
卧槽!因果分析来了!
你们好,我是宝器!
本文的分享主题为观测数据因果推断,希望通过本文可以让大家对观测数据因果推断有一个整体的了解,明晰当前观测数据因果推断的困境和主要处理方法,以及在特定问题中的一套通用解法。
具体将围绕以下3部分展开:
观测数据因果推断基本知识
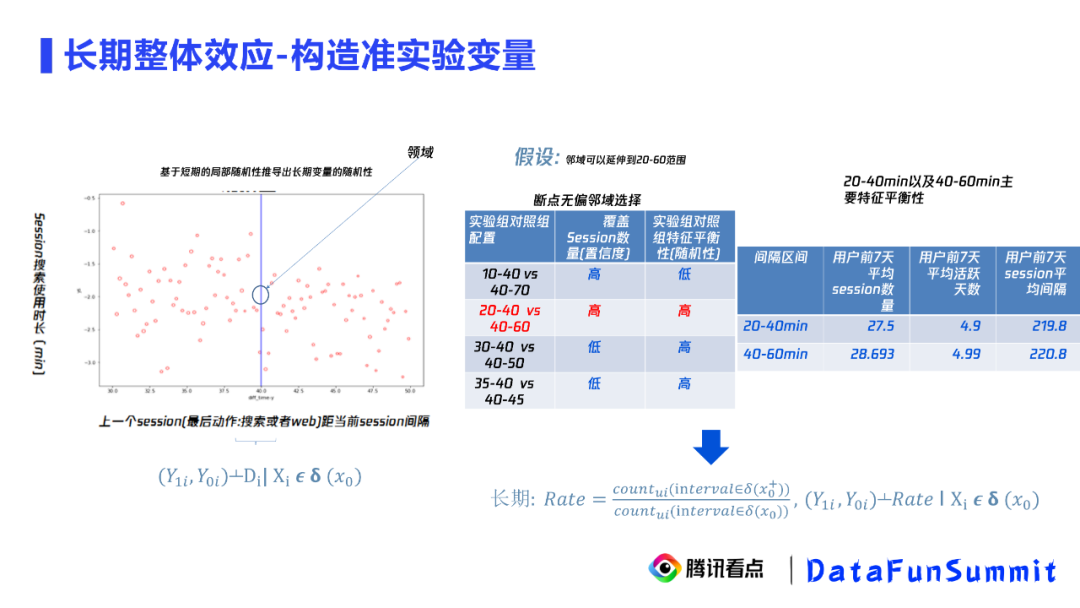
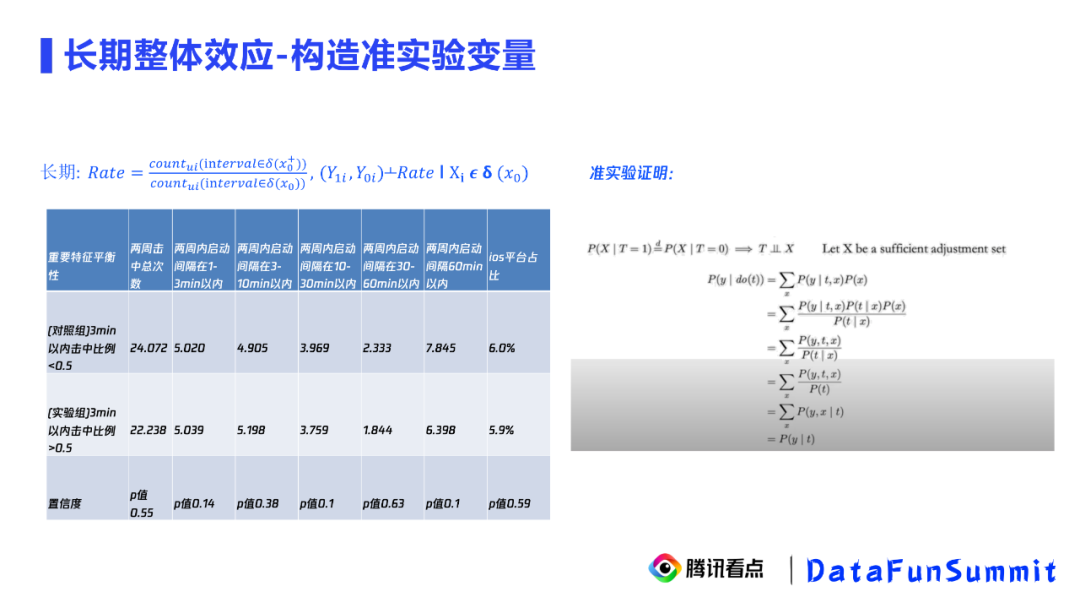
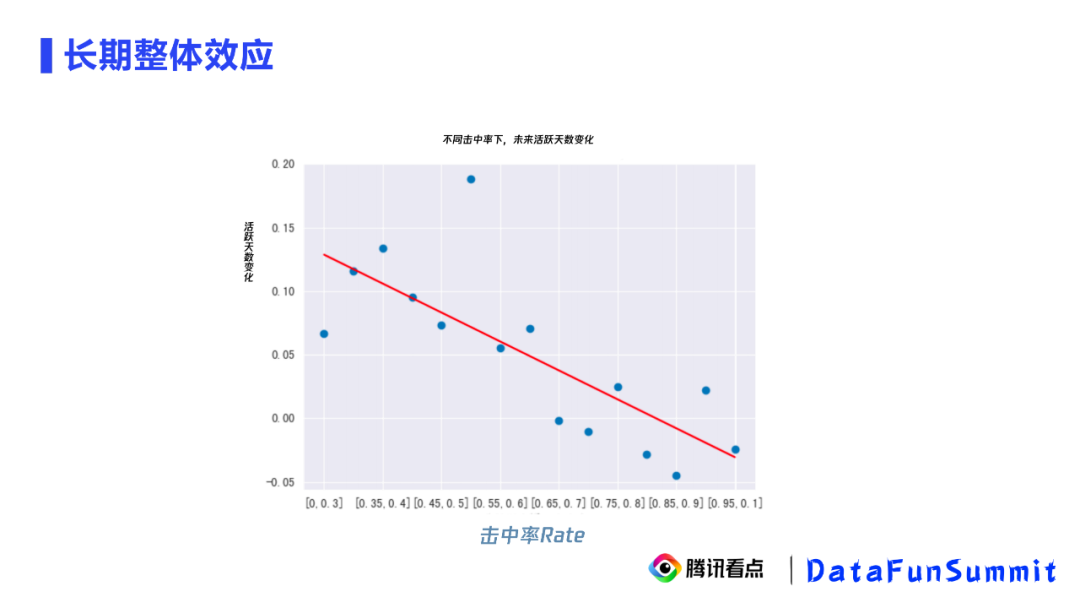
准实验方法在腾讯看点的应用案例
