
吐血整理:一份不可多得的架构师图谱!
概述
微服务
消息队列
概述
一个技术图谱:
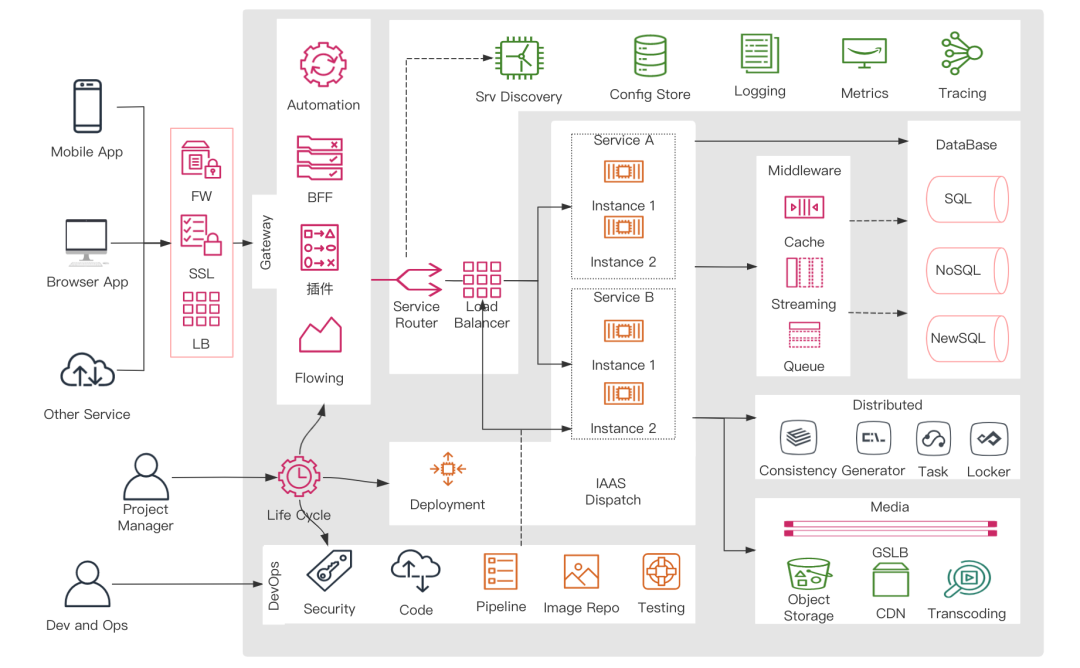
完整的思维导图:
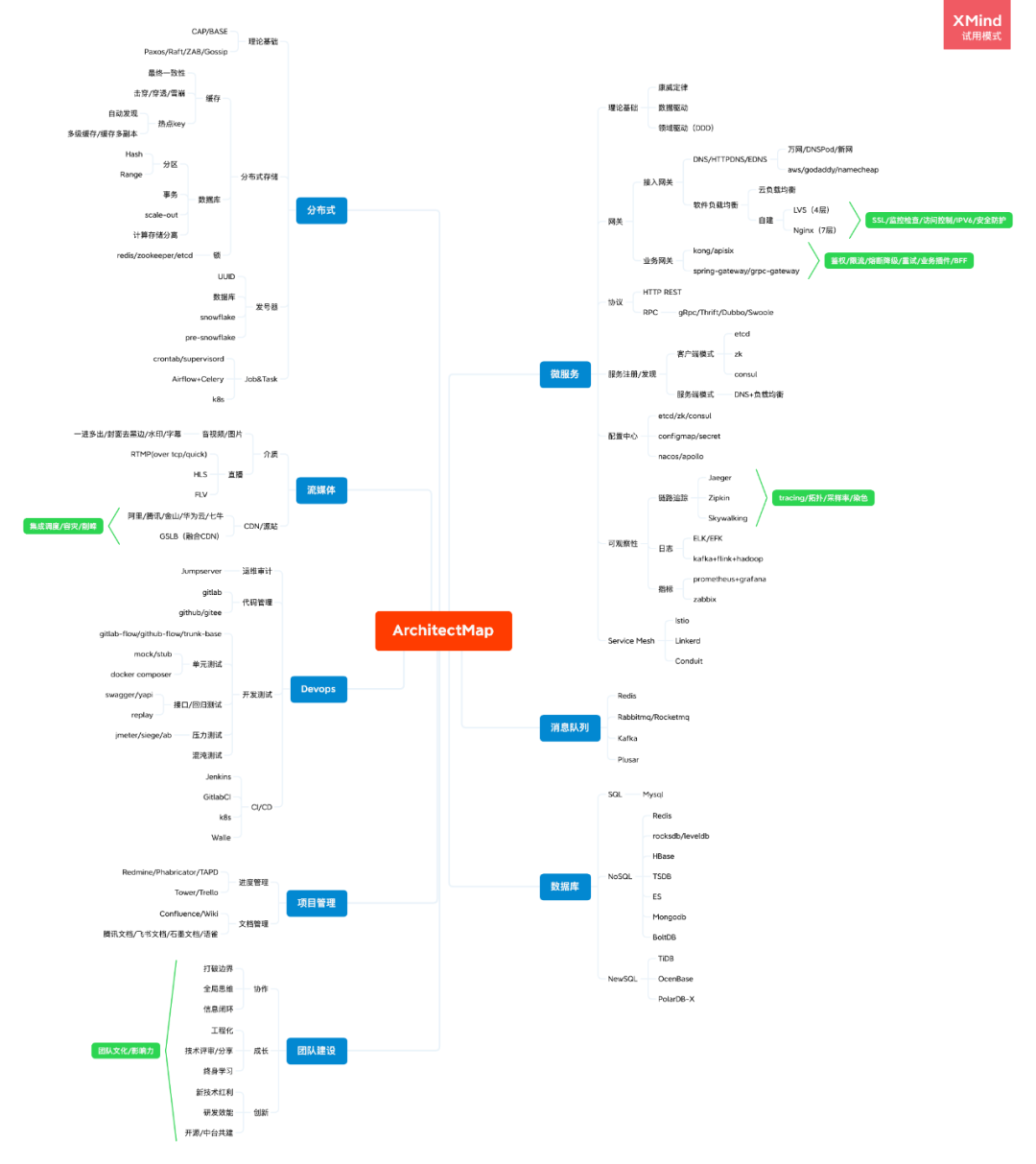
微服务
| 理论基础
在康威的这篇文章中,最有名的一句话就是:
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.
组织沟通方式决定系统设计,对于复杂的系统,聊设计就离不开聊人与人的沟通,解决好人与人的沟通问题,才能有一个好的系统设计
时间再多一件事情也不可能做的完美,但总有时间做完一件事情,这与架构设计的“简单、合适、演化”思维不谋而合
线型系统和线型组织架构间有潜在的异质同态特征,更直白的说,你想要什么样的系统,就搭建什么样的团队,定义好系统的边界和接口,团队内应该是自治的,这样将沟通成本维持在系统内部,每个子系统就会更加内聚
大的系统组织总是比小系统更倾向于分解,面对复杂的系统及组织,往往可以采用分而治之
