
小一写过最详细的一篇爬虫实战—爬取城市二手房数据
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是小一
今天分享一篇爬虫教程,文章比较细致,适合刚上手的小白,老读者可以酌情加速阅读
文中涉及的代码已经测试过,可以正常跑通,文章案例的所有数据也已经成功爬取。
今天要分享的教程是爬取各大城市的二手房数据,抛开以前的文章不谈,下面的内容应该足够你实现这篇爬虫。以下是正文:
1. 确定目标
今天我们的目标官网链接是:https://www.lianjia.com/
对应的某个城市的二手房页面应该是:https://sz.lianjia.com/ershoufang/
sz 代表城市深圳的简写,广州对应的是 gz。
ok,前提条件交代清楚了,接下来看看今天要爬取的目标数据
有两个页面需要注意,第一个页面是你打开上面那个链接之后显示的列表页面,第二个页面是你点击某个二手房的链接之后跳转的房屋详细数据页面
1.1. 先来说第一个页面
这个页面包括三部分,最上面的搜索部分、中间的列表部分、下面的翻页部分。
上面的搜索部分看似无用,但其实是官方强行设置的一个小操作。
举个最直观的例子:在某个搜索条件下,例如深圳市,对应的清单中有 39053 条记录
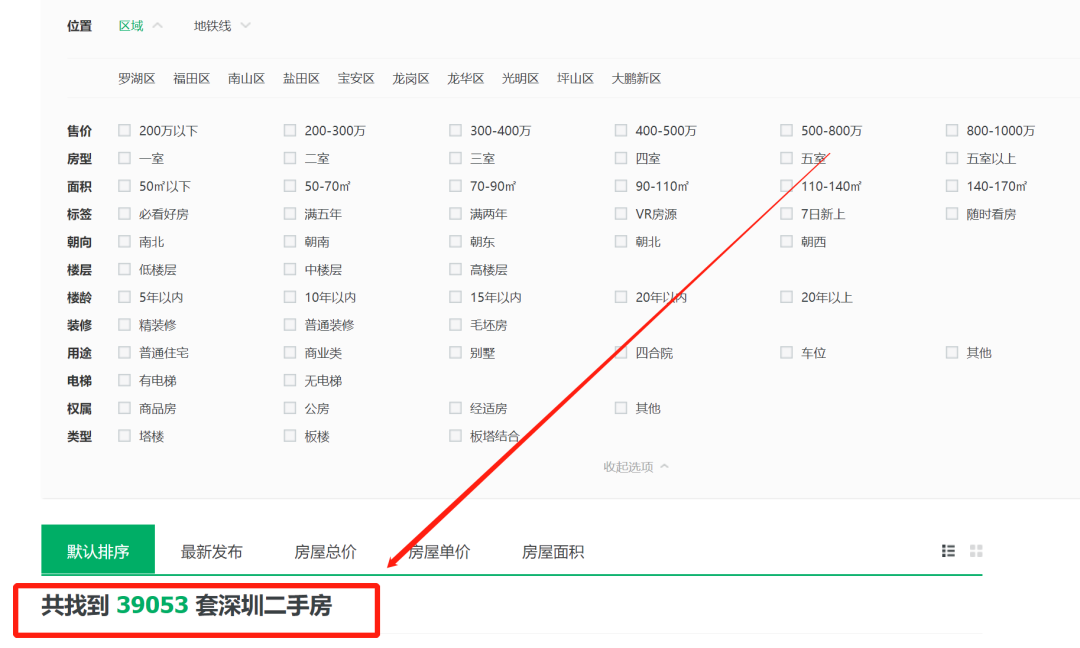
而你将页面拉到最下面进行翻页,发现实际只有 100 页可供操作

