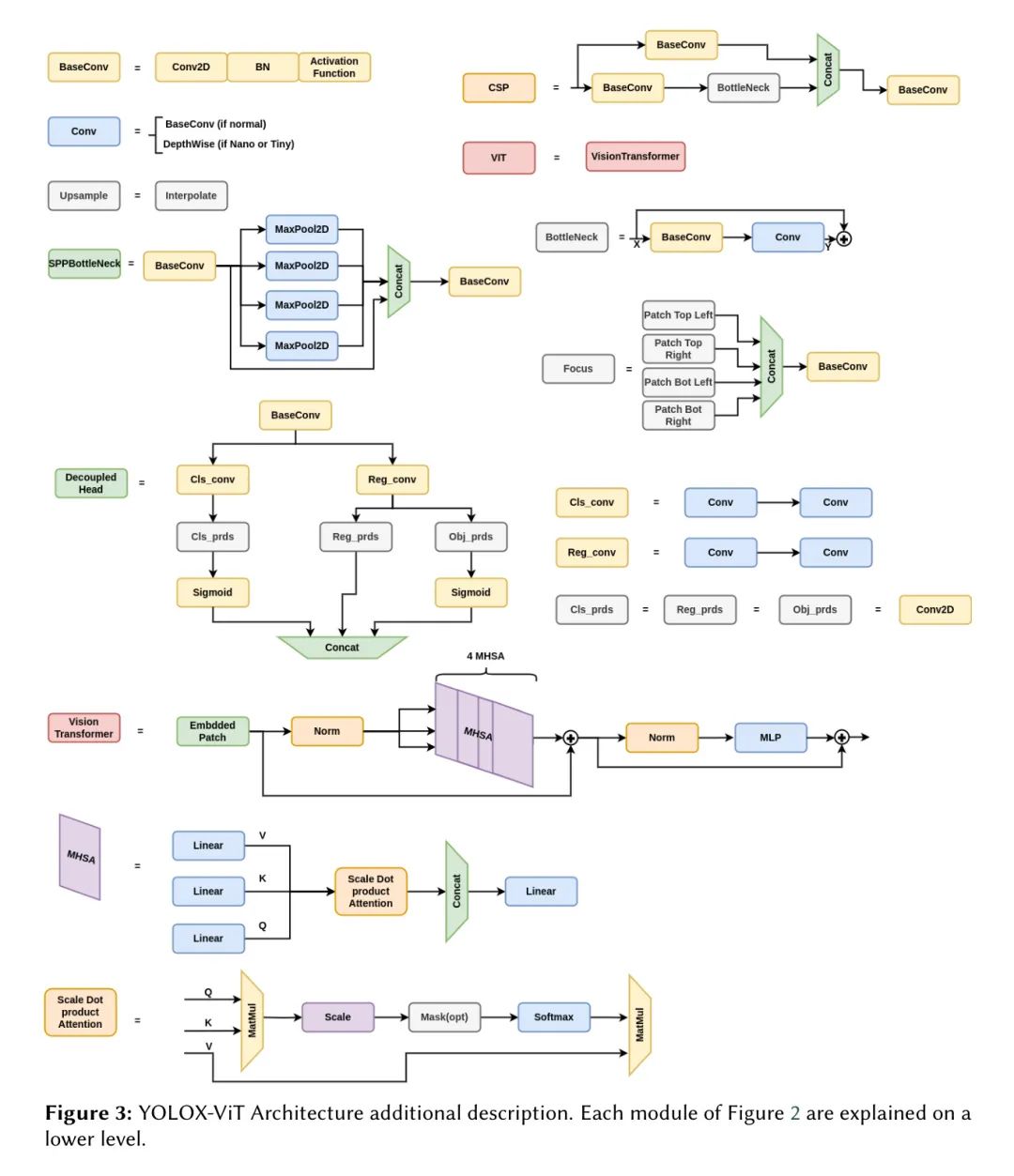
关于ViT的进一步描述可以在附录的C节中找到。将Transformer与CNN集成在一起,可以增强在目标检测任务中的特征提取,结合了CNN的空间层次和Transformer的全局上下文。Yu等人[28]提出了YOLOv5-TR用于集装箱和沉船检测。Aubard等人[3]展示了使用YOLOX可以实现5.5%的性能提升。作者的论文建议通过在_SPPP瓶颈_层末端的主干网络和 Neck 之间加入一个Transformer层(见图2),来增强YOLOX模型的特征提取能力。ViT层由4个多头自注意力(MHSA)子层组成。
Underwater SSS Image Dataset
声纳墙检测数据集(SWDD)包括在波尔图莱索斯港使用Klein 3500声纳在轻型自主水下航行器(LAUV)上收集的侧扫声纳(SSS)图像,该航行器由OceanScan Marine Systems & Technology公司操作。调查沿着港口墙壁产生了216张图像。由于当前数据集中的数据量较小,因此使用了数据增强方法来增加数据量并提高模型的鲁棒性。本文中使用的数据增强引入了噪声、翻转以及噪声-翻转组合变换。
噪声是一种高斯噪声,表示为 。其中
是噪声图像中位于位置
的像素的强度值,
是位置
的原始强度,而
表示从均值为0、方差为
的高斯分布中抽取的样本。此数据集的标准差
等于
。
水平翻转被描述为 。它沿着图像的垂直轴进行镜像处理,其中
是图像的宽度,
实际上改变了每个像素的水平位置。
该数据集包含“墙壁”和“无墙壁”两类,共有2.616个标记样本。为了进行稳健的训练,作者将原始图像和增强图像结合在一起,将数据集分为
用于训练,
用于验证,以及
用于测试。每张SSS图像是在每侧75米的范围内以900千赫兹的频率生成的,由500条连续线组成,从而形成一个
像素的分辨率。为了与计算机视觉算法兼容,作者将图像缩放到
。
4 Knowledge Distillation
考虑到YOLOX的架构,如第2节所述,知识蒸馏(KD)应用于特征金字塔网络(FPN)的每个解耦头。由于这种架构的特殊性,KD过程涉及计算学生模型与教师模型之间每个FPN输出的不同损失函数,包括分类、边界框回归和目标性得分。
一般的KD损失函数定义为:
,
其中
对于每种类型的损失(分类、目标性、边界框),损失函数分解在每个FPN输出的结果中,得到以下公式:
分类损失:
边界框回归损失:
目标性损失(Objectness Loss):
在作者的实验中,
被制定为包含硬损失和软损失组件,软损失项(
