
ICLR 2020满分论文慘遭两个1分拒绝!AI顶会评审机制再受质疑

新智元报道
来源:Reddit
编辑:肖琴
【新智元导读】一篇ICLR 2020的论文在拿到8个满分评价(8-8-8)后,领域主席再分配两位专业审稿人,竟然遭受双重拒绝:两位审稿人都给了1分!如此两极化的结果令不少人感到吃惊,AI顶会评审机制的缺陷再次受到质疑。你怎么看?现在戳右边链接上新智元小程序 分享观点即有机会赢取年度AI好书!
近日,Reddit一则帖子引起热议:
一篇ICLR 2020的论文在拿到完美的满分评价(8-8-8)后,额外的两位审稿人连续给了2个1分评价。你怎么看?

帖子中说的这篇“满分论文”题为Recurrent Hierarchical Topic-Guided Neural Language Models,论文提出一种新颖的更大上下文(larger-context)的语言模型来同时捕获语法和语义,并声称该模型能够生成高度可解释的句子和段落。
ICLR 2020采用Open Review 进行评审,每篇论文一般分配3名审稿人,分数区间为1-8分。不过实际上审稿人能给的分数只有4个档次:
1(reject),3(weak reject),6(weak accept),8(accept)
因此,这篇论文最终评分(8-8-8-1-1)的结果,令不少人感到吃惊和不解。
让我们先还原一下故事线:
10月26日至29日:评审结果公布,所有三位审稿人都给了8分,尽管审稿人提及了该论文缺少与预训练的Transformers模型进行比较;
10月31日:领域主席评论说,这篇论文缺少与“非RNN”语言模型进行比较;
10月31日:区域主席评论说,这篇论文没有与“非rnn”语言模型进行比较,即transformers模型;
11月底:领域主席为该论文分配了两名额外的审稿人,并直接告诉他们不要忘了审查一下transformers问题;
12月2日和3日:两位额外的审稿人由于论文缺少比较和相关文献,都给了低分。
↓↓猛戳下方小程序互动评论赢取年度AI好书↓↓
5位审稿人给出8-8-8-1-1的两极评分
首先,我们来看一下这篇论文的简要内容,以及5位审稿人的评审意见。

论文地址:https://openreview.net/forum?id=Byl1W1rtvH
标题:Recurrent Hierarchical Topic-Guided Neural Language Models
一句话总结:我们提出一种新颖的更大上下文(larger-context)的语言模型来同时捕获语法和语义,使它能够生成高度可解释的句子和段落
摘要:
为了从文本语料库中同时捕获语法和语义,我们提出了一个新的larger-context 语言模型,该模型通过动态的深度主题模型来提取递归的分层语义结构,以指导自然语言的生成。该模型超越了传统的忽略长程词依赖关系和句子顺序的语言模型,不仅捕捉了句子内的单词依赖,而且捕捉了句子间的时间转换和主题依赖。为了进行推理,我们将随机梯度MCMC和递归自编码变分贝叶斯相结合。在大量真实文本语料库上的实验结果表明,该模型不仅优于最先进的larger-context 语言模型,而且能够学习可解释的递归多层主题,生成语法正确、语义连贯的各种句子和段落。
关键词:贝叶斯深度学习,recurrent gamma belief net,更大上下文的语言模型,变分推理,句子生成,段落生成
评审4:
经验评估:我阅读过该领域的大量论文。
评分:1:拒绝
审稿人4对这篇论文给出了最低分“1”,他评价道:本文提出了一种将文档级主题模型信息集成到语言模型的技术,虽然其基本思想很有趣,但他认为最大的问题是论文一开始的误导性断言。在第一节的第二段,论文声称基于RNN的LMs经常在句子之间做出独立的假设,因此他们开发了一个主题建模方法来对文档级信息建模。他一一列举了论文中关于这一断言的存在的问题。
评审5:
经验评估:我在这个领域已经多年发表论文。
评分:1:拒绝
审稿人5认为这篇论文的模型描述很混乱,许多陈述没有适当或足够的理由。他仔细列举了论据,最后评论道,虽然论文有一些有趣的结果,并且与其他模型相比PPLx最低,但他不认为这篇论文可以接收。
评审1:
经验评估:我阅读过该领域的大量论文。
评分:8:接收
审稿人1对这篇论文给出了最高分:8分,评审意见总结道:这是一篇写得很好的论文,表达清晰,有一定的新意。该方法具有良好的数学表达和实验评估。结果看起来很有趣,特别是对于捕获长期依赖关系,如BLEU分数所示。一个建议是,与基线方法相比,作者没有对所提出方法的复杂性进行计算分析。
评审2:
经验评估:我阅读过该领域的大量论文。
评分:8:接收
审稿人2同样对这篇论文给了8分满分。尽管提出了几点改进的建议,但审稿人2总结说:我认为这是一篇写得清晰的论文,有很好的动机,模型也很有趣。有很好的结果,以及大量的后续分析。我认为这是可以接受发表的可靠文章。
评审3:
经验评估:我阅读过该领域的大量论文。
评分:8:接收
最后,审稿人3也对这篇论文赞誉有加,给出了8分。评审意见认为,虽然模型的新颖性有限,但所提出的模型的学习和推理是非凡的。此外,与SOTA方法相比,论文还展示了该方法在语言建模方面的性能改进,说明了该方法的重要性。
Reddit热议:双盲评审机制存在明显缺陷
从一举拿下3个8分,到连续2个1分遭遇滑铁卢,如此戏剧性的结果在Reddit论坛上引起了热议。网友的关注点主要在于:
①另外两名审稿人为什么这样做?