启动重置类问题通用分析方法
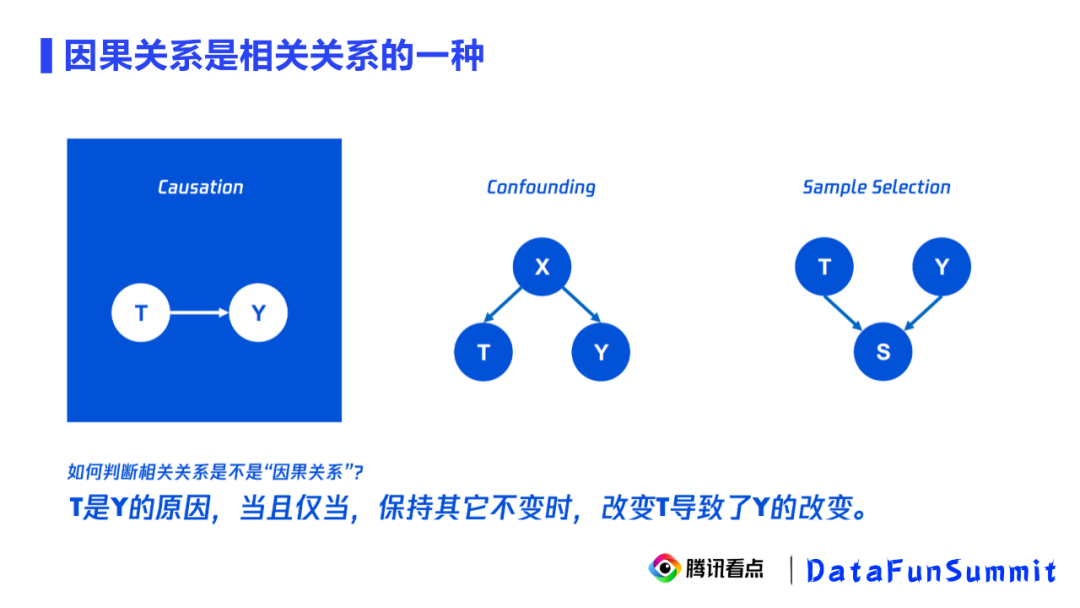
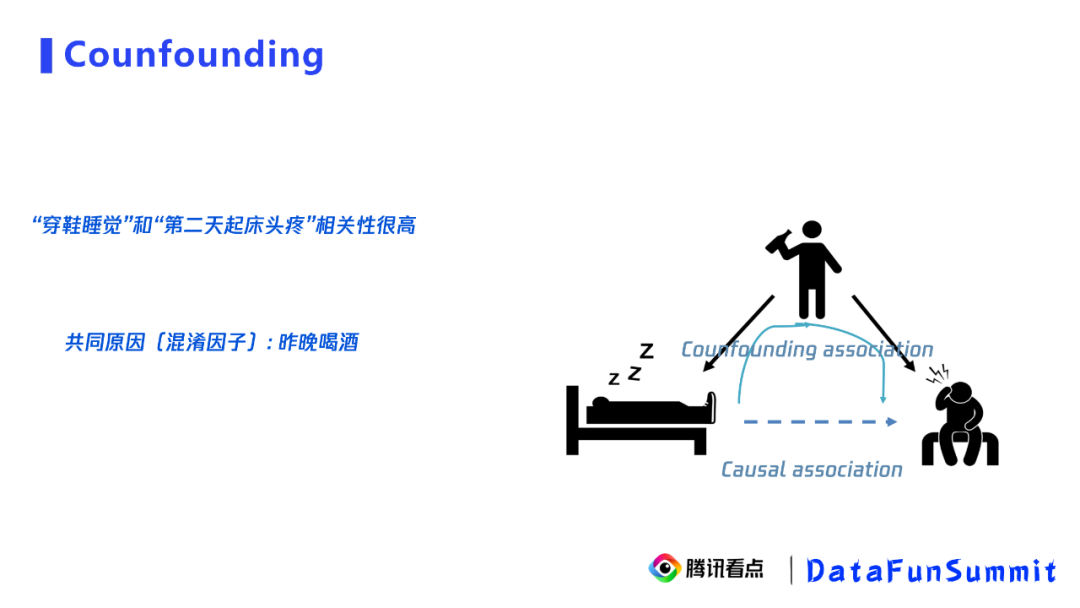
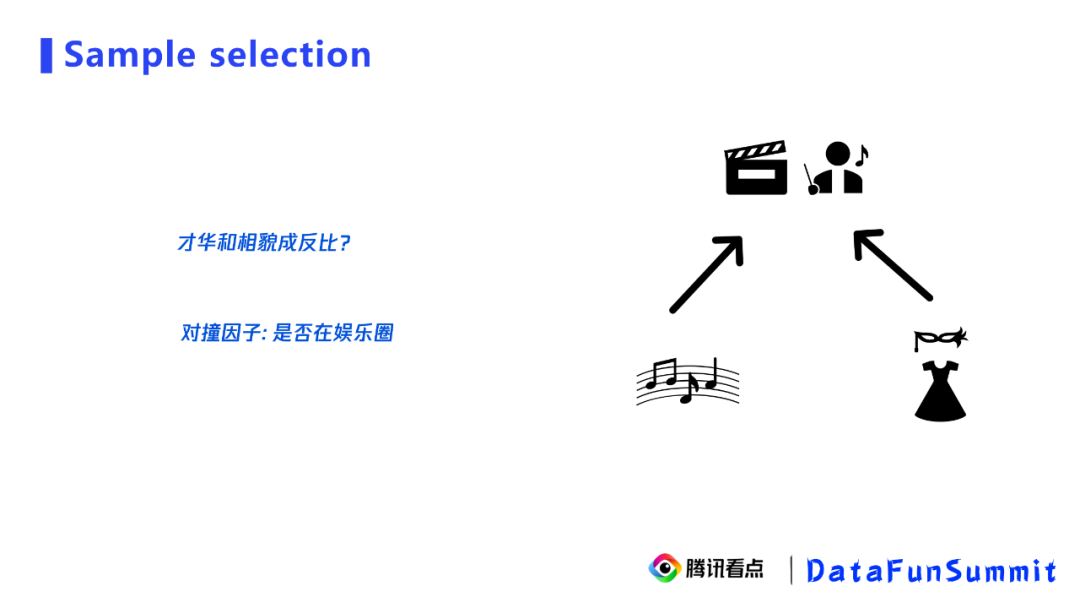
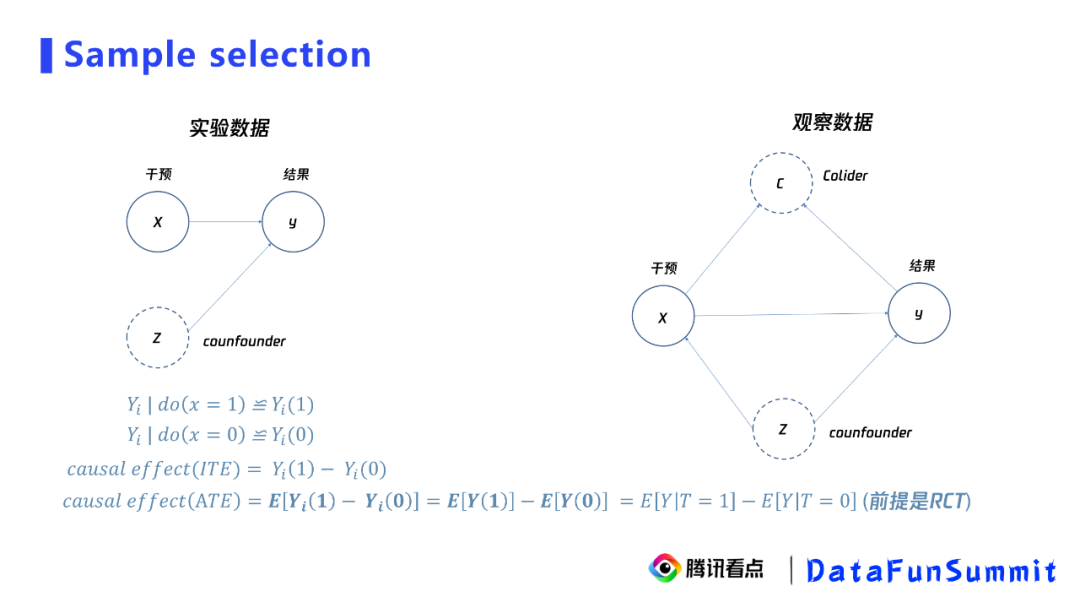
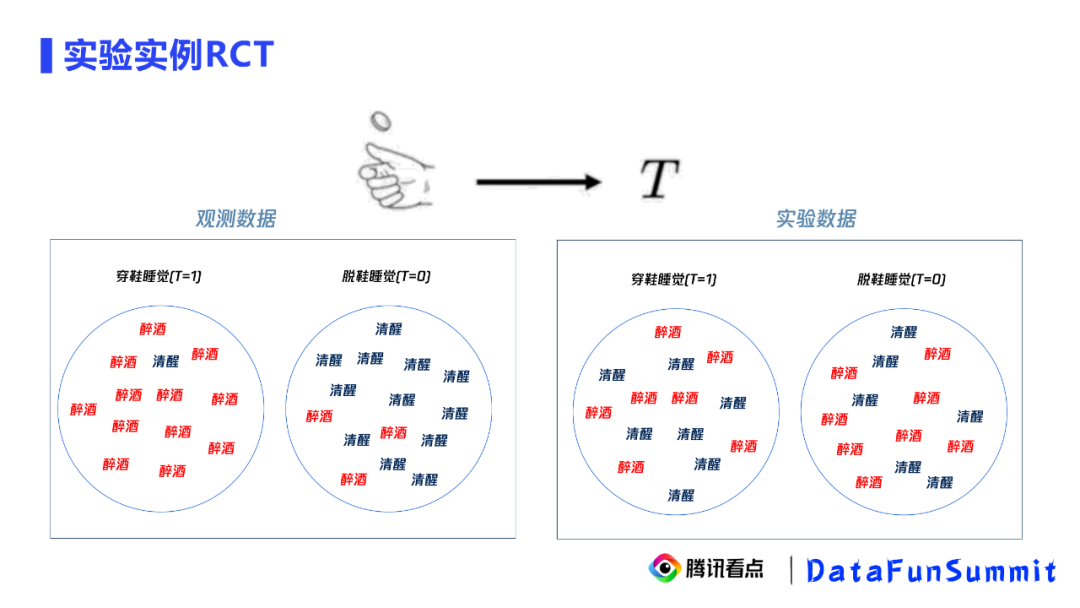


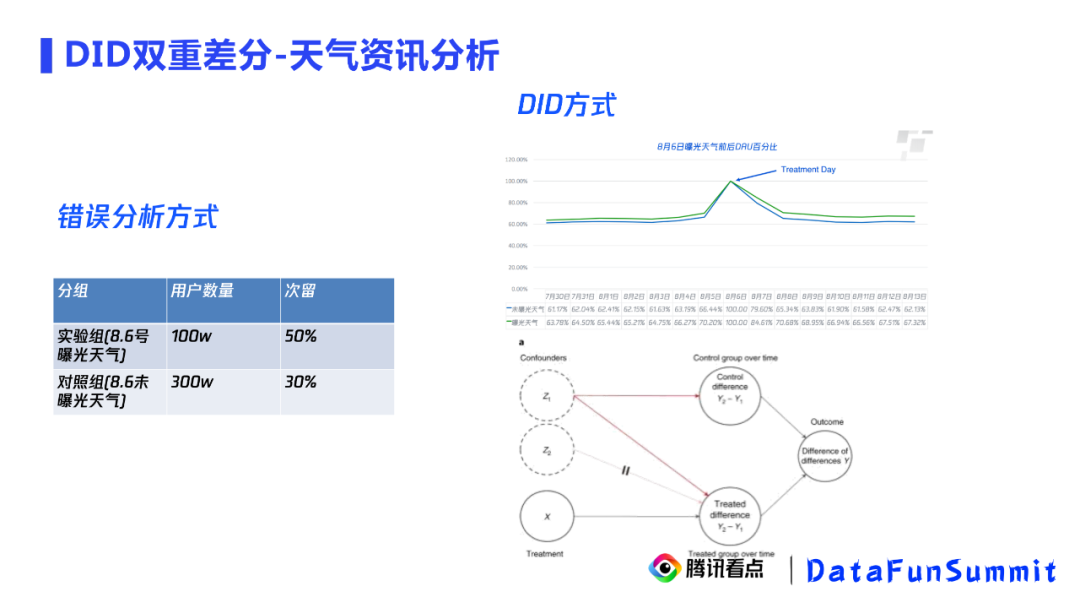
实验组:8月6号曝光天气的用户
