
揭秘阿里、华为、字节跳动等大厂技术实践案例,学习超强避坑指南!
前端宇宙
共 1754字,需浏览 4分钟
· 2020-09-20
之前我们开口闭口谈云计算,后来又是人工智能,再后来又是区块链、中台,宏观层面看,技术浪潮一个接一个。从微观层面看,你也发现总有新技术会不断冒出来,比如,最近我看到的,Clickhouse、Apache Hudi、Flutter、TensorFlow Lite,这都是我们圈子里正在发生的小趋势,IT圈可以说是日新月异。
不知道你们的企业环境咋样,我了解到的许多公司业务需求变化都很快,甚至在发生颠覆式的调整,很多研发团队都在经历技术栈改造的挑战。越到这个时候就越需要学习和借鉴其他企业的成功经验,减少试错成本。

了解前沿技术趋势:学习移动、前端、架构、大数据、AI等12大领域的创新技术,在阿里、华为、腾讯、字节跳动等大厂是如何落地的
解决技术选型难点:借鉴丰富经验,提前预知技术风险,促进正确选型
提升团队研发效率:开拓团队思路,加速技术创新,让研发工作更高效
团队免费试学
QCon+ 案例研习社现面向所有研发团队免费开放,团队全员均可免费试学14天,和行业专家近距离交流切磋,快速掌握前沿技术应用现状,助力团队高效进阶。
为什么选择QCon+ 案例研习社?
为什么选择QCon+ 案例研习社?
1严格执行InfoQ技术大会质量标准
InfoQ技术大会已经举办11年,作为面向未来的线上交付方式QCon+ 案例研习社,无论是在讲师阵容、案例分享实用性以及用户体验上都严格执行InfoQ技术大会质量标准。