②AC(领域主席)的行为是否有误导性?
③作者对评审意见的回应是否可疑?
④这样的审稿机制存在明显缺陷
给两个1分,是真的不希望这篇论文被接收?
Reddit用户yusuf-bengio说:“到目前为止,审稿过程都是有效的。我唯一关心的是这两位额外的审稿人,他们是‘随机’分配的吗?”
他认为,接受一篇糟糕的论文比拒绝一篇好论文后果更严重。拒绝一篇好论文会伤害作者,但接受一篇糟糕的论文会伤害整个研究社区的诚信。
他不是特指这篇论文糟糕,但从结果来看,(8,8,8,1,1)的评分是荒谬的。科学,特别是机器学习的研究是建立在同行评审过程的信任基础上的。当我们看到一篇被ICLR/ICML/NeurIPS接受的论文时,我们通常相信审稿人对该论文的评价是正确的。
正确(包括论文没有忘记引用相关工作)
对研究界来说意义重大
当我们开始接受“糟糕”的论文时,就破坏了这些会议的可信度。
有人认为:“这两位审稿人可能是想让这个分数得到高级AC的注意,他们真的认为这篇论文不应该被接受。”
有人怀疑地说:“事情发展的时间线、还有两名额外的审稿人都太奇怪了…这篇论文可能真的很差……但在最后一刻增加审稿人似乎动机不纯。openreview里面很多论文的评审意见都很糟糕(评分也很低),但是AC几乎从来不会为那些论文增加审稿人,而这里的情况,AC一致决定分配两个额外的审稿人……”
也有读者对两名额外审稿人的做法表示赞同,用户akarazniewicz说:我只是简要阅读了这篇论文。在我看来,从审稿质量来看,新的两位审稿人实际上花了更多时间,分析并试图理解论文。这些评论没有任何问题,实际上可以帮助作者进行下一步的工作。
AC的态度扼杀了创新和进步?
从AC的角度来看,指派额外的审稿人(不管是不是随机指定)肯定比简单地否决原来评审的几个8分更好。后者可能会引起更多的质疑。
本例中,AC对论文评论道:
这篇论文看起来很有趣,但是最近在语言建模和生成方面的SOTA成果主要基于Transformer的模型。然而,该论文很明显缺失了任何与这些模型的比较,甚至都没有提及。我想知道:作者是否与任何模型比较过?我怀疑这些模型在某种程度上已经能够捕获主题,并且可能排除了对该论文中提出的方法的需要(但如果证明这是错误的我会很高兴)。
Reddit用户fmai认为,不管这篇论文是好是坏,AC都对任何没有在当前SOTA的方法之上进行改进的方法不感兴趣,即使所提出的方法可能很创新,并在很大程度上改进了baseline模型。
这种态度扼杀了创新和进步。因为如果没有那些不遵循当时看起来最有前途的研究方向的人,ML就不会发展到现在的程度。
最后,当主席要求新审稿人注意某些方面时,还会出现其他偏见,并暗示他们应相应地降低分数。“没有偏见”是不可能的标准,但这并不能成为一切偏见的借口。
也有人对作者在评论区对领域主席的回应感到可疑,coolontheintenet说:
作者在评论区对领域主席的反应极为可疑。当AC问他们:你的论文看起来很有趣,但是你能把它和Transformer比较一下吗,因为这个是SOTA?他们用各种(相当没有说服力的)理由回答说,他们认为没有必要进行比较。AC再次回复说:很好,但我还是希望看看比较。然后他们回复说他们已经削弱了他们在论文中的主张,现在他们只声称模型的表现优于SOTA RNNs,这基本上意味着他们承认他们的方法并不比Transformer更好了。因此,作者似乎试图掩盖Transformer存在的事实,这是荒谬的。我完全可以理解领域主席要求更多审稿人。