对照组:8月6号未曝光天气的用户
实验组:前期未曝光天气,8月6号曝光天气的用户作为实验组
对照组:前期未曝光天气,8月6号未曝光天气的用户作为对照组

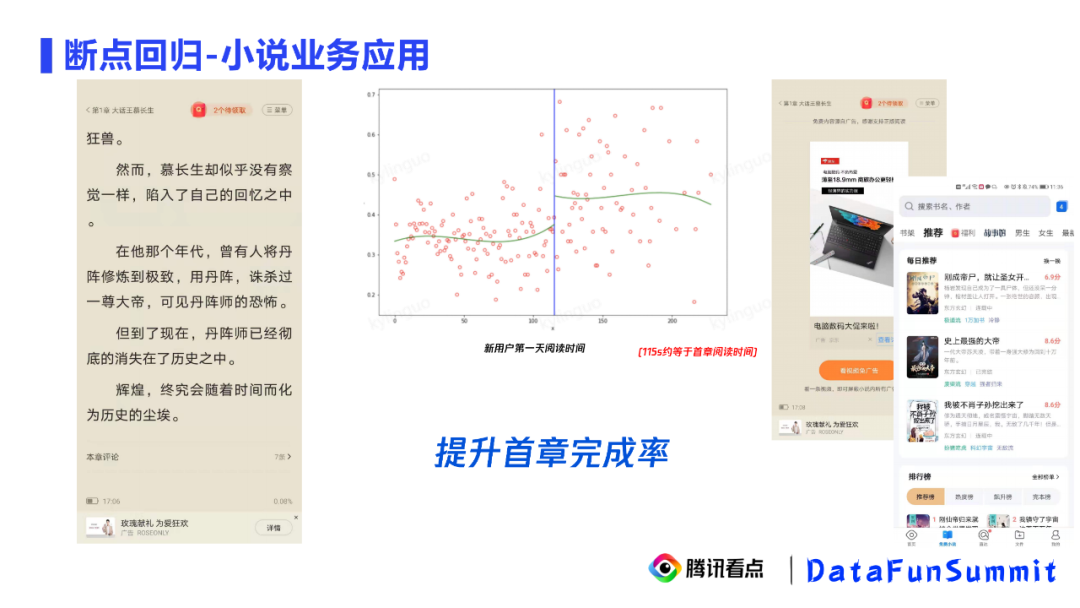
在首页推荐时,以小说易读率作为一个指标,不优先考虑进入节奏比较慢的小说