2 案例领域覆盖全面,可参考能落地
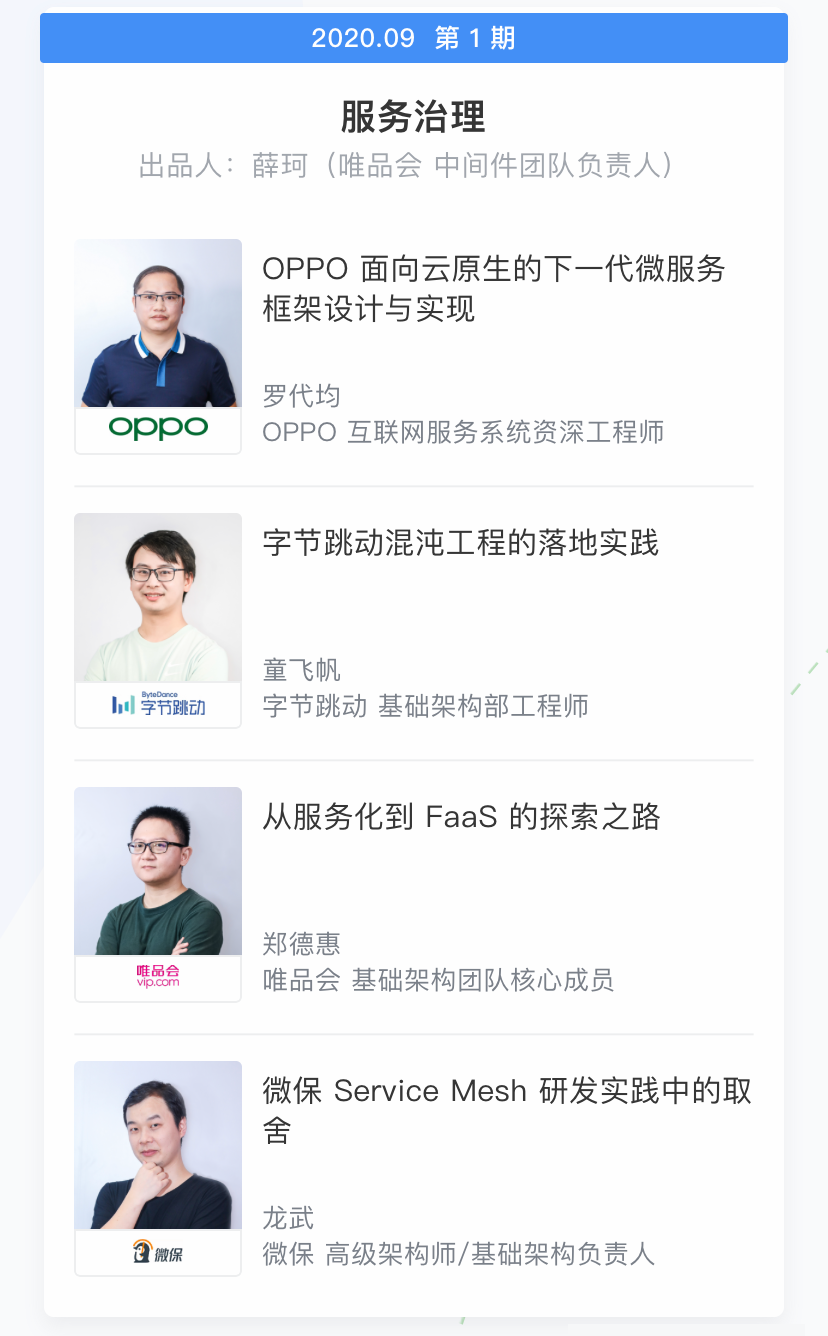

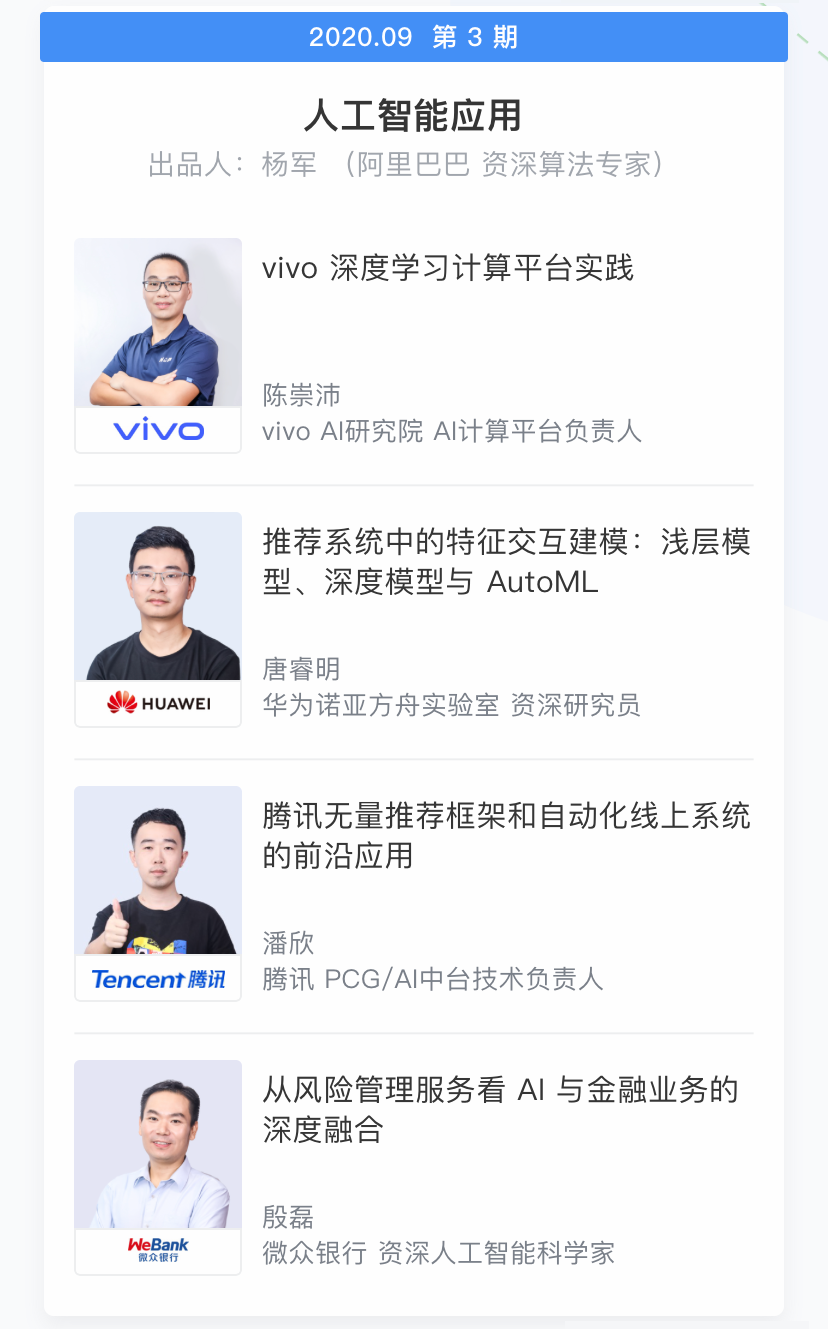

3 交互式学习,全年高效学习不间断


评论
我看阿里的年终奖总算发了!
到4月底了,这两天看朋友圈,发现阿里的年终奖终于发了,问了问老同学,也从网上检索了不少信息,基本搞清楚了阿里今年的年终奖情况。近来来阿里一些集团对绩效等级做了较大的调整,以前的旧绩效系统中,绩效分为3.25、3.5、3.75、4和5五个等级,其中4和5是较高绩效等级,较少见。而且之前3.5绩效内部划
公子龙
0
科普:深度学习训练,不同预算GPU选购指南
以下文章来源于微信公众号:DeepHub IMBA作者:Mike Clayton本文仅用于学术分享,如有侵权,请联系后台作删文处理导读购买显卡第一个要考虑的问题是什么?当然是预算。本文提供了不同预算的显卡选购指南,希望能对各位读者有所帮助。在进行机器学习项目时,特别是在处理深度学习和神经网络时,最好
机器学习初学者
0
【深度学习】人人都能看懂的LSTM
熟悉深度学习的朋友知道,LSTM是一种RNN模型,可以方便地处理时间序列数据,在NLP等领域有广泛应用。在看了台大李宏毅教授的深度学习视频后,特别是介绍的第一部分RNN以及LSTM,整个人醍醐灌顶。本文就是对视频的记录加上了一些个人的思考。0. 从RNN说起循环神经网络(Recurrent Neur
机器学习初学者
0
多人同时导出 Excel 干崩服务器!新来的阿里大佬给出的解决方案太优雅了!
点击关注公众号,Java 干货及时推送↓推荐阅读:面试辅导,我们出大成果了!来源:juejin.cn/post/7259249904777838629前言 业务诉求:考虑到数据库数据日渐增多,导出会有全量数据的导出,多人同时导出可以会对服务性能造成影响,导出涉及到mysql查询的io操作,
