
SQL新手必看!详细的「取数拆解」和「提速方案」来了!
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

刚接触sql那会,我总是遇到很多问题,写的sql太过于冗杂或无从下手;连接逻辑不太清晰;解读需求时间过长等等。
一个SQL能够解决的事情,我得整个4,5个小SQL挨个跑,效率太慢了。适应一段时间后,发现SQL取数上还是有机可循,遂写一篇文章以便复盘。
1
拆分取数(拆成整体和重要部分)
举一个例子,假设水果店老板娘有个数据库专门记录一些销售数据,她的店里主要卖苹果,橘子,西瓜,草莓,荔枝,葡萄。
有一天,水果店老板娘想问,这个月店里那些新顾客的情况,那判定条件其实很简单,就只需要选择这个月,有第一次消费记录的顾客的信息抽出来即可。
而倘若问这个月老顾客的消费情况(老顾客指消费有两次及以上的顾客),这个时候取数如果直接设立条件为老顾客会很麻烦,判定条件不太好确定,这里可以直接写一个整体的SQL加上新顾客的SQL情况,再根据具体需求做相减即可。
当然,这里不能直接相减,若直接相减,其实就是把新顾客和老顾客当作了两个独立的圆,总的-新顾客=老顾客。这是不对的,因为会有重叠顾客情况,比如小A这个月第一次来到水果店,发现这个水果店的东西还是很好的,于是第二天又来购买水果,对于小A而言,她是新顾客,又是老顾客的重叠用户。
新顾客和老顾客实际是有交集的两个圆,而非独立的两个圆,所以不能直接相减。这里我们唯一100%能确定的数据便是全部顾客的数据及新顾客的数据。老顾客的大体数据可以通过拆分为总的和新顾客的来得到。
2
取数的分类分组汇总问题
取数时候我最怕碰到分类向的问题,这类通常和group by这个函数紧密结合。当听到分类问题的汇总计算时候,我脑子里是如下画面:

然后会碰到的问题是:
我该先取ABC还是abc还是q1-q18?
什么时候需要group by?
group by哪些变量,是全部还是一个?
需不需要去重?
怎么拼的呢?
尤其再加上,按频率分组看看具体情况,就像脑子里有一个迷宫,有无数条路可以走,而且可以衍生非常多小路。于是,写着写着,我的眼神渐渐空洞起来......
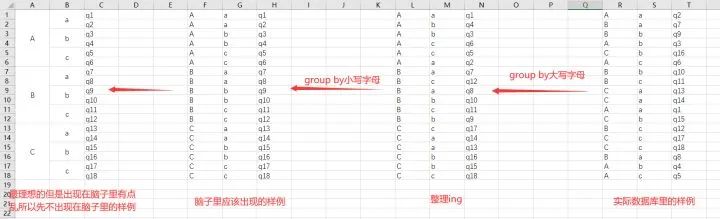
好吧,其实实际上脑子里形成的是下面中间这个画面的话,会变得清晰很多......
下图,group by大写字母的话,它就像一个磁铁一样,A同一条数据和A同一条贴在一起但其他数据不相同的拼在一起,B和B,C和C,即大家都先各自找到组织聚在一起。
再然后,在大写字母这个大类下,把小写字母的整一个小组,即group by小写字母。所以整个思路是group by 大写字母,小写字母(先写大分类,后写小分类),确定完分类之后,尤其一定要卡完最小的那个分类之后,count(),avg(),sum()具体咋搞都行。
再通俗一点理解,group by像一个压汉堡包机子,一条一条的数据就是肉片,只有同种的肉片都放在一块(group by)之后,再汇总计算(最后整合)才能压成一个汉堡。
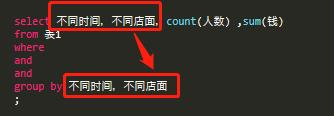
简而言之,对于有涉及分类的,而且是由大到小的,一定要select 大分类,小分类,再汇总计算类,最后group by部分的值要和计算汇总前面的那些分类一一对应,如下:
想知道水果店不同时间(大分类)不同店面(小分类)的一些计算数据:
又或者,想知道水果店不同时间(大分类)不同地区(中分类)不同店面(小分类)的一些计算数据:
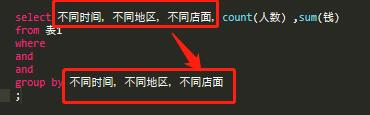
最后的一点,可以有逆向思考方式,比如如果有两个问题,想知道不同时间不同地区的汇总值,以及不同时间不同地区不同店面的汇总值,那么只需要跑那个最详细的sql——分类到极致的那一个。
这里便是不同时间,不同地区,不同店面的那个SQL。然后不同时间不同地区的那个汇总值,完全可以用上面那个SQL算出来,在excel里面汇总整理即可,就不需要多跑了。
3
频次问题
当遇到,说想知道每个顾客这个月来水果店的不同次数时候,我们需要新增一列,也就是频率的,这里便涉及到子查询。
这里先明确分类标准,即按照人出现的次数分一个类,那么为了把这个分类弄出来,先写个频次的sql。
频次标准是,只要我这个人在这个月只出现1次,那么我的频次是1,如果出现了20次,那么我这个人的频次就是20,以此类推。(如果每天顾客最多出现一次,那么count(distinct 时间)。
写完子查询中的频次后,在外围可以根据不同频次下再去进行深层次计算。
select 频次,count(人)
from
(select 人,count(时间) as 频次 from 表1
group by 人) t
group by 频次如果需求取数涉及到两个表,b表没有分类的话,可以直接a表b表join一下
select a.分类,count(xxxx)
from
(select 分类,xxx,xxxx from A 表)a
left join
(select xxx,xxxx from B 表)b
on a.xxx=b.xxx
group by a.分类如果各自都涉及一个分类,需要各自取a,取b后整合成一个新的t表,从t中取数最后group by汇总。
注意:因为t表合成了ab表的所有值,所以这里取的AB表中的所有值最后都要group by一下(对应下面代码的★)
合成为t表之后,直接t表取数,汇总,最后在group by完成
select 分类,分类1,count(xxxx)
from
(select 分类,分类1,xxxx
from
(select 分类,xxx,xxxx from A 表)a
left join
(select 分类1,XXx,xxxx from B 表)b
on a.xxx=b.xxx
group by a.分类,b.分类1,xxxx --★
) t
group by 分类,分类14
其他一些细节
1.时间上如果想取近几天的数据,除了用直接的>='2020-03-15'外,还可以用date_sub函数,指的是从日期减去指定的时间间隔。
比如:date_sub(default. sysdate (-1),6)指的是距离此时近七天的时间。
2.连接两个表的时候,union可以理解为上下拼表(所以两个表的变量名一定要一致),join是左右拼表
3.关于left join,举一个例子,现在有两个表,A表是顾客信息表,B表是商品表(两个表都有”顾客“这个变量名),现在B表中“水果名字"变量下的枚举值有苹果,橘子,荔枝等等。
现在想取的是,吃了苹果和橘子的那些顾客的具体数据值。这里涉及到去重,当时我在想,A表中的一个顾客,如果既吃了苹果,又吃了橘子,那么他就会对应B表中的两条数据了,如何去重呢?
left join便是适用在这种情况下,A left join B,只会是全满足A表下再去匹配表,对于那些A表中没有,B表有的,便会是null代替了。最后再count(distinct b.顾客)便可以把去重后的顾客数给算出来了。
以上都是很浅显的sql理解,其他的想到再补充,希望自己之后取数能够快一点!
- END -
本文为转载分享&推荐阅读,若侵权请联系后台删除