根据每一页只有 30 条数据的官方设置,你如果不设置搜索条件,只能拿到 3000 条数据
所以,要想获取全部数据,第一个搜索功能就派上用场了。
但是,添加搜索必然会导致整个程序的复杂度直线上升,特别是现在有如此多的搜索条件
综上,最好的解决方式是筛选出 重要且能完美区分的搜索条件,例如:区域+户型+朝向
上述设置的目的是:
通过条件设置之后,通过筛选 xx区 的数据,发现数据大于 3000条,则利用户型是 x居室 的进行二次筛选,如果发现仍大于 3000条,再次通过 朝x 进行三次筛选
基本上到了第三次筛选之后,数据会在 3000以内,对应的可以全部拿到。
其他筛选条件应该也能实现同样的效果,这个自己设定即可
对了,筛选条件除了每个城市的区域没法固定外,居室和朝向都是固定的
通过F12查看源码可以看到居室和朝向对应的系统定位如下:
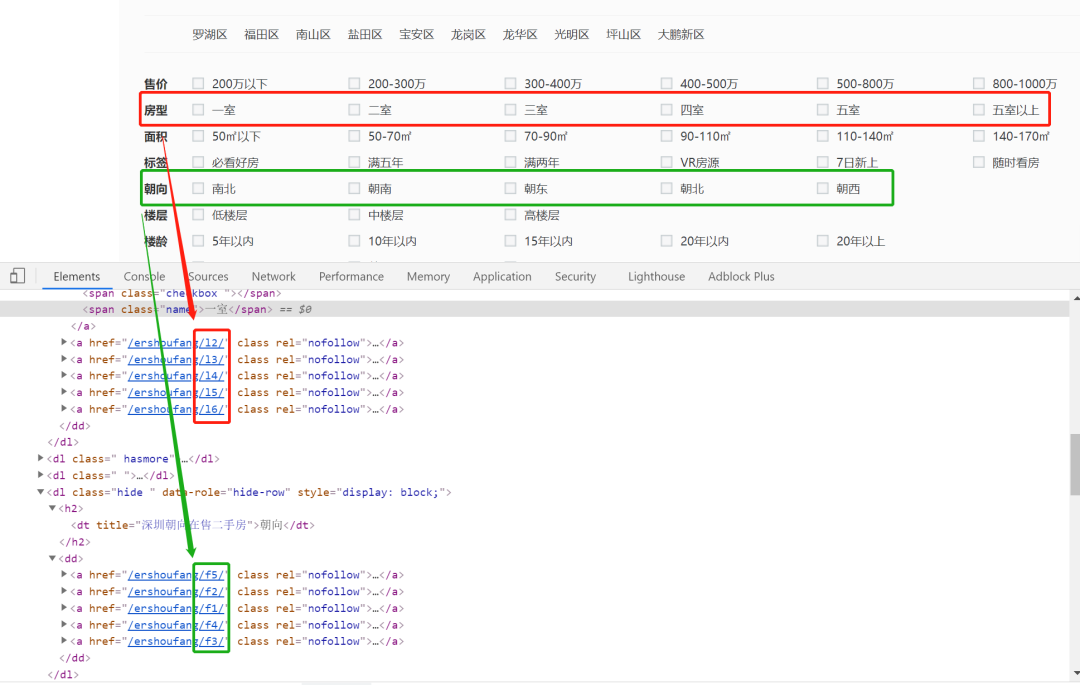
对应的,在代码中也就可以将其进行映射:
# 户型:一室、二室、三室、四室、五室、五室+
self.rooms_number = ['l1', 'l2', 'l3', 'l4', 'l5', 'l6']
# 朝向:朝东+朝南+朝西+朝北+南北
self.orientation = ['f1', 'f2', 'f3', 'f4', 'f5']
再来看中间的列表部分
列表部分有 3 个信息需要注意,如下图:
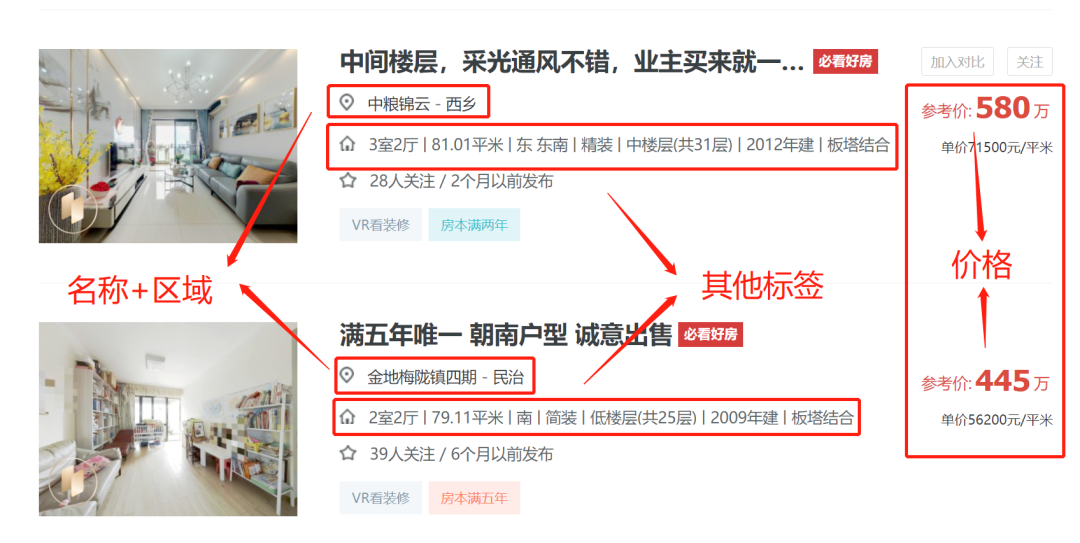