,
和
)各自乘以0.5的系数,即
。这种方法确保了虽然软损失组件对于将细致的知识从教师模型传递到学生模型至关重要,但硬损失仍然在指导学生模型的学习过程中占主导地位,确保它不会偏离基本任务目标太远。
此外,本文使用YOLOX-L模型作为教师网络,YOLOX-Nano作为学生网络。由于YOLOX的在线随机数据增强,在线知识蒸馏的过程如下:
i. 训练YOLOX-L,
ii. 初始化YOLOX-Nano训练,
iii. 对于每个批次,使用YOLOX-L进行推理,
iv. 计算YOLOX-L和YOLOX-Nano的FPN逻辑值之间的
,
v. 将
与
相结合。
由于每次迭代都需要进行推理,这种在线知识蒸馏方法需要一周的时间。为了减少时间上的投入,本文采用了无需在YOLOX-Nano训练期间进行随机在线数据增强的离线知识蒸馏方法。工作流程如下:
i. 训练YOLOX-L,
ii. 执行YOLOX-L推理,保存每个训练样本的FPN逻辑值,
iii. 启动YOLOX-Nano训练,
iv. 为每张图像检索相应的FPN逻辑值,
v. 计算YOLOX-L和YOLOX-Nano每个FPN输出的逻辑值之间的
,
vi. 将
与
相结合。
5 Experimental Evaluation
除了在训练期间获得的初步结果外,作者还实施了一个在线验证过程,以评估模型在真实世界数据上的表现。这一评估围绕一个来自不同调查的6分57秒的视频进行。为了进行彻底的评估,作者精确计时并手动记录了视频分析过程中的真阳性和假阳性检测。此外,作者还从视频中提取并标注了帧,以便更精确地评估模型的准确性,总共标注了6,243张图像。
随后,为每个模型在视频上的推理保存了预测边界框。利用_Object Detection Metrics_仓库,作者计算了如_TP_、_FP_、_Pr_(精确度)、_AP
_和_AP_等指标。这一评估过程应用于YOLOX-L和YOLOX-Nano模型的标准架构以及YOLOX-ViT变体。如表1所示,这一实验分为两部分,详细说明在第四部分中。第一部分涉及使用在线随机数据增强进行训练,而第二部分没有使用。
对YOLOX-L和YOLOX-L-ViT模型之间的比较分析,特别是在提取图像的实验中,揭示了在线数据增强模型的一些局限性。与没有在线数据增强的YOLOX-L-noAug和YOLOX-L-ViT-noAug模型相比,YOLOX-L和YOLOX-L-ViT模型的表现不佳。这种差异表明,移除在线数据增强可能会提高模型性能,而有限数据集的大小可能会不成比例地影响较大模型(如YOLOX-L)的效率。视觉实验也证实了这一点,即YOLOX-L-noAug在保持检测时间更长方面优于YOLOX-L,但假阳性增加了大约