Reddit用户Lightning1798表示:
这反映了当今机器学习中一个普遍存在的问题。评审是如此混乱,许多提交到顶级会议的论文有巨大的差异。事实上,一篇论文同时得到完美评价和最低分数都是很普遍的。我不知道确切原因,但我认为这与该领域的快速发展有关:一篇论文为投稿到下一个大型会议被上传到arxiv后,立刻就有很多跟踪该研究的论文出现。再加上这个领域的大量研究,每年会议的压力/截止日期(而不是每月或每周的科学期刊),就会发生这样的事情。
blueyesense认为:
这是我们的审稿系统存在的典型缺陷。
很有可能给一篇论文被分配3个不相关的审稿人,然后得到高分,或者正好相反(不理解论文的白痴审稿人会给很低分数——有很多高被引、但被拒绝的论文)。也很有可能指派专家评审员(比如这次事件)……
未来将是公开、开放的审稿,就像那些被拒绝的论文的被引次数远远超过被接受的论文。
ICLR2020 双盲审稿资质雪崩,47%审稿人在领域内没发过论文
这不是ICLR 2020第一次受到质疑了。由于投稿量大幅增加,ICLR 2020的审稿质量被指责“惨不忍睹”,审稿人资质雪崩,让人怀疑这个被誉为深度学习顶会 “无冕之王” 的会议是否能真正评出最优秀的论文。ICLR 2020共收到近2600篇投稿,相比ICLR 2019的1580篇论文投稿,今年增幅约为62.5%,竞争尤其激烈。
上个月,南京大学人工智能学院院长周志华教授透露一条来自业内的信息:
ICLR 2020竟然有47%的审稿人从来没有在本领域发表过论文。。。投稿量远远大于合格审稿人群所能(超负荷)承受的程度,会使得顶会逐个垮塌。。。
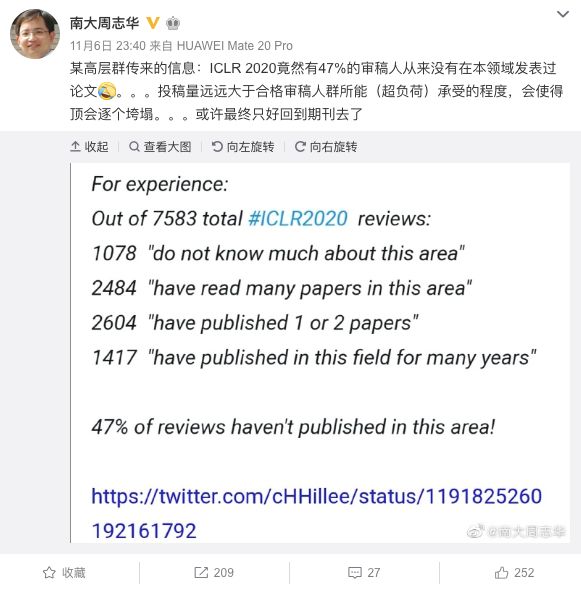
在7583位ICLR 2020审稿人中,1078人“不了解该领域”;2484人“读过该领域的很多论文”;2604人“发表过1-2篇论文”;1417人“在该领域发表论文很多年”。这样计算,47%的审稿人从来没有在该领域发表过论文!
周志华表示,open review仅当参与者都是相当level的专家才有效,否则更容易被误导。学术判断不能“讲平等”,一般从业者与高水平专家的见识和判断力不可同日而语,顶会能“顶”正是因为有高水平专家把关,但现在已不可能了。
加州大学伯克利分校教授马毅、清华大学副教授刘知远等都转发了这条微博,并发表了自己的看法。

这则消息立即引发了网友的热烈讨论,内容直指当前同行评议体系的缺陷。一方面,AI顶会文章投稿数量逐年激增,审稿人数量有限,质量下降在所难免。但更多的是审稿机制本身的缺陷,如审稿人权限过大,缺乏监督、很容易谎报资历,严重影响文章质量。
即日起,在新智元微信公众号当日头条、二条小程序内参与评论,我们将选取最佳评论送出精美礼品,本期礼物是【新智元&华章】AI好书,快来参与互动赢奖品吧:
↓↓猛戳下方小程序互动评论赢取年度AI好书↓↓
在新智元你可以获得:
- 与国内外一线大咖、行业翘楚面对面交流的机会
- 掌握深耕人工智能领域,成为行业专家
- 远高于同行业的底薪
- 五险一金+月度奖金+项目奖励+年底双薪
- 舒适的办公环境(北京融科资讯中心B座)
- 一日三餐、水果零食
新智元邀你2020勇闯AI之巅,岗位信息详见海报:
