
吐血整理:盘点19种大数据处理的典型工具

导读:本文讨论大数据处理的生命周期和典型工具。
作者:高聪 王忠民 陈彦萍
来源:大数据DT(ID:hzdashuju)

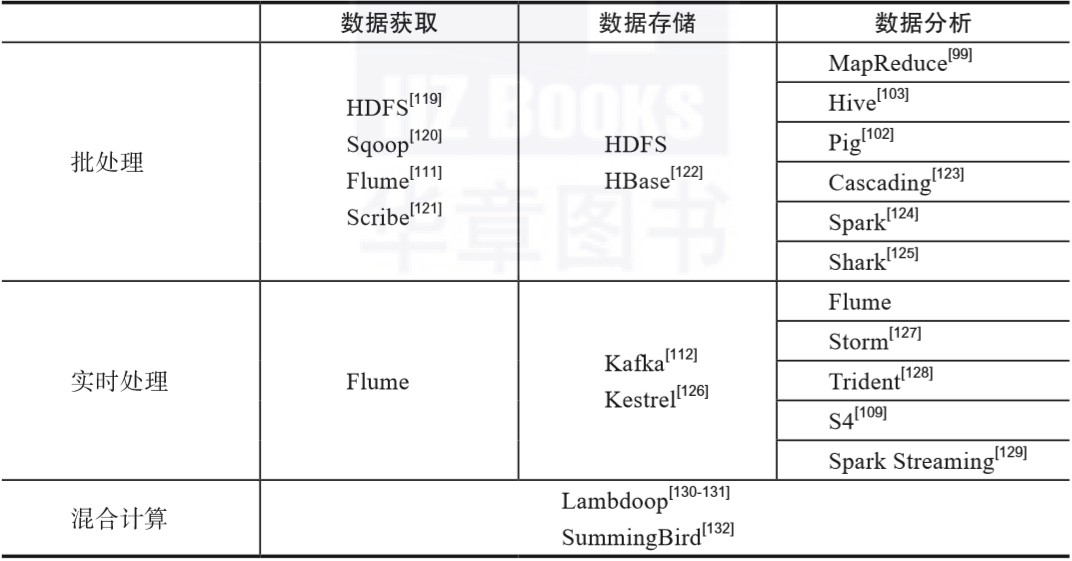
在数据获取阶段,通常涉及从多源异构的数据源获取数据,这些数据源可能是批处理数据源,也有可能是实时流数据源; 在数据存储阶段,需要对前一阶段已经获取到的数据进行存储,以便进行后续的分析与处理,常见的存储方式有磁盘(disk)形式和无盘(diskless)形式。 在数据分析阶段,针对不同的应用需求,会运用各类模型和算法来对数据进行分析与处理。


导入数据:从诸如MySQL、SQL Server和Oracle等关系数据库将数据导入到Hadoop下的HDFS、Hive和HBase等数据存储系统。
导出数据:从Hadoop的文件系统中将数据导出至关系数据库。

针对可靠性,其提供了从强到弱的三级保障,即End-to-end、Store on failure和Best effort。 针对可扩展性,其采用三层的体系结构,即Agent、Collector和Storage,每层都可以在水平方向上进行扩展。

第一部分Scribe Agent为用户提供接口,用户使用该接口来发送数据。 第二部分Scribe接收由Scribe Agent发送来的数据,根据各类数据所具有的不同topic再次分发给不同的实体。 第三部分Storage包含多种存储系统和介质。



用户自定义函数(User Defined Function,UDF) 用户自定义聚合函数(User Defined Aggregation Function,UDAF) 用户自定义表生成函数(User Defined Table-generating Function,UDTF)

在Local模式下,Pig的运行独立于Hadoop体系结构,全部操作均在本地进行。 在MapReduce模式下,Pig使用了Hadoop集群中的分布式文件系统HDFS。

复制(copy) 过滤(filter) 合并(merge) 计数(count) 平均(average) 结合(join)

在速度方面,Spark使用基于有向无环图(Directed Acyclic Graph,DAG)的作业调度算法,采用先进的查询优化器和物理执行器提高了数据的批处理和流式处理的性能。 在简易方面,Spark支持多种高级算法,用户可以使用Java、Scala、Python、R和SQL等语言编写交互式应用程序。 在通用方面,Spark提供了大量的通用库,使用这些库可以方便地开发出针对不同应用场景的统一解决方案,极大地降低了研发与运营的成本。 在兼容方面,Spark本身能够方便地与现有的各类开源系统无缝衔接,例如已有的Hadoop体系结构中的HDFS和Hbase。


对于点对点模型,消息生成后进入队列,由用户从队列中取出消息并使用。当消息被使用后,其生命周期已经结束,即该消息无法再次被使用。虽然消息队列支持多个用户,但一个消息仅能够被一个用户所使用。 对于发布/订阅模型,消息生成后其相关信息会被发布到多个话题中,只要订阅了相关话题的用户就都可以使用该消息。与点对点模型不同,在发布/订阅模型中一个消息可以被多个用户使用。

控制节点为主节点,其上运行的Nimbus进程主要负责状态监测与资源管理,该进程维护和分析Storm的拓扑,同时收集需要执行的任务,然后将收集到的任务指派给可用的工作节点。 工作节点为从节点,其上运行的Supervisor进程包含一个或多个工作进程(worker),工作进程根据所要处理的任务量来配置合理数量的执行器(executor)以便执行任务。Supervisor进程监听本地节点的状态,根据实际情况启动或者结束工作进程。
对于非事务控制,单个批次内的元组处理可以出现部分处理成功的情况,处理失败的元组可以在其他批次进行重试。 对于严格的事务控制,单个批次内处理失败的元组只能在该批次内进行重试,如果失败的元组一直无法成功处理,那么进程挂起,即不包含容错机制。 对于不透明的事务控制,单个批次内处理失败的元组可以在其他批次内重试一次,其容错机制规定重试操作有且仅有一次。

对于批处理,任务执行的对象是预先保存好的数据,其任务频率可以是每小时一次,每十小时一次,也可以是每二十四小时一次。批处理的典型工具有Spark和MapReduce。 对于流处理,任务执行的对象是实时到达的、源源不断的数据流。换言之,只要有数据到达,那么就一直保持处理。流处理的典型工具有Kafka和Storm。

Producer,即数据的抽象,传递给指定的平台做MapReduce流编译; Platform,即平台的实例,由MapReduce库实现,SummingBird提供了平台对Storm和相关内存处理的支持; Source,即数据源; Store,即包含所有键值对的快照; Sink,即能够生成包含Producer具体数值的非聚合流,Sink是流,不是快照; Service,即供用户在Producer流中的当前数值上执行查找合并(lookup join)和左端合并(left join)的操作,合并的连接值可以为其他Store的快照、其他Sink的流和其他异步功能提供的快照或者流; Plan,由Platform生成,是MapReduce流的最终实现。对于Storm来说Plan是StormTopology的实例,对于Memory来说Plan是内存中的stream。

评论