
KITTI数据集简介与使用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

摘要:本文融合了Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite和Vision meets Robotics: The KITTI Dataset两篇论文的内容,主要介绍KITTI数据集概述,数据采集平台,数据集详细描述,评价准则以及具体使用案例。本文对KITTI数据集提供一个较为详细全面的介绍,重点关注利用KITTI数据集进行各项研究与实验。
KITTI数据集概述
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成[1] ,以10Hz的频率采样及同步。总体上看,原始数据集被分类为’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。对于3D物体检测,label细分为car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc组成。

数据采集平台
如图-1所示,KITTI数据集的数据采集平台装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne 64线3D激光雷达,4个光学镜头,以及1个GPS导航系统。具体的传感器参数如下[2] :
• 2 × PointGray Flea2 grayscale cameras (FL2-14S3M-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
• 2 × PointGray Flea2 color cameras (FL2-14S3C-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
• 4 × Edmund Optics lenses, 4mm, opening angle ∼ 90◦, vertical opening angle of region of interest (ROI) ∼ 35◦
• 1 × Velodyne HDL-64E rotating 3D laser scanner, 10 Hz, 64 beams, 0.09 degree angular resolution, 2 cm distance accuracy, collecting ∼ 1.3 million points/second, field of view: 360◦ horizontal, 26.8◦ vertical, range: 120 m
• 1 × OXTS RT3003 inertial and GPS navigation system, 6 axis, 100 Hz, L1/L2 RTK, resolution: 0.02m / 0.1◦
图-1 数据采集平台
如图-2所示为传感器的配置平面图。为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。为了方便传感器数据标定,规定坐标系方向如下[2] :
• Camera: x = right, y = down, z = forward
• Velodyne: x = forward, y = left, z = up
• GPS/IMU: x = forward, y = left, z = up
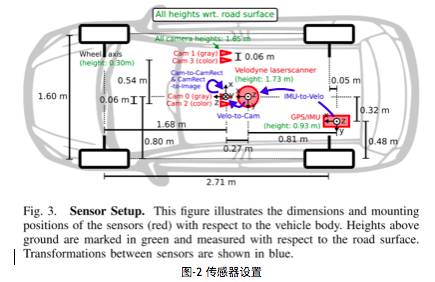
图-2 传感器设置
Dataset详述
图-3展示了KITTI数据集的典型样本,分为 ’Road’, ’City’, ’Residential’, ’Campus’ 和’Person’五类。原始数据采集于2011年的5天,共有180GB数据。

图-3 KITTI数据集的样本,展现KITTI数据集的多样性。
3.1 数据组织形式
论文[2] 中提及的数据组织形式,可能是早期的版本,与目前KITTI数据集官网公布的形式不同,本文稍作介绍。
如图-4所示,一个视频序列的所有传感器数据都存储于data_drive文件夹下,其中date和drive是占位符,表示采集数据的日期和视频编号。时间戳记录在Timestamps.txt文件。
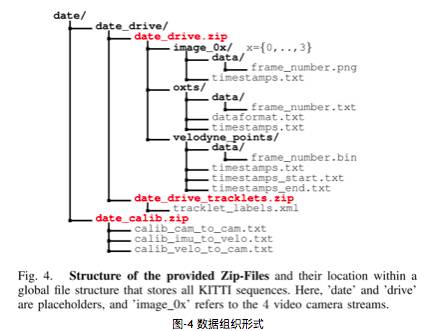
图-4 数据组织形式
对于从KITTI数据集官网下载的各个分任务的数据集,其文件组织形式较为简单。以Object detection为例,下图是Object Detection Evaluation 2012标准数据集中left color images文件的目录结构,样本分别存储于testing和training数据集。
data_object_image_2
|── testing
│ └── image_2
└── training
└── image_2
下图是training数据集的label文件夹目录结构。
training/
└── label_2
3.2 Annotations
KITTI数据集为摄像机视野内的运动物体提供一个3D边框标注(使用激光雷达的坐标系)。该数据集的标注一共分为8个类别:’Car’, ’Van’, ’Truck’, ’Pedestrian’, ’Person (sit- ting)’, ’Cyclist’, ’Tram’ 和’Misc’ (e.g., Trailers, Segways)。论文[2] 中说明了3D标注信息存储于date_drive_tracklets.xml,每一个物体的标注都由所属类别和3D尺寸(height,weight和length)组成。当前数据集的标注存于每种任务子数据集的label文件夹中,稍有不同。
为了说明KITTI数据集的标注格式,本文以Object detection任务的数据集为例。数据说明在Object development kit的readme.txt文档中。从标注数据的链接 training labels of object data set (5 MB)下载数据,解压文件后进入目录,每张图像对应一个.txt文件。一帧图像与其对应的.txt标注文件如图-5所示。