。此外,视觉实验表明YOLOX-L-ViT在检测性能上提供了更优越的表现。如表1所示,集成了ViT层的增强型YOLOX模型在L上提高了大约
的检测率,在Nano上提高了大约
。然而,视觉解释表明,与没有在线数据增强的基本架构相比,ViT增强型模型的表现还是有所不足。尽管检测率有所提高,但假阳性也同样增加,这表明模型可能过于泛化地将明亮物体识别为墙壁。
目标是利用来自L和L-ViT作为“教师”的知识蒸馏,以减少小型模型Nano-noAug和Nano-ViT-noAug中的“假阳性”率,这些小型模型被指定为“学生”。表2显示,KD有效地降低了“假阳性”率。此外,ViT层进一步减少了学生模型中的“假阳性”。具体来说,对于Nano-noAug,基础模型将“假阳性”降低了约0.3%,而ViT变体则降低了大约6%。
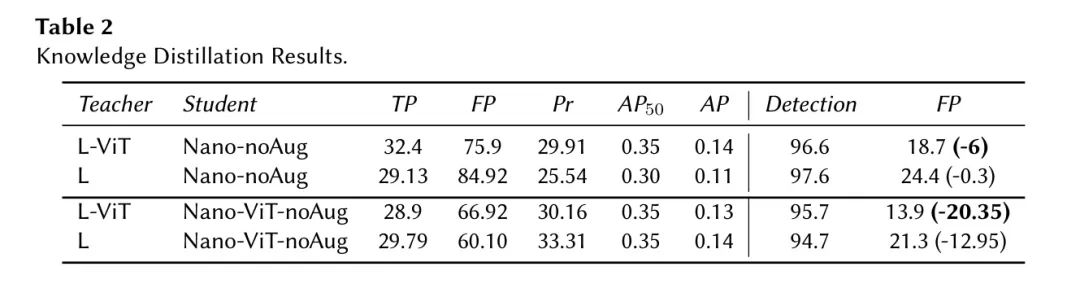
Nano-ViT-noAug模型,以基本模型为指导,将误报(False Positives)减少了大约12.95%,而ViT版本则实现了约20.35%的降低。这些结果强调了ViT层帮助模型专注于更有效的特征提取的能力。
6 Conclusion
总之,作者的研究为在水下机器人和自主水下航行器中提高侧扫声纳图像目标检测提供了一个框架。引入YOLOX-ViT并结合应用知识蒸馏技术,已证明在减少模型大小的同时,能够保持高检测精度。
作者的方法通过将视觉Transformer层集成到YOLOX的主干网中,并在解耦的 Head 之间进行知识蒸馏,得出了前景看好的结果。具体来说,知识蒸馏成功减少了墙壁检测中的误报,展示了它在提高目标检测模型效率方面的实际效用。此外,ViT层的融合显著提升了整体准确性,凸显了这种架构增强在水下图像分析中的潜力。
随着自主水下航行器在检测和监控中发挥关键作用,确保目标检测模型的可靠性和鲁棒性变得至关重要。作者未来的工作将集中在以下三个方面:
i. 扩充SSS数据集以提升L指标,
ii. 结合在线数据增强实施知识蒸馏(KD),
iii. 开发全面的安全验证方法,应对真实水下场景中潜在的挑战和不确定性。
通过基于安全驱动准则细化模型,作者的目标是提高目标检测框架的实际应用价值,为在精确性和安全性同等重要的环境中部署自主水下航行器这一更广泛的任务做出贡献。
Function definitions
Softmax.
在公式中,
是输入向量
的第
个元素的指数,分母是向量
中所有元素的指数之和。这确保了softmax的输出是一个概率分布,每个元素的范围在0到1之间。