取消首章阅读的广告,来提升首章完成率,从而提升用户的次留

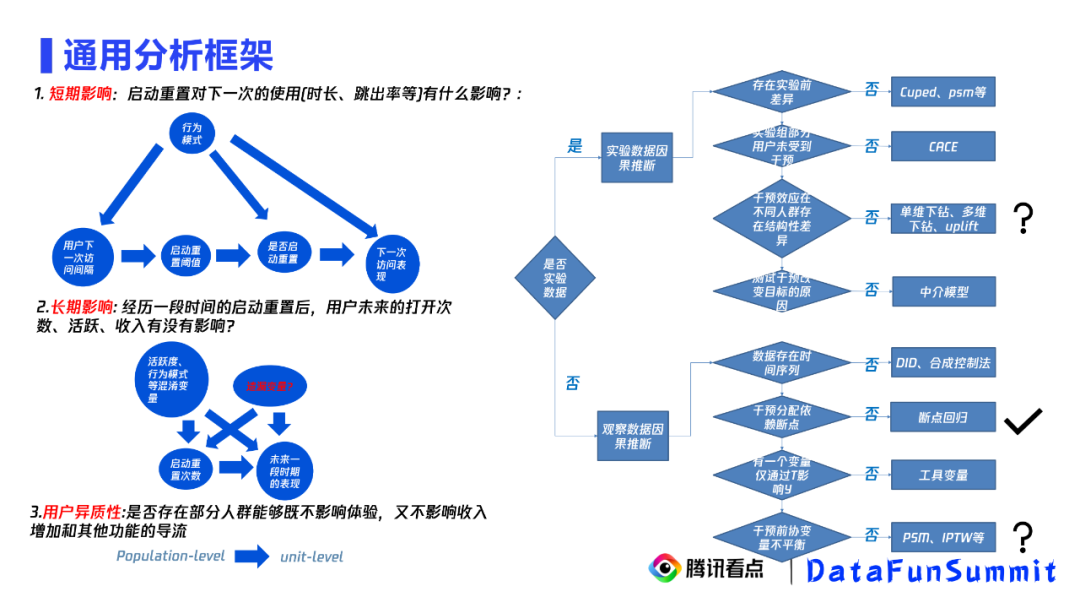
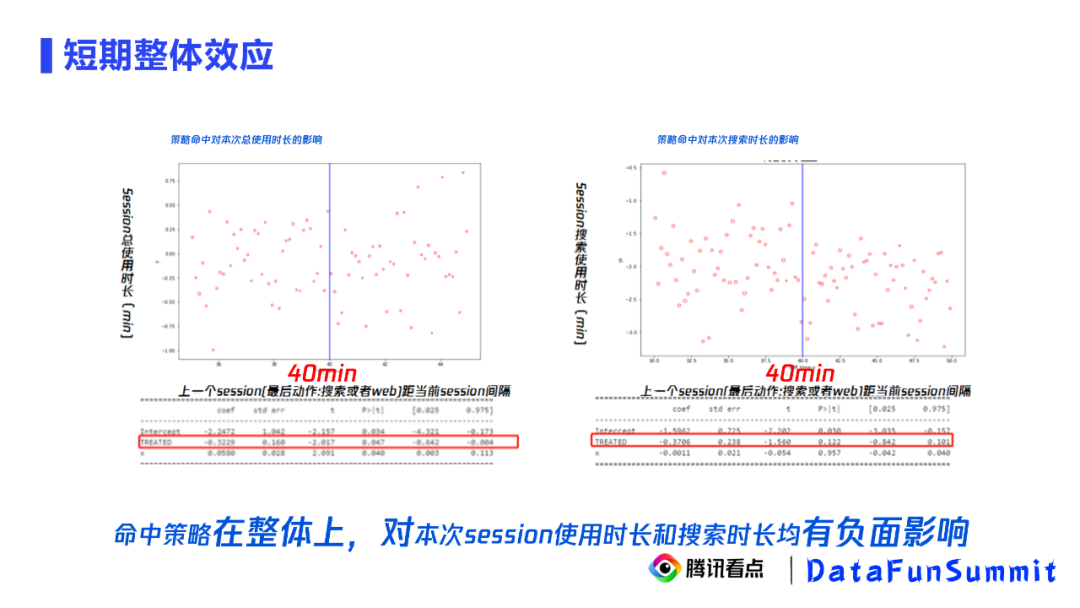
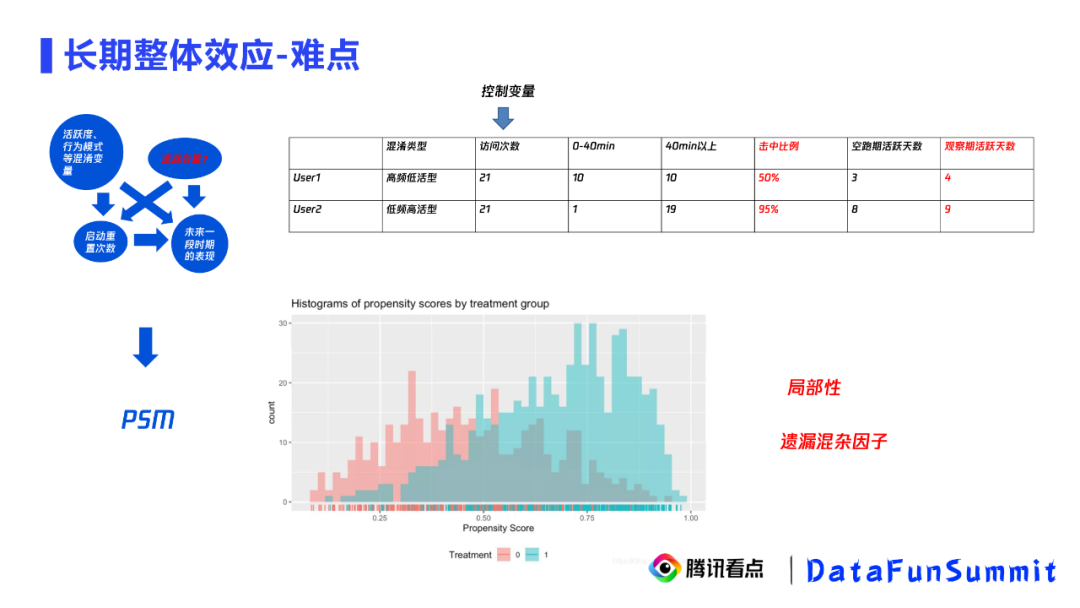