Java技术栈
1
大厂都在用的 Git 代码管理规范 !
👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目 2.0 版本完结啦, 演示链接:http://116.62.199.48/ ,新项目正在酝酿中
小哈学Java
2
学习开放日:开放复杂科学、AI+X 海量学习资源!
Datawhale干货 学习开放日:4月27-28日1. 什么是学习开放日?以AI为代表的技术突飞猛进,人类知识森林快速扩张,仅凭一人之力不仅难以覆盖,更是难以串联知识线索。唯有像蚂蚁探索最优路径一样,我们才能在信息爆炸的知识森林中探索出更好的方向!因此,今年集智斑图联合国内最
Datawhale
1
springboot第70集:字节跳动后端三面经,一文让你走出微服务迷雾架构周刊
创建一个使用Kubernetes (K8s) 和 Jenkins 来自动化 GitLab 前端项目打包的CI/CD流水线,需要配置多个组件。下面,我将概述一个基本的设置步骤和示例脚本,以帮助你理解如何使用这些工具整合一个自动化流程。前提条件确保你已经有:Kubernetes 集群:用于部署 Jenk
程序源代码
0
超大规模数据中心网络架构及其技术演变
本文所讲的数据中心网络架构和技术范围是针对典型的大型互联网和云计算公司的超大规模数据中心(Hyperscale Data Center),不一定适合其他类型的数据中心网络。业界对于什么规模才算是“超大规模(Hyperscale”并没有一个精确的定义。一般来说,一个数据中心网络集群至少有 5000台服
数据中心运维管理
0