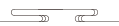让训练更长序列模型成为可能-Sequence Parallelism

前言
自注意力机制是Transformer中的一个关键部件,但其占用显存大小和序列长度呈平方关系,导致我们实际并不能用很长的序列(如BERT是固定为512)。在这篇工作里,我们提出了序列并行(Sequence Parallelism),将序列切分成一个个小块,放置在每一个计算设备上。计算注意力需要将Query和全局的Key交互,受启发于Ring-Allreduce算法,我们以类似的方式实现注意力计算,并称为Ring Self Attention。该并行方式能够与现有的数据并行,模型并行,流水线并行一起使用,实现4D并行
本文是笔者某天早晨看尤洋老师介绍自己夸父AI系统时候提到的他们的一个工作,对系统有兴趣的读者可以观看这期视频:https://www.bilibili.com/video/BV1cZ4y197dY
Sequence Parallelism
左图是流水线并行,右图是模型并行,这两种并行方式已经非常流行了。
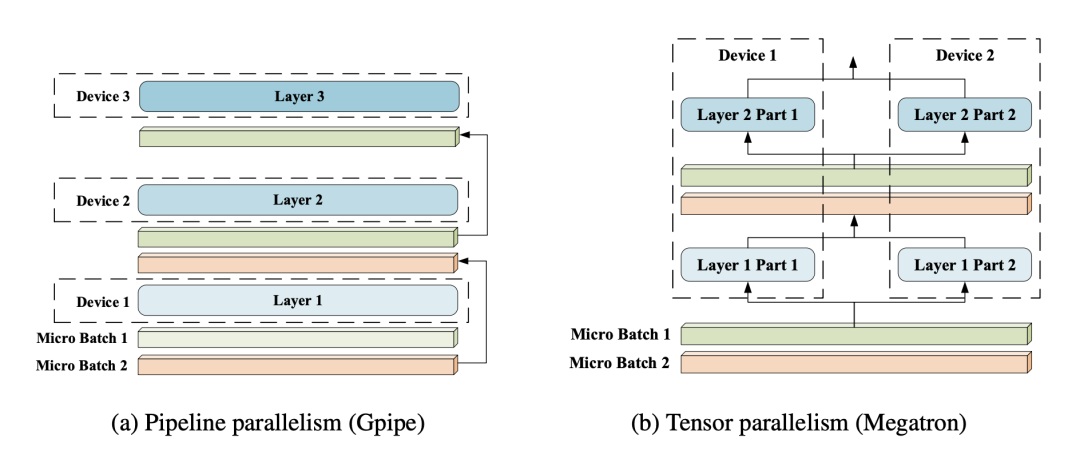
而这里提到的序列并行,则是针对 Transformer 训练更长序列提出的,整体结构图如下:
主要特点是,我们将整一个序列进行切分,分成多个子序列,放置在不同的device上。每一个device上有完整的模型权重,和不同的子序列。 为了方便后续讲解,我们定义符号意义如下:
B batch size L 序列长度 H 全连接层维度大小 A 注意力头维度大小 Z 注意力头的个数 N GPU个数
我们只关注显存占用和通信开销这两方面,下面我们就从这两个角度来分析 Transformer 中的 MLP 模块和自注意力模块。
MLP部分的序列并行
这里我们的MLP特指Transformer的FFN模块,即输入经过两个全连接层,且使用 Adam 优化器:
// 假设输入是 (B, L, H)
dense1 = nn.Linear(H, 4H)
dense2 = nn.Linear(4H, H)
如果是模型并行,那么第一个全连接层的权重将在第1维进行切分,即每个设备上的权重大小为 (H, ),输出结果为 (B, L, 。而第二个全连接层的权重将在第0维进行切分,即每个设备上的权重大小为 (,H),然后进行运算,整个过程所需的显存为:
加起来就是
接下来我们看下序列并行的情况,它在序列维度上切分,那么输入变为(B, , H),第一层全连接层权重还是(H, 4H),输出为(B, , 4H)。此时第二层全连接层权重是(4H, H),输出为(B, , H),类似地我们计算出对应的显存占用:

如果我们假设序列并行是比模型并行省显存的,那么就有一个不等式:
条件为 BL > 32H 时成立。
我们看通信开销方面,因为模型并行对权重进行切分,所以前向过程和后向过程都需要做一次all reduce操作,而序列并行不需要。
自注意力机制的序列并行
补充材料:Ring Allreduce
在正式介绍自注意力序列并行之前,我们先简单介绍 Ring Allreduce算法。
这里笔者推荐一篇博客:ahttps://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
该算法是为了解决多个GPU通信效率低下的问题而产生的,它将多个GPU连成一个环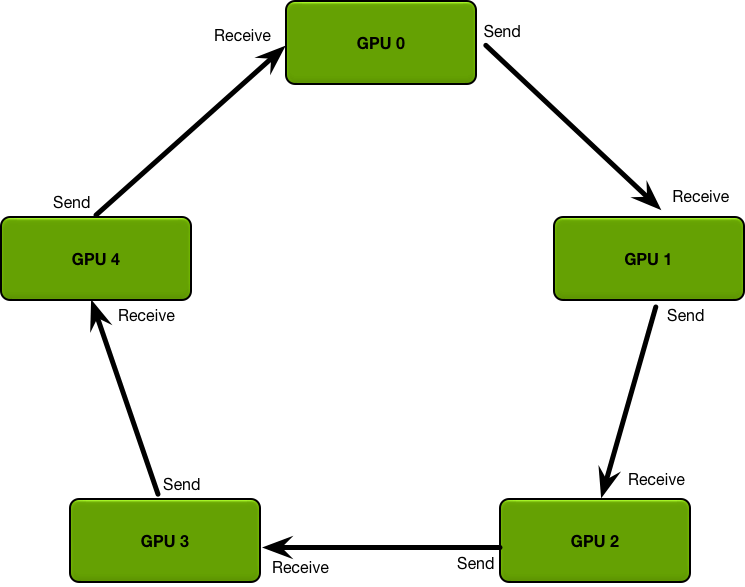
我们对每张卡上的数据进行分快,初始状态为:
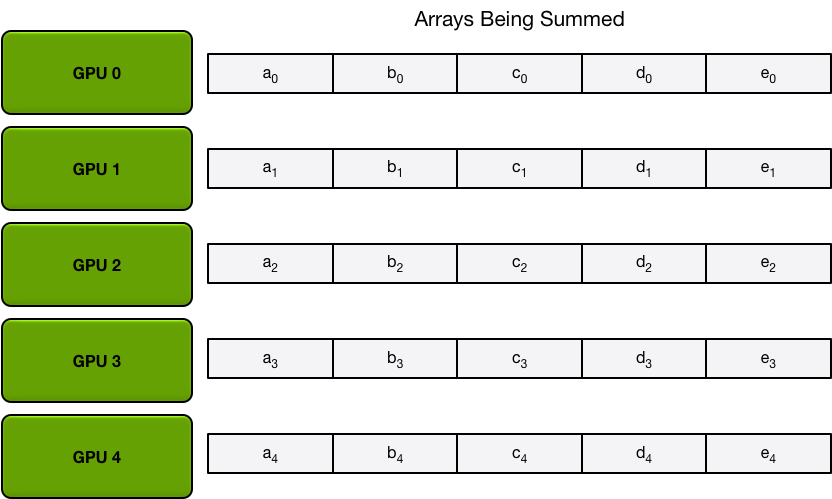
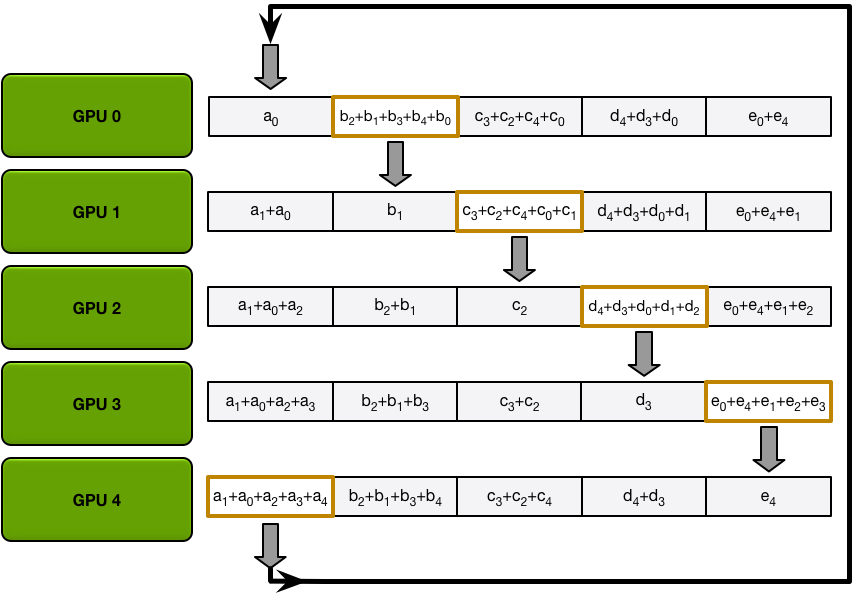
第一步做 scatter-reduce,每张卡在每次iter里同时send和recieve一个数据块:第一个iter:
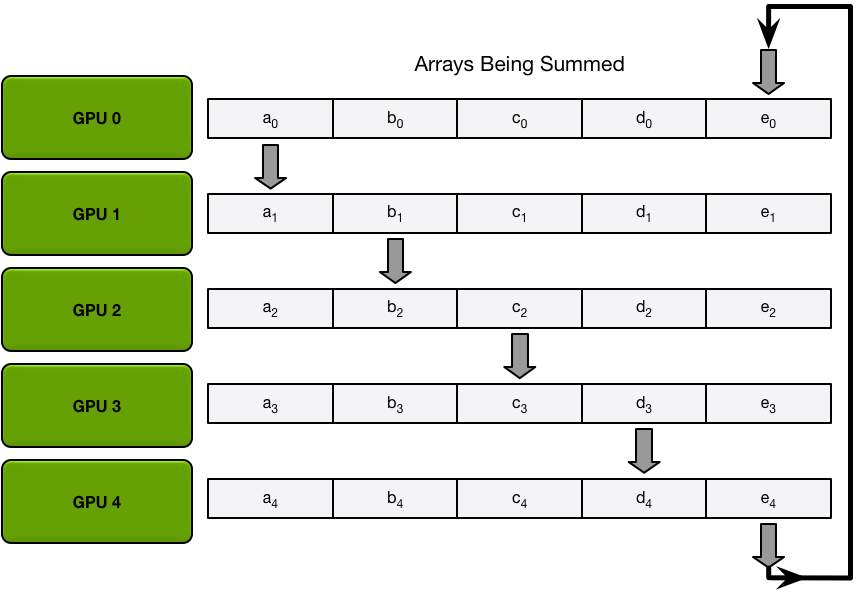
第二个iter:
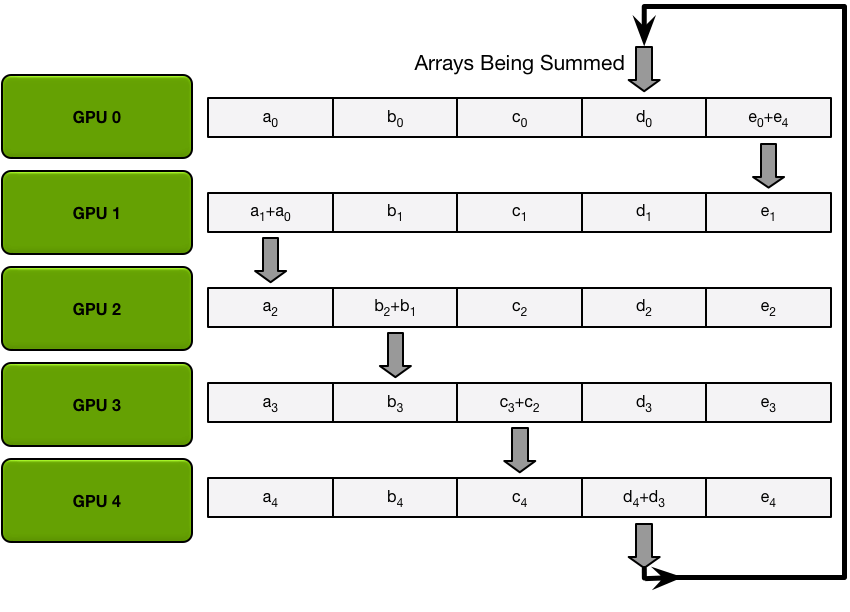
这样最终结果是,每张卡都有一个完整的数据块总和
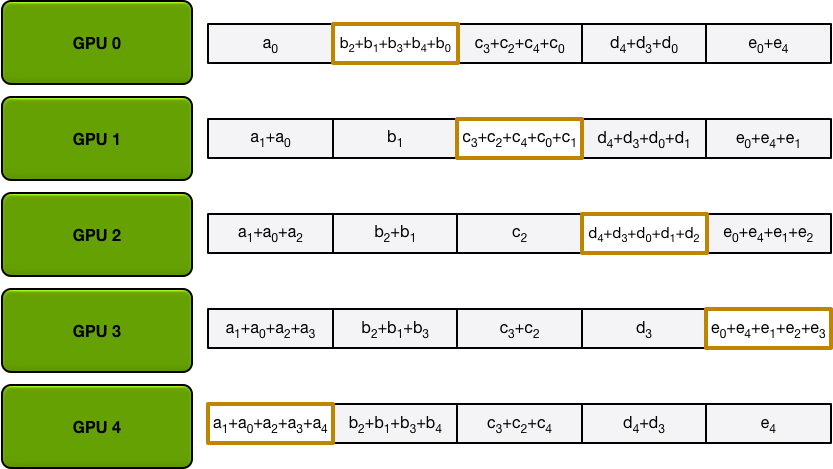
第二步做 all-gather,每张卡在每次iter都send和recieve一个求和过的完整数据块。
第一个iter:
第二个iter:
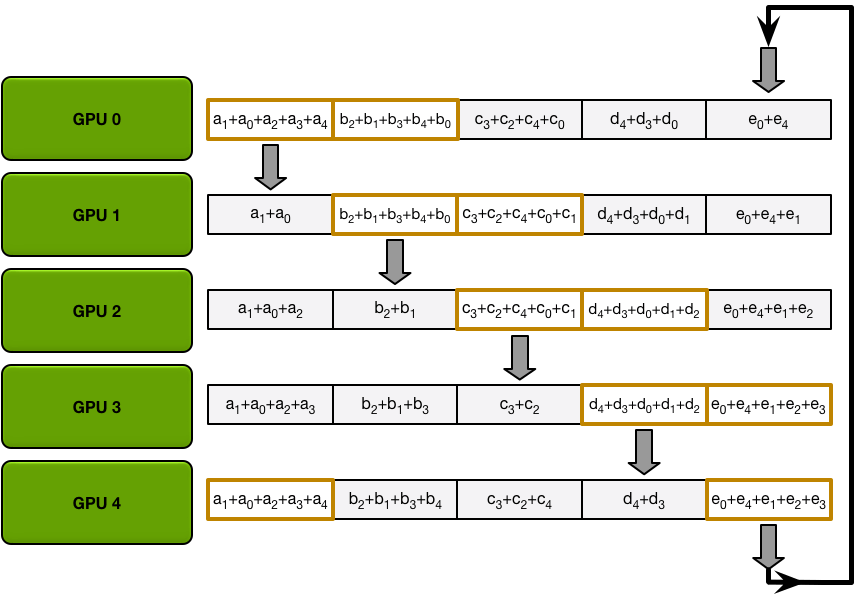
最后状态就是每张卡都有所有卡的数据总和:

那自注意力机制的序列并行也和ring all-reduce有着异曲同工之处,每张卡都只有子序列,而Q,K,V的计算有需要和所有序列进行交互。那么对应做法就是在每个iter的时候,传输各卡的一个子序列数据。
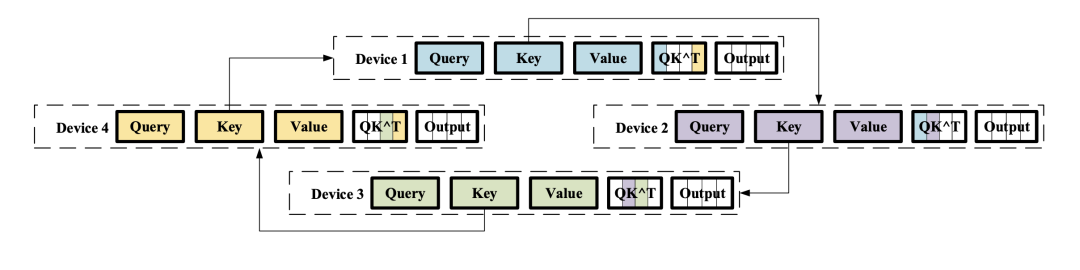 我们以计算Q, K为例,在第一个iter中:
我们以计算Q, K为例,在第一个iter中:
Device1接收了Device4上的Key,计算了Device1,Device4的Q1K Device2接收了Device1上的Key,计算了Device2,Device1的Q2K Device3接收了Device2上的Key,计算了Device3,Device2的Q3K Device4接收了Device3上的Key,计算了Device4,Device3的Q4K
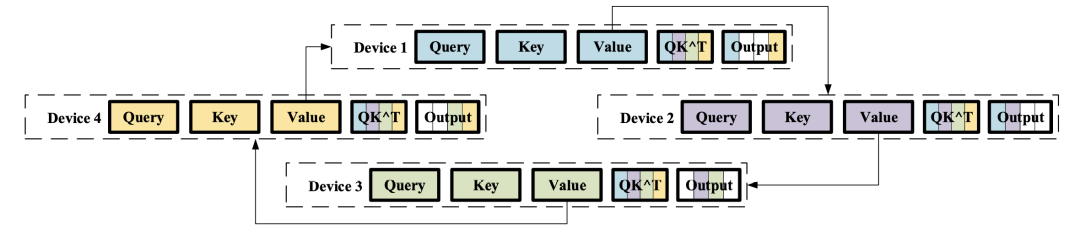
在加上后续2个iter,那么所有device都有完整的QK结果了。接下来计算Attention Scores也是类似的逻辑,每个卡都传输各自的value,得到最终的输出:
与前面类似,我们比较在模型并行下,计算自注意力所需的显存大小(这里就不再推导了):

通信开销方面,在模型并行下,前向后向各需要一次all-reduce;在序列并行下,前向需要两次 all-reduce(就是前面我们推导的Key,value传递的过程),后向需要四次 all-reduce。虽然在计算自注意力机制是多了一些all-reduce操作,但是在之前的MLP部分,序列并行比模型并行少了2次all-reduce,也算权衡了一些。
这里后向需要4次all-reduce笔者不是很理解,笔者觉得是反向计算 V的梯度,QK总梯度,Q的梯度,K的梯度所用到。笔者是系统小白,还望有人能指正解惑。
实验结果
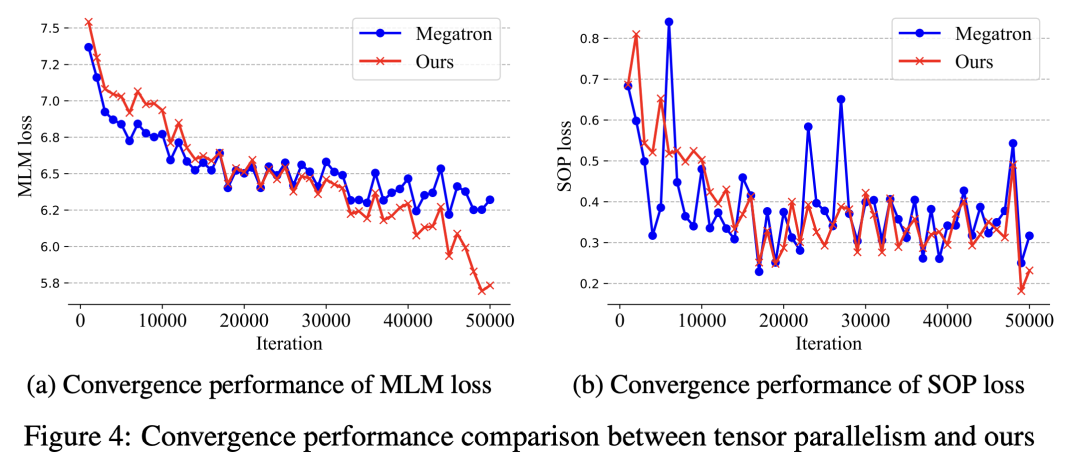
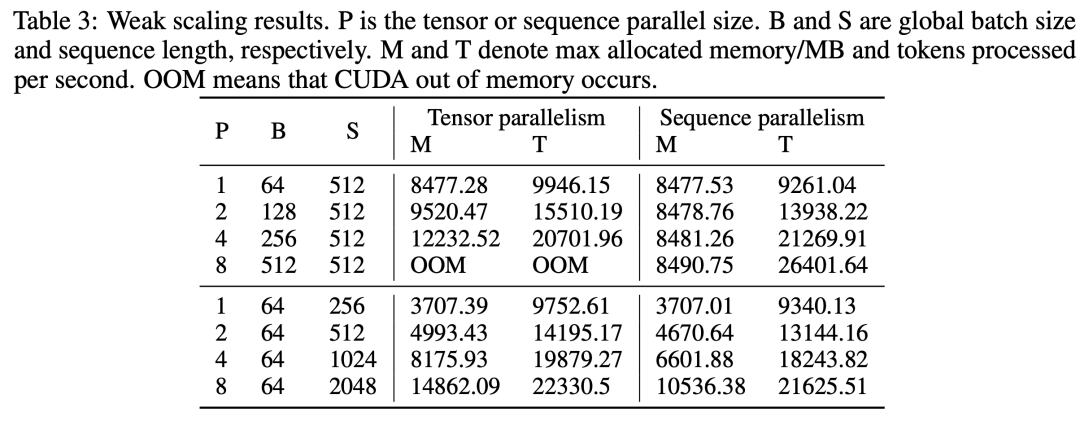
实验也是非常的amazing啊,收敛性正常,模型所能使用的最大batchsize和序列长度也比模型并行要大:
代码简单走读
这部分代码已经被集成在 ColossalAI 里,只依靠 PyTorch 自带的通信API实现。
代码地址:https://github.com/hpcaitech/ColossalAI
在 colossalai/nn/layer/parallel_sequence/layers.py 这里有对应的序列并行的API TransformerSelfAttentionRing。
而计算 QK 和 AttentionValue 的操作在 colossalai/nn/layer/parallel_sequence/_operation.py
因为是自定义通信实现前后向,所以这是一个 torch.autograd.Function
class RingQK(torch.autograd.Function):
@staticmethod
def forwardctx,
sub_q,
sub_k,
batch_size,
num_attention_heads,
sub_seq_length):
# 首先创建一个存放attention_score的空间
attention_score = torch.empty(
...
)
# 根据当前设备的QK,计算local QK结果
part_a = torch.matmul(sub_q, sub_k.transpose(2, 1))
local_rank = gpc.get_local_rank(ParallelMode.SEQUENCE)
local_world_size = gpc.get_world_size(ParallelMode.SEQUENCE)
start_idx = local_rank * sub_seq_length
end_idx = (local_rank + 1) * sub_seq_length
# 使用切片,将local QK结果存放到attention_score
attention_score[:, :, start_idx: end_idx] = part_a
for i in range(local_world_size - 1):
# 调用ring_forward函数,传输本卡上的Key
# 接收相邻卡的Key
sub_k = ring_forward(sub_k, ParallelMode.SEQUENCE)
start_idx, end_idx = _calc_incoming_device_range(i, local_rank, local_world_size, sub_seq_length)
# 使用当前的Q,和相邻卡的Key计算Attention score
part_a = torch.matmul(sub_q, sub_k.transpose(2, 1))
# 存放结果
attention_score[:, :, start_idx:end_idx] = part_a
# 如此循环至Q与各个device的Key都运算过,得到完整的Attention Scores.
return attention_score
而计算 attention_score 和 value 也是类似的,这里就不再展开
其中ring_forward 函数定义在 colossalai/communication/ring.py 里,主要逻辑:
# send to next rank
send_next_op = torch.distributed.P2POp(
torch.distributed.isend, tensor_send_next,
gpc.get_next_global_rank(parallel_mode))
ops.append(send_next_op)
# receive from prev rank
recv_prev_op = torch.distributed.P2POp(
torch.distributed.irecv, tensor_recv_prev,
gpc.get_prev_global_rank(parallel_mode))
ops.append(recv_prev_op)
通过调用PyTorch的通信API P2POp 来实现 send 和 recieve,添加至一个列表中。能够将一个tensor发送到下一个rank,并从上一个rank接收一个tensor。
总结
这个序列并行做法挺有意思的,针对 Transformer 这种计算自注意力模型的模型,结合ring all-reduce 思想,将训练更长序列的模型变为可能。相关实现都是基于PyTorch做的,不需要追到很复杂的代码里,推荐各位阅读~