
真实的算法工作总结!
导读
今天不谈学术,来和大家谈谈做算法工程师的那些年~本文作者结合自身经验,分享在项目和业务中的解决问题的思路和方法,也欢迎大家一起参与讨论!
前言
工作刚好三年了,抽空复盘一下这些年做的一些工作经验,不谈算法细节,毕竟我只会炼丹(手动狗头),讲一讲自己的解决问题的一种思路,欢迎大家沟通交流。
项目思路
不管是什么项目,分类,分割,检测或者生成都好,业务的需求总是第一位的,场景的适配第二位,模型的选取以及算法调优最后。业务->场景->模型->调优
举个栗子
如果是做OCR的识别,大部分工业应用的场景都是文档图片或者广告图片的文本识别,这些文本有个特点就是横平竖直(当然由于拍摄会导致扭曲),最常用的就是各种卡证的识别,身份证,银行卡诸如此类,这一类具有非常规则的版面,所以不需要太复杂的版面分析以信息抽取的算法就可以拿到想要的关键字段。
那么算法选型上,对于检测来说,EAST完全可以cover这个场景了,更甚的来说,我可以设置先验框,都不需要检测模型;刚也说到了,卡片类的文本都是横屏竖直的,其实用CRNN已经可以很好的做到识别了。
目前很多的paper都是再做spotter或者复杂场景下的扭曲文本识别,这些文章的方法都很新颖指标上也非常的solid。spotter实际业务不会怎么使用的,因为实际的业务来说,更希望各个模块可以解耦,这样会给开发者更多的callback反馈以及应对业务需求的变更。
扭曲文本的识别实际上应用的场景也比较少,刚也提到了大部分的识别还是横平竖直的,虽然会有部分的倾斜或者形变,不过通过前置算法的处理以及合生数据的方法都能很好的解决问题。
算法能够提升可能只有1-2%点,但是你数据做的很差,那么就会差距几十个点,对于OCR场景来说如何做好数据至关重要,因为真实的数据标注是非常困难的,成本也很高。
大概的一个流程如下, 哪个模块有问题就去针对性优化。定位模块->文本检测->文本矫正->文本识别->版面分析->关键字提取
再举个栗子
做实际业务的分类,会遇到很多的问题,数据不均衡,数据长尾,极端情况下,部分类别只有个位数的数据。一般来说,大类的数据对于整体业务的提升会更明显,所以高优的类别非常重要,不管是召回还是精度都要高。小类可能受众群体小,但是价值高,所以也需要重视。至于怎么定位是否高优,这个还是要看业务需求来的。

通用流程如下, 最重要的不是模型和算法而是针对场景的数据分析,要不断的重复这个流程。数据预处理->数据重|欠采样->模型选取->调优增强->损失调优->数据分析
可以通过评估混淆矩阵,看哪几个类别没有分开,分析为什么没有分开,这里就要考虑几点了,是因为数据标注的问题?还是因为数据本身相似度太高?还是因为数据偏向理解性质,只有label无法很好的学习到特征?
分析好以后,可以尝试通过聚类,伪标签,多标签,多模态等方案去解决这些问题。
至于算法层面来说,大部分的trick都是通用性质的,简单说来就是会让好的类变的更好,差的类还是没有效果。不能从根本上解决这个问题,我常说的一句话就是数据是下限,算法尽量提升下限接近模型的上限。
当然不同的模型会带来不同的收益,我们不需要考虑模型的结构也不需要考虑各种五花八门的attention,只需要考虑模型容量即可,只要容量足够,能够获取的信息就更加丰富,不用关心是否冗余,因为你的训练数据都是足够多的。
只要条件允许,能上大模型自然就是上大模型,条件不允许也可以通过大模型->伪标签|蒸馏->小模型的方法。当然了,这个也要看训练的时间和成本,无脑上大模型都是在成本预算足够多的情况下,比如V100 32G 训练imagenet-R50,90个epoch,只需要7个小时左右,但是跑Swin-tiny,ConveXt-tiny需要用到2-3天的时间。对于我来说,认为这个就是负向收益,虽然他们最终会高2-3个点的精度,但是这几个点可以通过其他的方法补齐。