LogSoftmax.
自然对数的softmax函数。
Mean Squared Error (MSE.)
它通过计算预测值与实际值之间差的平方的平均值,来衡量回归任务中模型的误差量化。MSE(均方误差)的公式如下:
其中
是实际值,
代表预测值,而
是观测值的数量。
Binary Cross-Entropy (BCE).
它衡量分类模型性能在0到1之间。BCE(二元交叉熵)方程如下:
其中
是实际标签(0或1),
是实例属于类别1的预测概率,而
是样本的数量。
Kullback-Leibler散度(KL散度)。 Kullback-Leibler散度衡量了一个概率分布与第二个参考概率分布的偏差程度。KL散度的公式如下:
和
是两个概率分布。KL散度衡量了使用
近似
时丢失的信息;值越低表示两个分布之间的匹配越紧密。
Model evaluation metrics
精确度。
精确度是目标检测和分类任务中的一个关键性能指标。它量化了阳性预测的准确性。TP(真正例)和FP(假正例)分别是真正阳性和假阳性的检测结果。更高的精确度值表明假阳性率更低,这意味着当模型预测为阳性类别时,它更有可能是正确的。
AP50 这个术语在人工智能领域通常指的是“Average Precision (平均精度) at IoU (Intersection over Union) threshold 0.50”。这里,“AP”代表平均精度,而“50”指的是交并比阈值为0.50时的性能指标。这个指标常用于评估目标检测算法的性能,即在预测边界框与真实边界框至少有50%重叠时,算法的平均精度表现。 “该模型在Pascal VOC数据集上达到了0.85的AP50。”
表示在50%的IoU阈值下的平均精度。它是根据IoU为50%时的精度-召回曲线下的面积计算得出的。在这里,
表示在召回 Level
下IoU = 50%时的精度,实际上是在整个召回 Level 上整合精度。
(平均精度)是多IoU阈值下的综合度量,全面评估目标检测性能。它是从50%到95%每个IoU阈值
计算的
的平均值,其中
是考虑的总阈值数。
交并比(IoU)。衡量某个数据集上目标检测器准确性的指标。它特别用于评估目标检测和分割模型。IoU的公式如下:
公式 代表了预测边界框和真实边界框之间的交叠区域。IoU 的值从 0 到 1,其中 1 表示预测边界框与真实边界框完全匹配。较高的 IoU 值意味着目标检测模型的准确度更高。
Knowledge Distillation Losses
KD Bounding Box Loss.