图-5 object detection样本与标注
为了理解标注文件各个字段的含义,需要阅读解释标注文件的readme.txt文件。该文件存储于object development kit (1 MB)文件中,readme详细介绍了子数据集的样本容量,label类别数目,文件组织格式,标注格式,评价方式等内容。下面介绍数据格式的label描述:
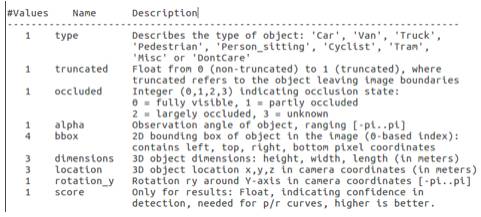
注意,'DontCare' 标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略'DontCare' 区域的预测结果。
3.3 Development Kit
KITTI各个子数据集都提供开发工具 development kit,主要由cpp文件夹,matlab文件夹,mapping文件夹和readme.txt组成。下图以object detection任务的文件夹devkit_object为例,可以看到cpp文件夹主要包含评估模型的源代码evaluate_object.cpp。Mapping文件夹中的文件记录训练集到原始数据集的映射,从而开发者能够同时使用激光雷达点云,gps数据,右边彩色摄像机数据以及灰度摄像机图像等多模态数据。Matlab文件夹中的工具包含读写标签,绘制2D/3D标注框,运行demo等工具。Readme.txt文件非常重要,详述介绍了某个子数据集的数据格式,benchmark介绍,结果评估方法等详细内容。
devkit_object
|── cpp
│ |── evaluate_object.cpp
│ └── mail.h
|── mapping
│ |── train_mapping.txt
│ └── train_rand.txt
|── matlab
│ |── computeBox3D.m
│ |── computeOrientation3D.m
│ |── drawBox2D.m
│ |── drawBox3D.m
│ |── projectToImage.m
│ |── readCalibration.m
│ |── readLabels.m
│ |── run_demo.m
│ |── run_readWriteDemo.m
│ |── run_statistics.m
│ |── visualization.m
│ └── writeLabels.m
└── readme.txt
评价准则Evaluation Metrics
4.1 stereo与visual odometry任务
KITTI数据集针对不同的任务采用不同的评价准则。对于立体图像和光流(stereo and optical flow),依据disparity 和end-point error计算得到平均错误像素数目(average number of erroneous pixels)。
对于视觉测距和SLAM任务(visual odometry/SLAM),根据轨迹终点(trajectory end-point)的误差进行评估。传统的方法同时考虑平移和旋转的误差,KITTI分开评估[1] :
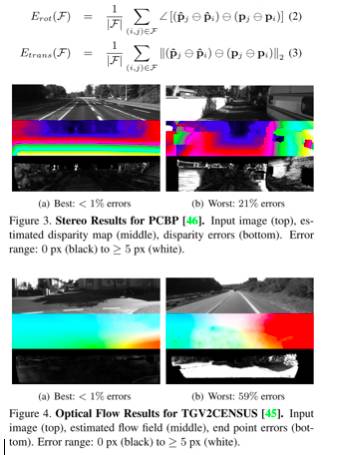
图-6 Stereo和optical flow的预测结果与评估
4.2 3D物体检测和方向预测
目标检测需要同时实现目标定位和目标识别两项任务。其中,通过比较预测边框和ground truth边框的重叠程度(Intersection over Union,IoU)和阈值(e.g. 0.5)的大小判定目标定位的正确性;通过置信度分数和阈值的比较确定目标识别的正确性。以上两步综合判定目标检测是否正确,最终将多类别目标的检测问题转换为“某类物体检测正确、检测错误”的二分类问题,从而可以构造混淆矩阵,使用目标分类的一系列指标评估模型精度。
KITTI数据集采用文献[3] 用到的平均正确率(Average Precision,mAP)评估单类目标检测模型的结果。PASCAL Visual Object Classes Challenge2007 (VOC2007)[3] 数据集使用Precision-Recall曲线进行定性分析,使用average precision(AP)定量分析模型精度。物体检测评估标准对物体漏检和错检进行惩罚,同时规定对同一物体重复且正确的检测只算一次,多余的检测视为错误(假阳性)。

对于KITTI目标检测任务,仅仅评估目标高度大于25pixel的预测结果,将易混淆的类别视为同一类以减少假阳性(false positives)率,并且使用41个等间距recall上的精确值的平均值近似计算分类器的AP。
对于物体方向预测,文献[1] 提出了一种新颖的方法:平均方向相似性,Average Orientation Similarity (AOS)。该指标被定义为:
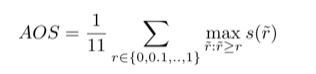
其中,r代表物体检测的召回率recall。在因变量r下,方向相似性s∈[0,1]被定义为所有预测样本与ground truth余弦距离的归一化:
其中D(r)表示在召回率r下所有预测为正样本的集合,∆θ(i) 表示检出物体i的预测角度与ground truth的差。为了惩罚多个检出匹配到同一个ground truth,如果检出i已经匹配到ground truth(IoU至少50%)设置δi = 1,否则δi = 0。
5. 数据使用实践
KITTI数据集的标注信息更加丰富,在实际使用中可能只需要一部分字段,或者需要转换成其他数据集的格式。例如可以将KITTI数据集转换成PASCAL VOC格式,从而更方便地使用Faster RCNN或者SSD等先进的检测算法进行训练。转换KITTI数据集需要注意源数据集和目标数据集的格式,类别标签的重新处理等问题,实现细节建议参考Jesse_Mx[4] 和github上manutdzou的开源项目[5] ,这些资料介绍了转换KITTI数据集为PASCAL VOC格式,从而方便训练Faster RCNN或者SSD等模型。
Reference
Andreas Geiger and Philip Lenz and Raquel Urtasun. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. CVPR, 2012
Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun. Vision meets Robotics: The KITTI Dataset. IJRR, 2013
M. Everingham, L.Van Gool, C. K. I.Williams, J.Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2011 (VOC2011) Results.
Jesse_Mx.SD: Single Shot MultiBox Detector 训练KITTI数据集(1).
http://blog.csdn.net/jesse_mx/article/details/65634482
manutdzou.manutdzou/KITTI_SSD.https://github.com/manutdzou/KITTI_SSD
附录
Fig.7 不同类别物体在数据集中出现的频率(上图);
对于两个主要类别(车辆,行人)主要的方向统计直方图(下图)
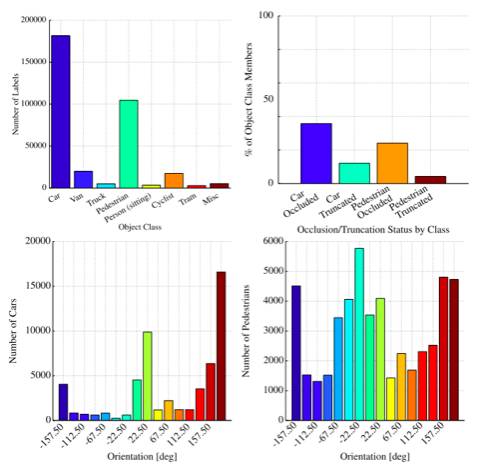
Fig.8 每张图中不同类别物体出现频率统计。
Fig.9 分别为速度,加速度(排除静止状态)统计直方图;视频序列长度统计直方图;每种场景(e.g., Campus, city)的帧数统计直方图。

好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~