分别是:小区名+区域、其他标签、价格
如果这些字段信息已经可以满足你的数据需求,那对应的爬虫只需要获取这个页面的数据,不需要分析第二个页面,相对来说比较简单
如果你需要更详细的二手房指标,例如:挂牌时间、抵押情况、产权等,以及该房子的经纬度数据,那你需要分析第二个页面
最后是下面的翻页部分
翻页部分原理比较简单,通过多次点击下一页按钮,观察新页面的 url 链接就能发现规律
例如:https://sz.lianjia.com/ershoufang/luohuqu/pg2l1/ 中的 pg2 对应的是第二页的数据
而 l1 在前面我们已经知道是一居室的意思,所以对应的翻页页面的 url 规则应该是:主页+区域+pg页码+居室
在翻页遍历的过程中只需要更改 pg页码 即可。
1.2. 再来说第二个页面
第二个页面是通过第一个页面点击跳转的,我举个例子:
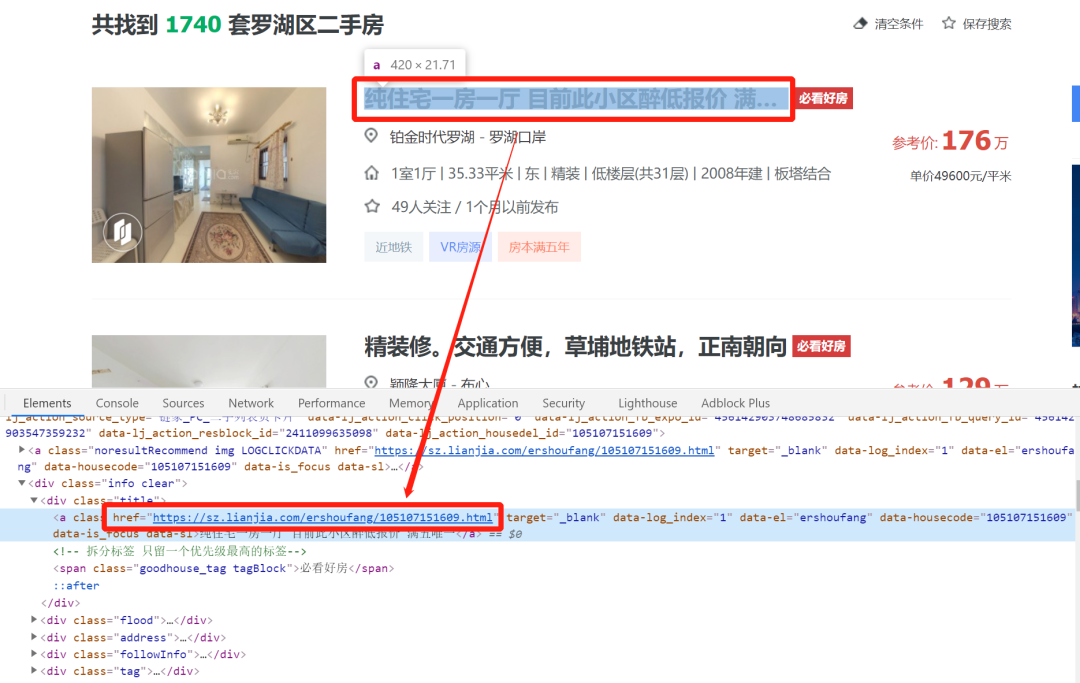
通过点击图中上面的标签,会跳转到下面链接对应的新页面
链接中后面的数字编号对应的是该二手房的编码id。
第二个页面有三个部分,分别是:价格+位置、基本信息+交易信息、地图
价格+位置部分数据如下图:
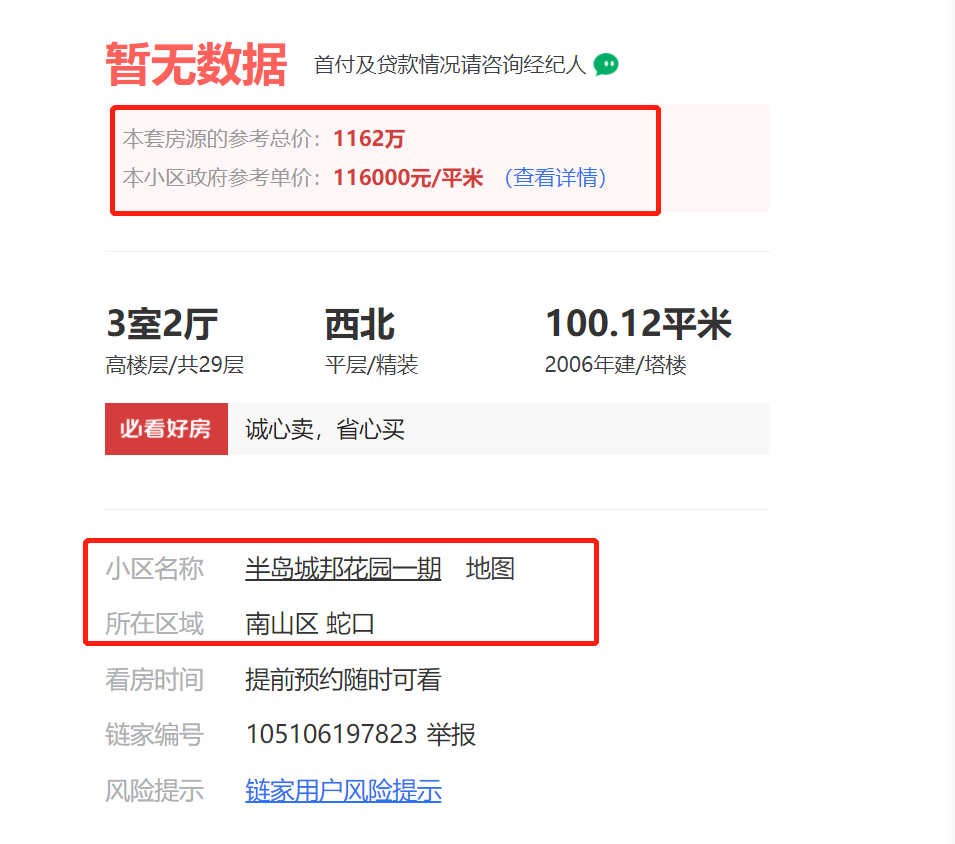
从价格部分可以获取到:参考总价、单价
从所在区域可以获取到:小区名称、大区域+小区域
基本信息+交易信息数据如下图:

因为这张图上的数据比较全,所以我并没有解析上张图的其他数据
这张图上的基本属性和交易属性都可以拿下来作为房屋字段
最后是地图部分的数据:
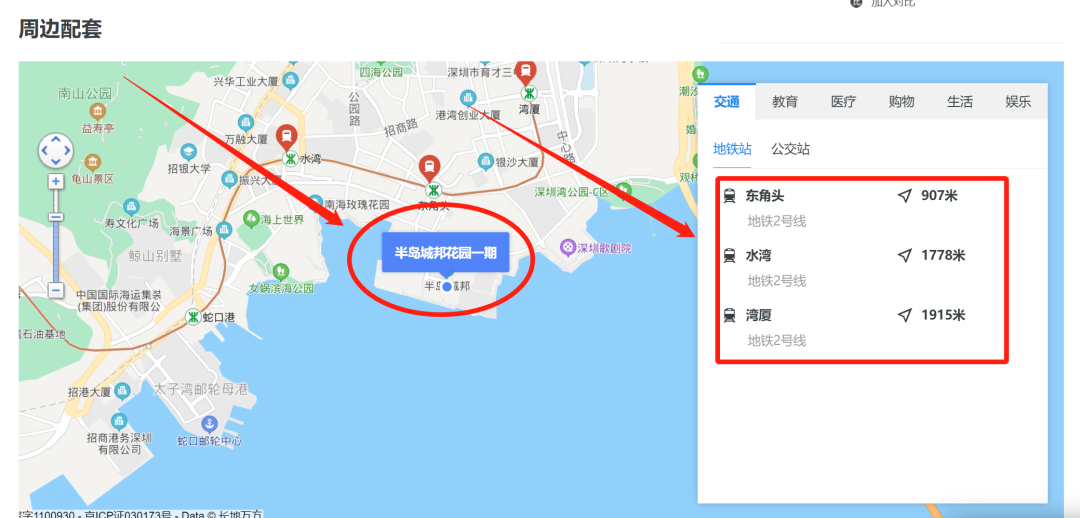
这部分数据比较多,例如:最近的地铁站点、公交站点等
以及在地图插件中隐藏的房屋经纬度数据
因为以前的文章专门爬过地铁站点数据,所以我在这里只拿了经纬度数据
2. 流程设计
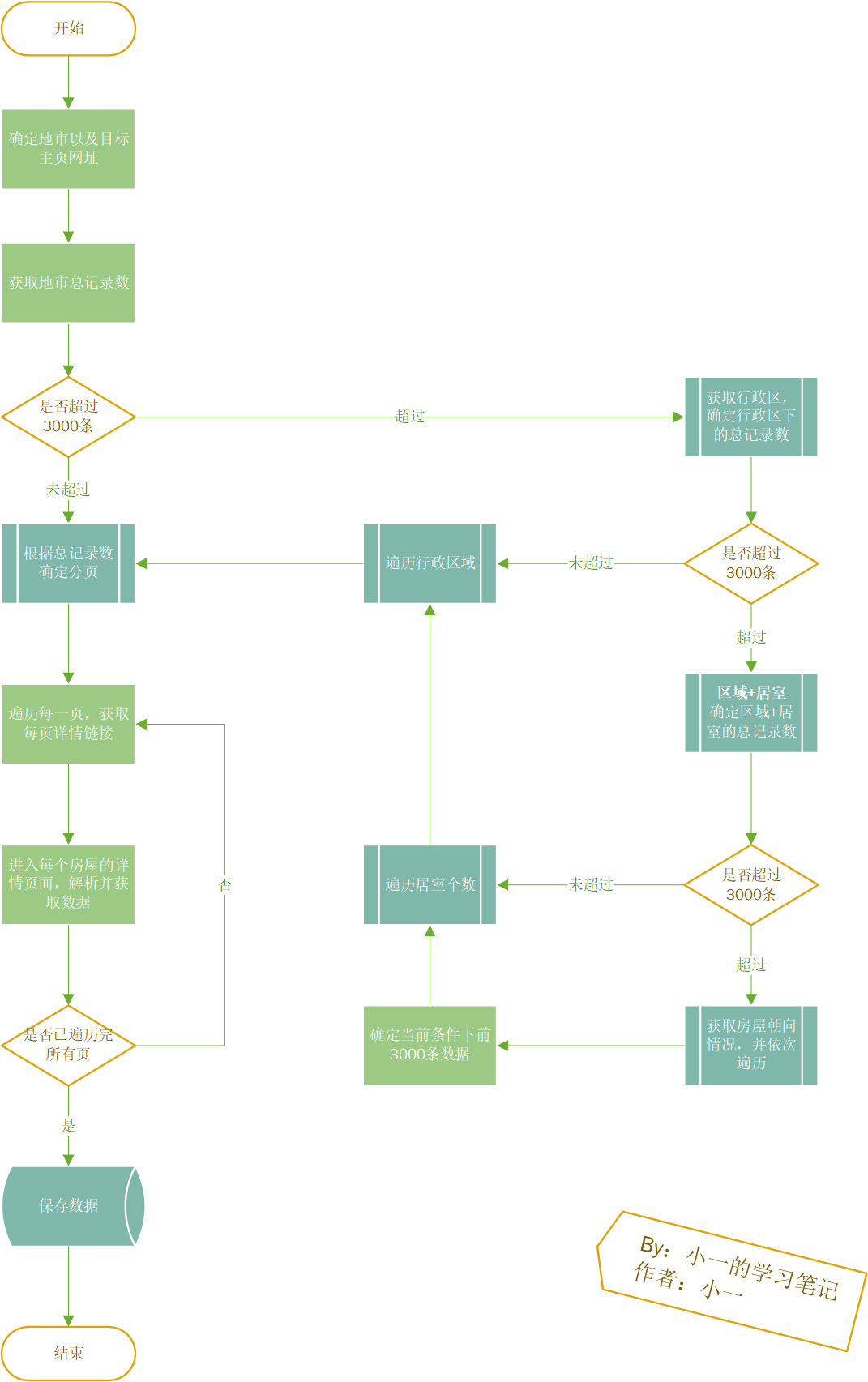
目标已经明确,总结一下上面我们需要注意的地方,大概如下:
首先,判断该城市的总数据是否超过 3000 条,若超过则需要设置筛选条件。先通过区域进行筛选,其次通过居室进行筛选,最后通过朝向进行筛选
上述筛选过程中任一过程若存在数据小于 3000条,则停止往下筛选。
其次,在确定筛选条件之后,通过解析每一页的二手房链接跳转到详情页。翻页操作只需要根据页码重新构造 url 即可
最后,对二手房详情页进行解析,保存数据到本地文件中。
为了方便对整个流程进行复现,我做了一个流程图,如下:
3. 主要代码复现
通过上面的流程图,可以完成整个爬虫的代码复现
因为涉及的代码较多,这里只贴核心代码,完整的代码可以在文末获取
首先是获取当前条件下的房屋数据个数:
def get_house_count(self):
"""
获取当前筛选条件下的房屋数据个数
"""