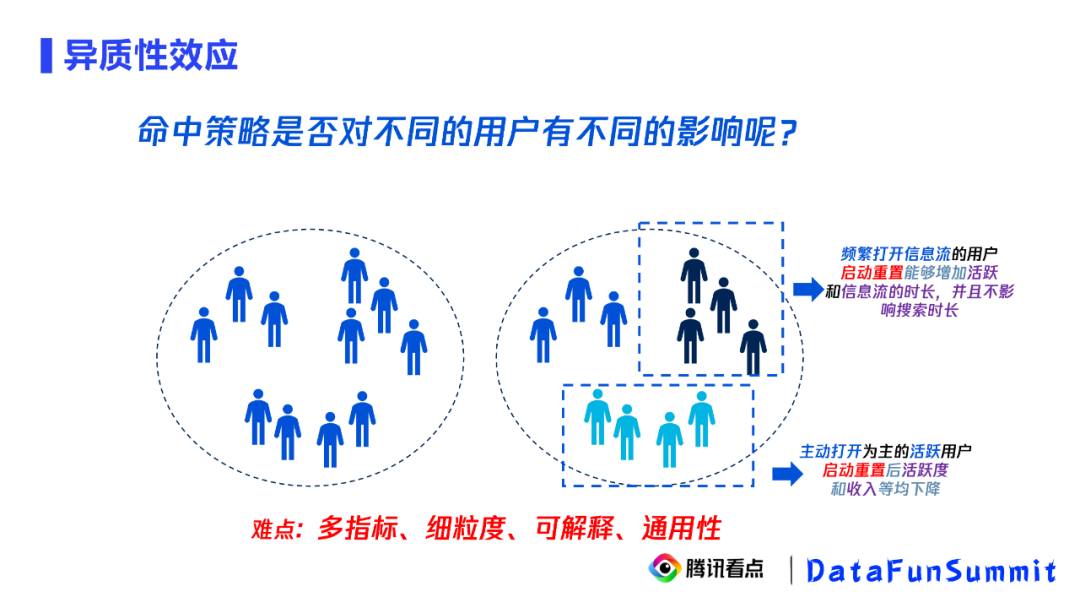
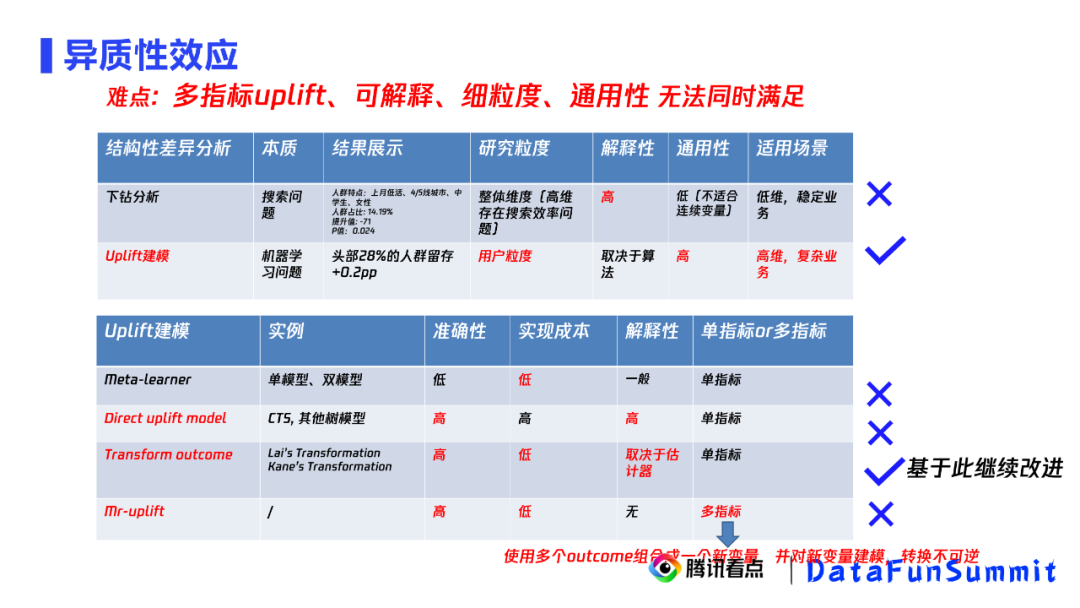
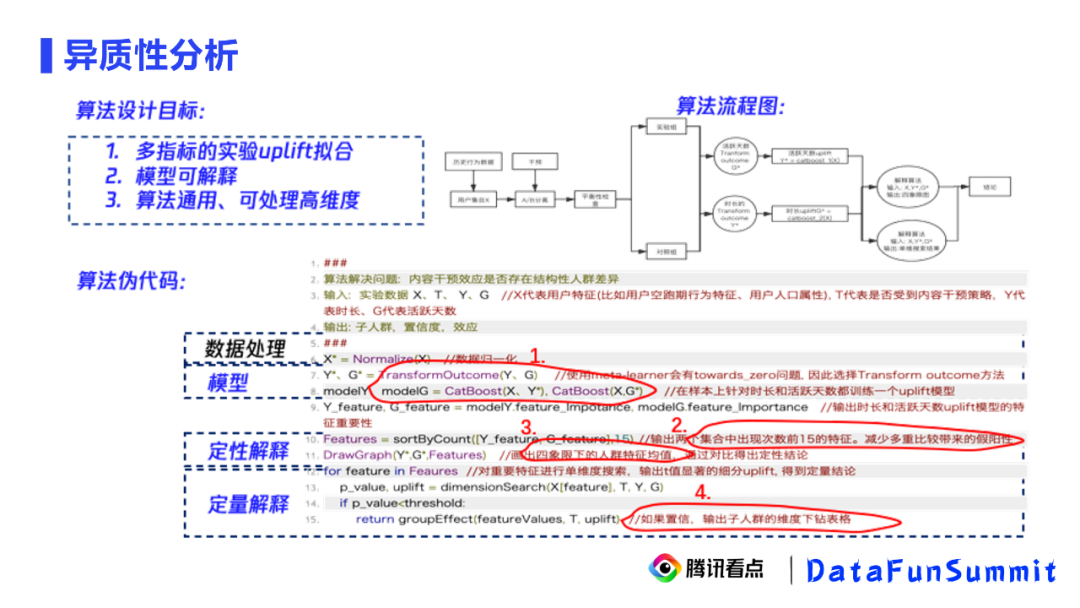
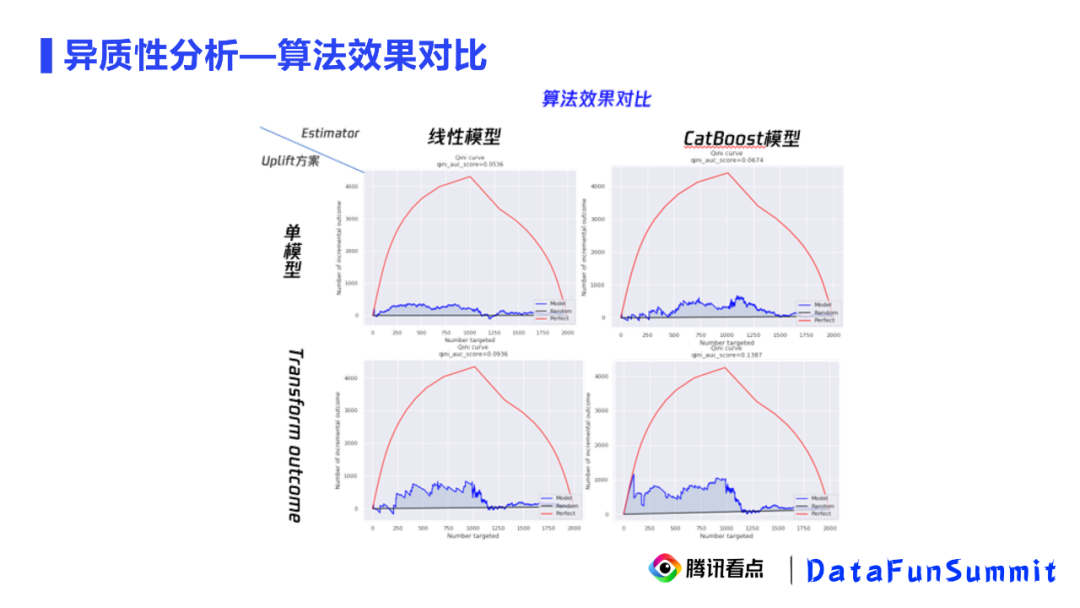
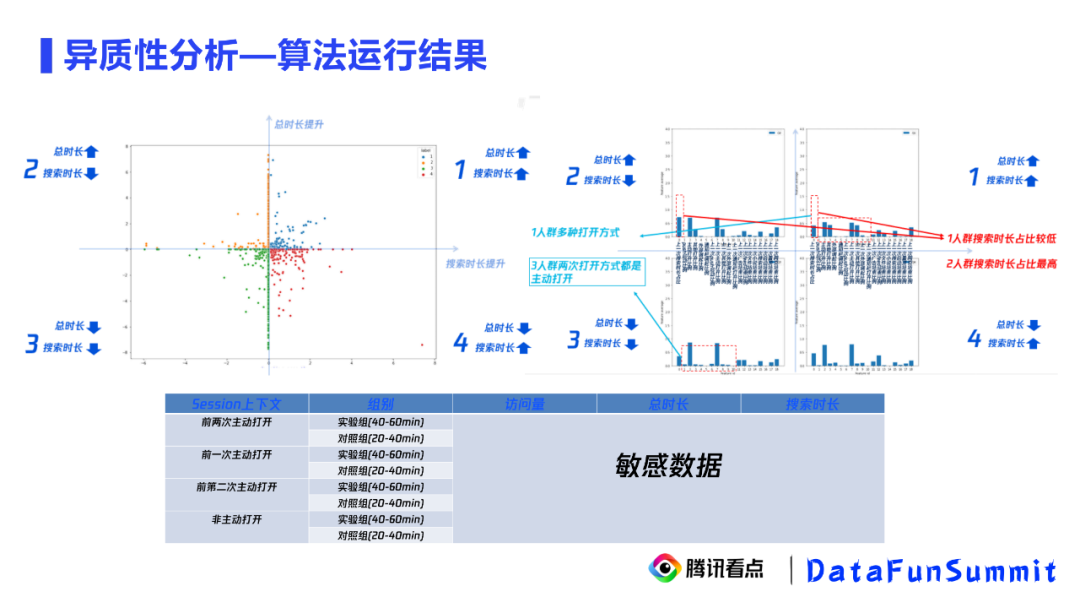
多指标的实验uplift拟合
模型可解释
算法通用、可处理高维度


推荐阅读
欢迎长按扫码关注「数据管道」
评论