当然,真实场景下的业务数据是具备一定的时延性的,如果是长期维护的模型,一定是要不断进行数据迭代和清洗的,方法的话可以理解为主动学习
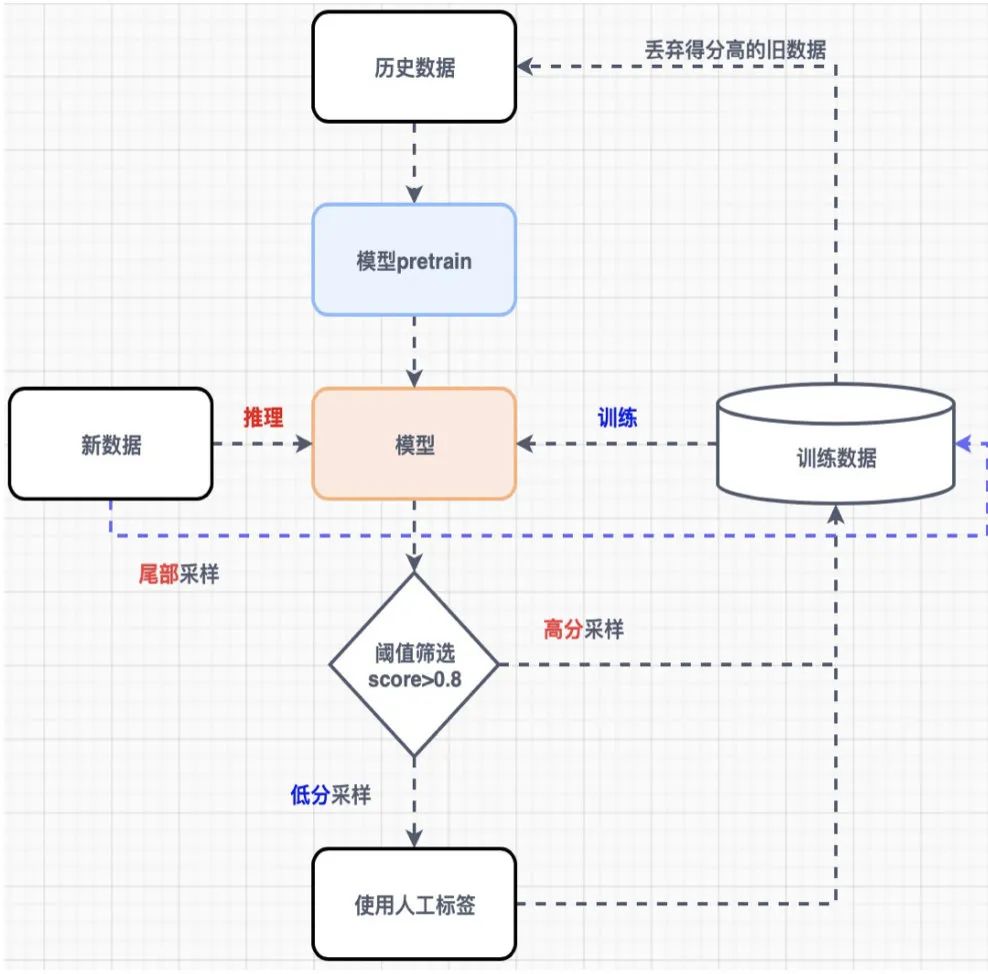
数据处理讲完了,这里列举几个经常用的提升性能的方法
适当容量模型->大的分辨率->无监督pretrain(时间充足情况,几轮数据迭代收益就吃没了)->自监督|伪标签|noise student->ensemble|distill->fixres->sam->ema|swa
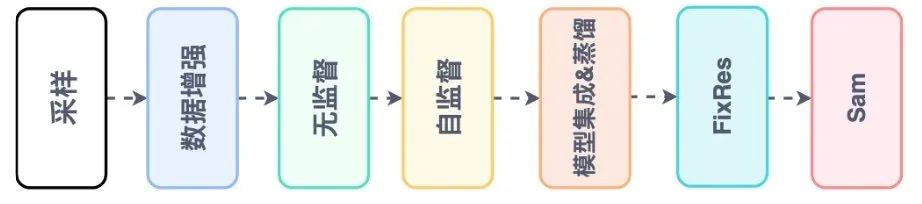
还有一些方法,labelsmooth, mixup,或者调整学习率和优化器,这些可以看我以前写的文章浅谈分割调优
有的时候在解决问题上,复杂的问题需要拆分成为细小的问题,一点点的去优化,而不是一次性的解决,这样可以透过问题去看本质,搞清楚到底需要怎么去做才能解决这个难点,所以模型整体流程解耦很重要。有时候也是需要一点试错的,在时间和条件允许的情况下。
模型选取
对于分类问题来说,模型并不是特别重要的选择。但是对于检测,分割等任务,模型的选取还是在一定程度上会影响业务结果的。
对于检测来说,有几个选取方向,第一个就是采用anchor-base还是anchor-free的方法。anchor-free的好处就是偏向heatmap,对于密集场景效果会更好一些,但是有个问题就是bbox经常抖动,不够稳定,之前有尝试过centernet系列,就算物体不动,也会不停的抖动。第二个就是采用YOLO系列,还是采用FastRcnn系列,当然也会有人延续SSD系列,优化速度和性能。不过通常来说,选一个受众广的模型,衍生的优化,讲解以及变体的文章会更多,更利于查缺补漏。
对于分割来说,比较出名的就是UNet,DeepLabv3等,如果是语义分割,DeepLabv3效果还是不错的,因为语义并不是很在意物体分割出来的边缘,但是如果是抠图或者前景分割,那么UNet结构会更合适,DeepLab系列更加刻画类间区分,而不是边缘细致问题。可以看我之前的文章:
有时候会遇到一些模型轻量化的优化,那么选择模型一定是要自己很熟悉的结构,这样改动起来能够降低试错成本。
业务&paper
虽然Transformer大火,paper层出不穷,不过还是存在很多的问题,对于我来说很重要的一个事情就是训练的收益情况,因为短期内不能有模型效果产出就等价于没工作(手动狗头)。所以很多的时候现有一个可用的版本以后再去研究是否新的模型,新的算法能够给你带来另一个收益价值,毕竟close set和open set之间还是存在很大的一个diff。
当然,如果是刷比赛或者写paper,研究新的算法,挖新的坑是不可避免的,没有学术界的蓬勃发展也不会有如今工业出色的resnet模型诞生。不过工作毕竟和paper不太一样, 考虑的问题更多,场景更加复杂,这个时候遵循奥卡姆剃刀原则可能是一个比较好的方法。
工作多了,模型练的有一定经验了就会发现,大部分花心思的时间还是在处理数据,搞数据,分析bad case上,对于模型的改动基本上带来不了实际的价值了。更多的时候都是针对case来进行调优,改动数据增强,调整训练方法,调整loss等等。数据处理和分析的比较好,有时候会发现自己设计的模型结构甚至可以齐平或者超过最solid paper的方法^-^。
以上内容都是基于自己的情况来进行分析的,肯定存在一些不合理的地方,理性看待^-^。
整理不易,点赞三连↓