# 爬取区域起始页面的数据
response = requests.get(url=self.current_url, headers=self.headers)
# 通过 BeautifulSoup 进行页面解析
soup = BeautifulSoup(response.text, 'html.parser')
# 获取数据总条数
count = soup.find('h2', class_='total fl').find('span').string.lstrip()
return soup, count
其次是主页面的设计:
判断是否超过3000,若超过则进行第二级筛选,若未超过则直接获取数据
def get_main_page(self):
# 获取当前筛选条件下数据总条数
soup, count_main = self.get_house_count()
# 如果当前当前筛选条件下的数据个数大于最大可查询个数,则设置第一次查询条件
if int(count_main) > self.page_size*self.max_pages:
# 获取当前地市的所有行政区域,当做第一个查询条件
soup_uls = soup.find('div', attrs={'data-role': 'ershoufang'}).div.find_all('a')
self.area = self.get_area_list(soup_uls)
# 遍历行政区域,重新生成筛选条件
for area in self.area:
self.get_area_page(area)
else:
# 直接获取数据
self.get_pages(int(count_main), '', '', '')
# 保存数据到本地
self.data_to_csv()
对应的在确定区域的条件下,继续判断并筛选居室
在确定区域和居室的条件下,继续判断并筛选朝向
在确定区域、居室和朝向的条件下,直接获取 前3000条 数据
可以看到上面的流程十分类似,对应的代码大家注意看源码就行。
如果在三级筛选下仍存在超过3000条数据,照葫芦画瓢就行
在代码执行的过程中,建议每获取到 10条 数据保存一次,避免中途程序出错而前功尽弃
对应的代码可以参考如下:
'''超过10条数据,保存到本地'''
if len(self.data_info) >= 10:
self.data_to_csv()
在保存到本地 csv 的时候,建议采用追加的方式进行保存
也就是在 data_to_csv 函数中这样写:
def data_to_csv(self):
"""
保存/追加数据到本地
@return:
"""
df_data = pd.DataFrame(self.data_info)
if os.path.exists(self.save_file_path) and os.path.getsize(self.save_file_path):