这个公式计算了边界框回归的知识蒸馏损失。它采用均方误差(MSE)来比较学生模型输出的边界框回归结果(S_reg
)与教师模型输出的结果(T_reg
),这是在
个数据样本上的平均。
KD Object Loss.
这个方程通过二进制交叉熵(BCE)计算目标性预测的KD损失。它评估了学生模型(S_obj
)和教师模型(T_obj
)预测的目标性分数之间的差异。
KD Class Loss.
在这里,量化了在知识蒸馏(KD)中的类别预测损失。Kullback-Leibler(KL)散度衡量了学生模型类别预测(S_cls
)的对数-softmax输出与教师模型的softmax输出(T_cls
)之间的差异。
Overall Soft Loss.
在知识蒸馏(KD)过程中,总的软损失是个体KD损失(边界框、目标性和类别预测)的加权总和。权重
、
和
分别对应于边界框、目标性和类别组成部分。
Appendix B Yolov
YOLOX是YOLO的 Anchor-Free 点版本,设计更简单,但性能更优。它的目标是弥合研究界与工业界之间的差距[18]。
在目标检测模型中,_ Anchor 点_ 的概念是一种原则,即在执行任何检测之前,在图像的四周使用预定义的边界框。它可以被视为一种“预先射击”,这应该能提高模型的效率。由于其对于目标检测器的高效性和准确性,大多数最先进的(SOTA)目标检测模型都是基于 Anchor 点的,例如Faster R-CNN、YOLO和SSD。
然而,这项技术有几个局限性,比如固定的 Anchor 框大小和比例,大量的 Anchor 框, Anchor 框配置的敏感性,重叠 Anchor 框的处理,定位准确性,尺度不变性,类别不平衡以及训练复杂性。由于这些限制,最近的目标检测研究专注于 Anchor-Free 框模型,例如YOLOX。
Appendix C Vision Transformer (ViT)
视觉 Transformer (Vision Transformer)。在视觉 Transformer 中,一幅图像被划分成多个块,然后展平并线性嵌入到一个 Token 序列中。假设有一个尺寸为
的图像
被划分为
个尺寸为
的块。每个块被展平并线性投影到一个
维嵌入空间。这个过程可以描述如下:
其中
是一个大小为
的嵌入矩阵,而
是偏置向量。
缩放点积注意力。 缩放点积注意力机制根据 Query
、键
和值
计算注意力得分。首先将键和 Query 相乘,并按键的维度
的平方根进行缩放。然后,应用softmax函数以获得权重,这些权重与值相乘以产生输出。该方程由下式给出:
多头自注意力(MHSA)。MHSA并行运行多个注意力机制(头)。每个头对不同的 Query 、键和值投影应用注意力函数。这些头的输出随后被连接起来,并乘以一个输出权重矩阵
。该过程定义如下:
其中每个 Head 的计算方式为:
在这里,
、
和
是每个头
的参数矩阵。
Transformer编码器。 Transformer编码器包括一系列相同层的堆叠,每层由两个子层组成:一个MHSA(多头自注意力机制)和一个位置全连接前馈网络。每个子层的输出都通过层归一化进行处理。该层的表示为:
参考
[1].Knowledge Distillation in YOLOX-ViT for Side-Scan Sonar Object Detection.

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)


想要了解更多:
前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
行业技术方案👉「AI安防、AI医疗、AI自动驾驶」
AI模型部署落地实战👉「CUDA、TensorRT、NCNN、OpenVINO、MNN、ONNXRuntime以及地平线框架」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
免责声明
凡本公众号注明“来源:XXX(非集智书童)”的作品,均转载自其它媒体,版权归原作者所有,如有侵权请联系我们删除,谢谢。
点击下方“阅读原文”,
了解更多AI学习路上的「武功秘籍