# 追加写入文件
df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', header=False, index=False)
else:
# 写入文件,带表头
df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', index=False)
# 清空当前数据集
self.data_info = []
另外,考虑到大多时候需要运行好几次程序才能获取到所有数据
在每次运行程序的时候先统计已经爬到的房屋数据,跳过已经爬到的数据
对应的代码可以这样写:
# 所有已经保存的房屋 id,用来验证去重
self.house_id = self.get_exists_house_id()
def get_exists_house_id(self):
"""
通过已经爬取到的房屋信息,并获取房屋id
@return:
"""
if os.path.exists(self.save_file_path):
df_data = pd.read_csv(self.save_file_path, encoding='utf-8', )
df_data['house_id'] = df_data['house_id'].astype(str)
return df_data['house_id'].to_list()
else:
return []
最后,在主函数中只需要设置城市名称和数据保存路径即可
代码如下:
if __name__ == '__main__':
city_number = 'sz'
city_name = '深圳'
url = 'https://{0}.lianjia.com/ershoufang/'.format(city_number)
page_size = 30
save_file_path = '二手房数据-sz.csv'
house = House(city_name, url, page_size, save_file_path)
house.get_main_page()
完整的代码可以在文末获取
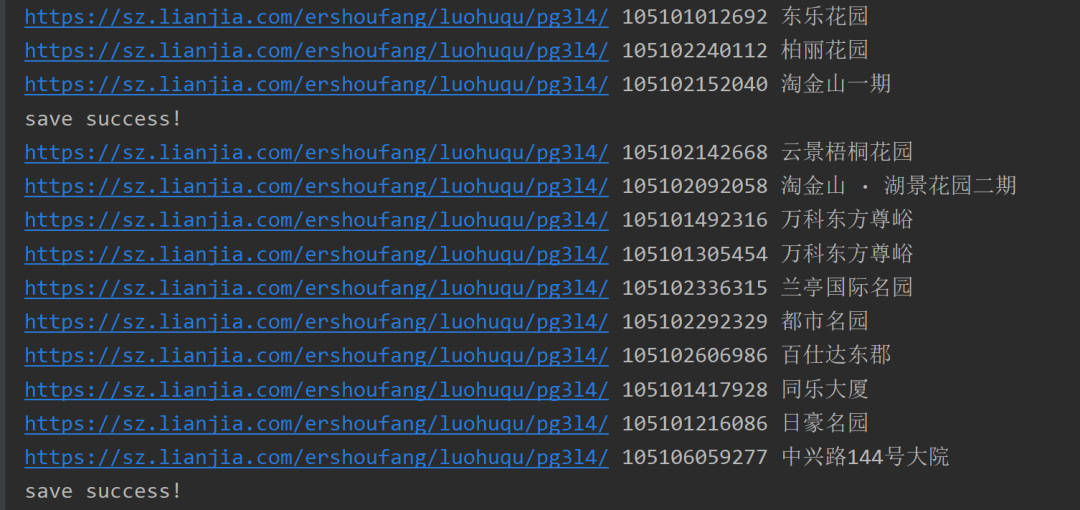
4. 程序运行截图
如果是第一次运行程序,设置好相关参数后,运行截图如下:
如果之前有运行过程序,中途退出了。
再次运行时无需设置参数,直接运行即可,截图如下:
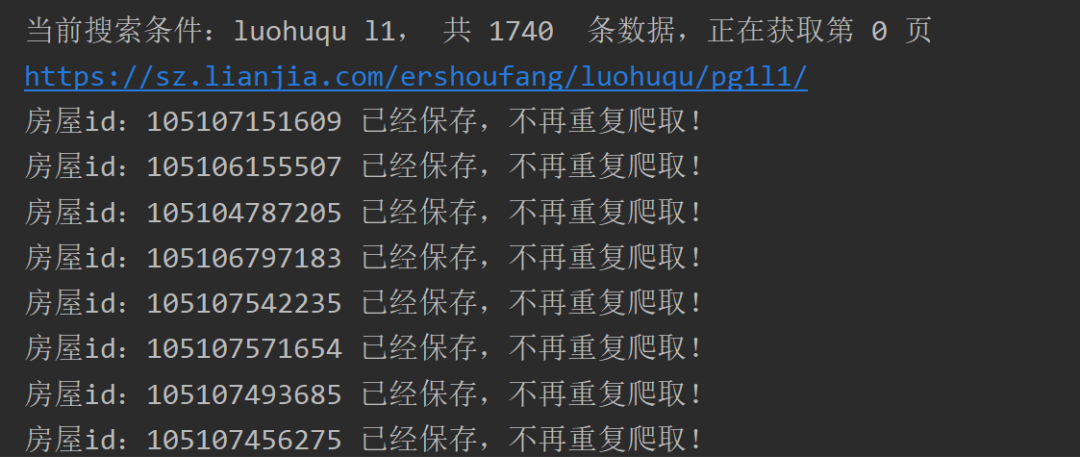
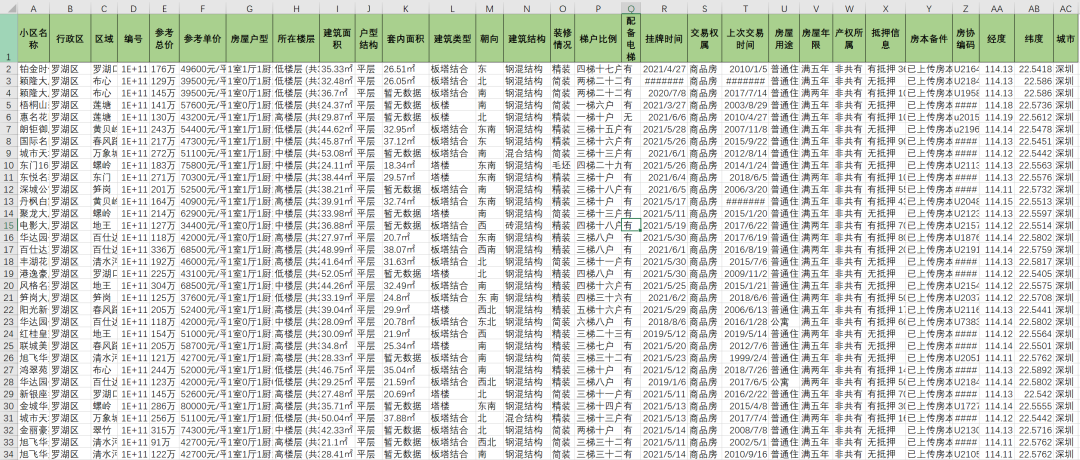
最终爬取到的部分数据如下:
5. 写在最后的话
整体来说,虽然流程的设计比较繁琐,但是仍然是很基础的一篇内容
与本文相关的爬虫参数设置、简单爬虫伪装,网页解析都可以在以前的文章中找到,在此不一一提及
另外,建议大家在运行的过程中,适当的设置程序休眠,理性爬虫。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~