根据需求划分出初步的领域和限界上下文,以及上下文之间的关系
进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象
对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根
为聚合根设计仓储,并思考实体或值对象的创建方式
在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构
| 网关
安全防护目的是保护服务数据以及可用性,例如防范常见的 DDOS/CC 网络攻击,反爬虫,自定义访问控制,自研成本往往比较高,可以借助云上一系列的高防、防火墙服务。 SSL(TLS)用来提供外部 https 访问,https 可以防止数据在传输过程中不被窃取、改变,确保数据的完整性,在支付或者用户登录等敏感数据场景,可以起到一定的保护作用,同时 https 页面对搜索引擎也比较友好。 IPV6,全球 43 亿 IPV4 地址已经在 2019 年年底耗尽,网信办在 2018 年开始就已经推行各大运营商、CDN 厂商、互联网核心产品支持 IPV6,我们公司之前也是试点之一。IPV6 的支持只需要增加一条“AAAA”DNS记录,将域名解析到自持 IPV6 的 IP/VIP 即可。IPV4 到 IPV6 由于存在兼容性等问题,一定是长期共存的,过渡方案可以采用 IPV6 代理(IPV6 代理转发到 IPV4 服务)或者双栈(同时支持 IPV6 和 IPV4)。
业务网关:
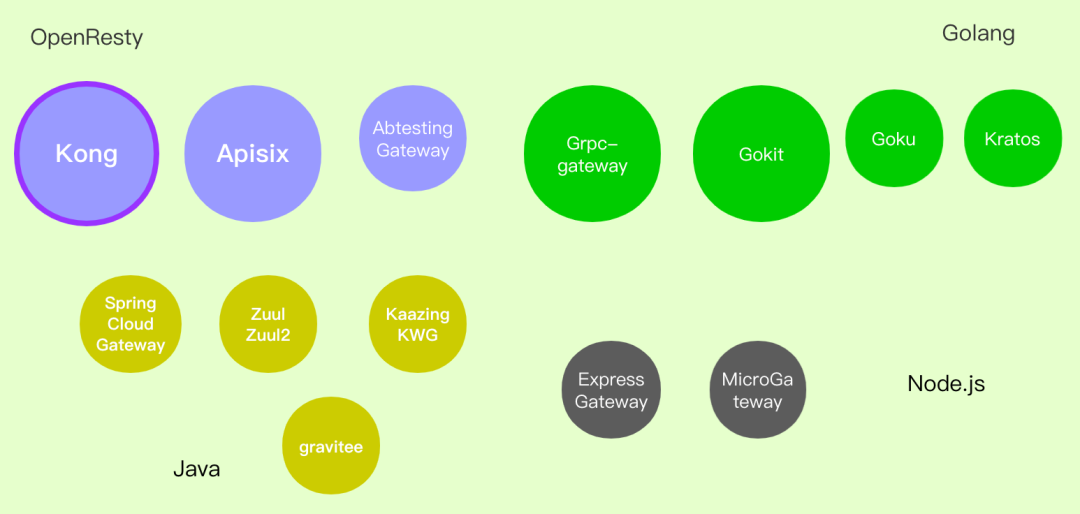
| 协议
更清晰的 API 定义,例如 gRPC 协议的定义文件 proto,自身就可以作为很好的 API 文档,日常开发中也可以把 proto 文件独立版本库管理,精简目录结构,方便不同的服务引用。
更好的传输效率,通过序列化和反序列化进一步压缩网络传输数据,不过序列化、反序列化也会有一定的性能损耗,protobuf 可以说很好的兼顾了这两点。
更合适的容错机制,可以基于实际的业务场景,实现更合适的超时控制与异常重试机制,以应对网络抖动等对服务造成的影响。
| 服务注册/发现
从实现方式上可以分为服务端模式与客户端模式:
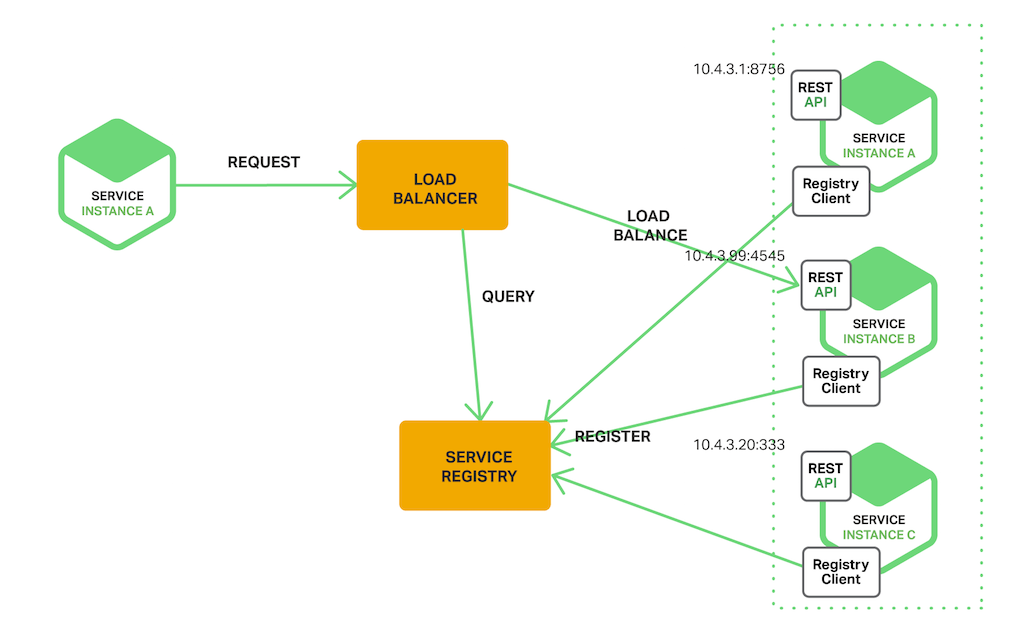
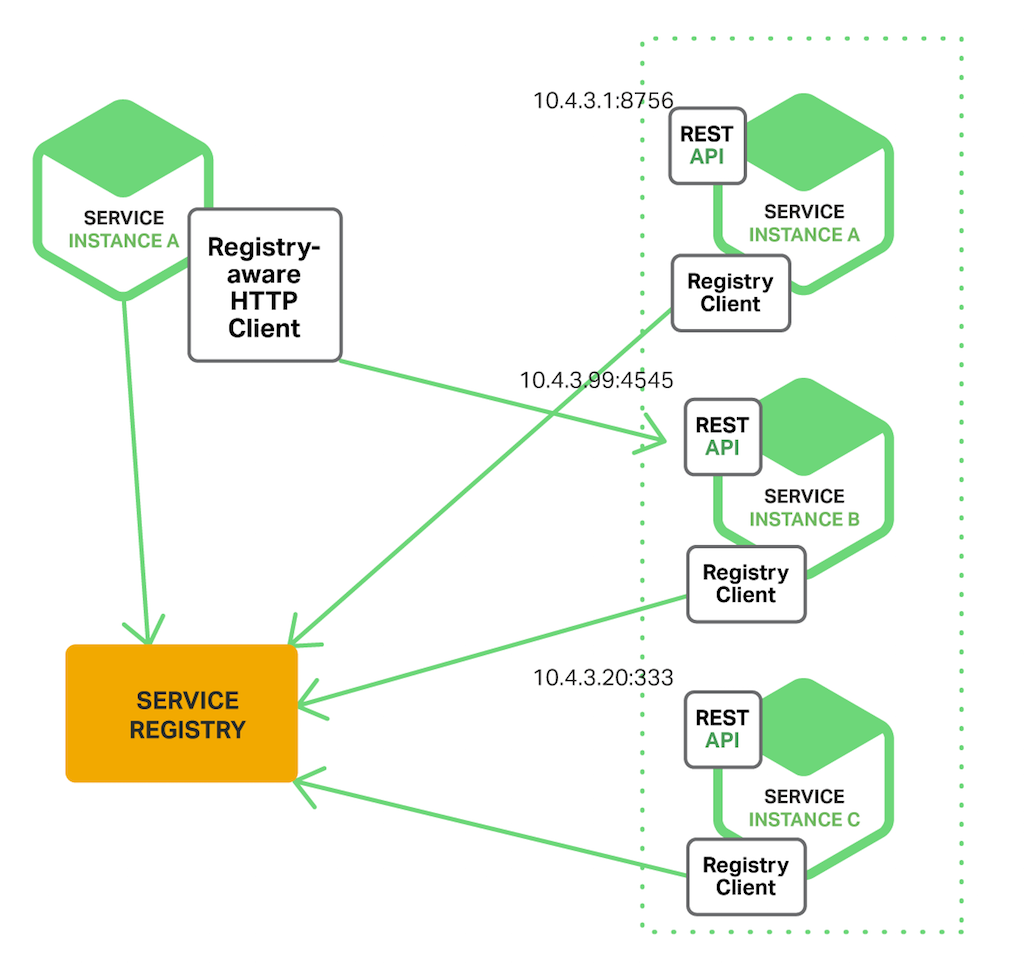
客户端模式:可以借助注册中心实现,注册中心负责服务的注册与健康检查,客户端通过监听配置变更的方式及时把配置中心维护的配置同步到本地,通过客户端负载均衡策略直接向后端机器发起请求。
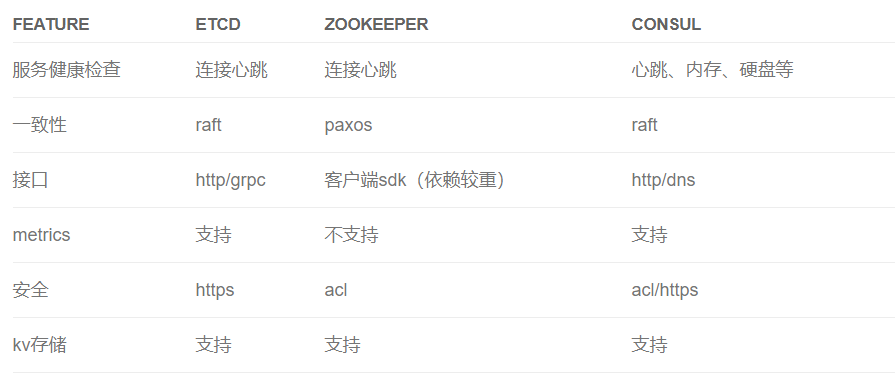
Consul 提供开箱即用的功能,etcd 社区和接入易用性方面更优一些,他们之间的一些具体区别:
| 配置中心
| 可观察性
很长一段时间,这三者是独立存在的,随着时间的推移,这三者已经相互关联,相辅相成。
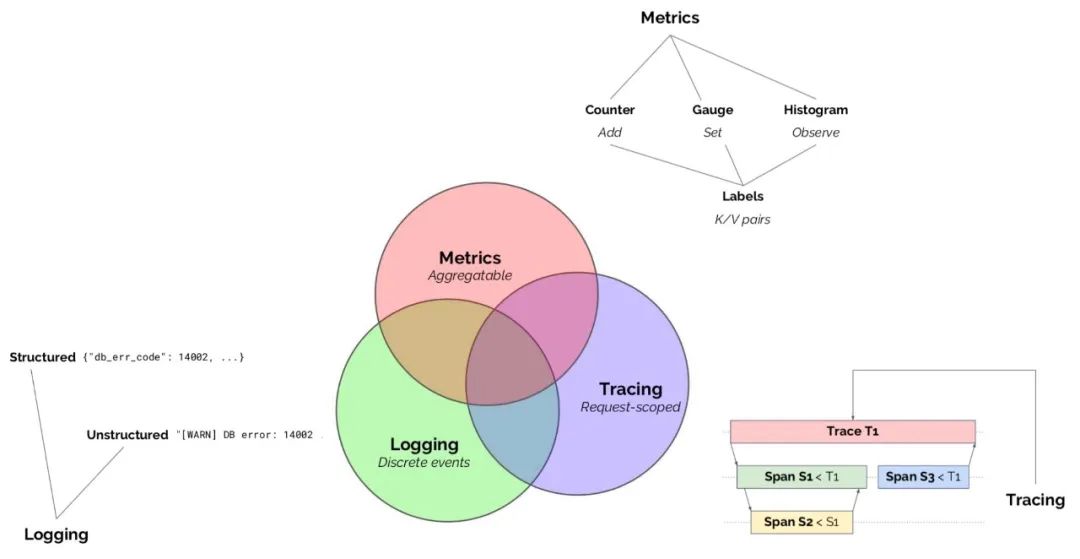
为了解决不同的分布式系统 API 不兼容的问题,诞生了 OpenTracing 规范,OpenTracing 中的 Trace 可以被认为是由多个 Spacn 组成的 DAG 图。
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 后被调用, FollowsFrom)
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
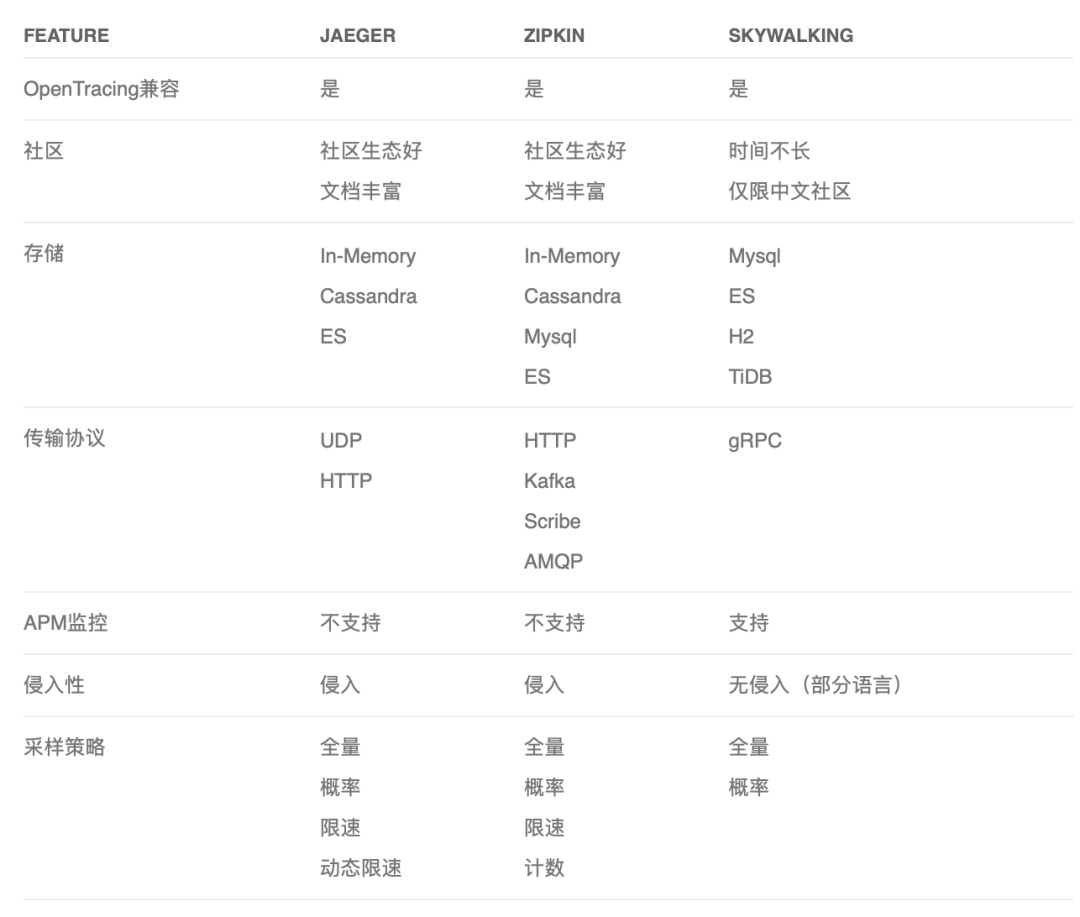
OpenTracing 中的佼佼者当属 Jaeger、Zipkin、Skywalking。他们之间的一些对比:
Emergency:system is unusable Alert:action must be taken immediately Critical:critical conditions Error:error conditions Warning:warning conditions Notice:normal but significant condition Informational:informational messages Debug:debug-level messages
资源监控:CPU、内存、IO、fd、GC等 业务监控:QPS、模调、耗时分布等
Counter 只增不减的计数器,例如请求数(http_requests_total)。基于此数据模型,使用 Prometheus 提供的强大 PromQL 表达式能够拓展出更加适合开发观察的指标数据。分钟增量请求:increase(http_requests_total[1m]) 分钟 QPS:rate(http_requests_total[1m]) Gauge 可增可减的时刻量,例如 Go 语言协程数(go_goroutines) 波动量:delta(go_goroutines[10m]) Histogram 直方图,不同区间内样本的个数。例如,耗时 50ms-100ms 每分钟请求量,100ms-150ms 每分钟请求量。 Summary 概要,反应百分位值。例如,某 RPC 接口,95% 的请求耗时低于 150ms,99% 的请求耗时低于 200ms。
Prometheus 指标支持 pull 和 push 模式:
Pull:服务暴露 metrics 接口,指标内存更新,Prometheus server 定时拉取,性能更好,但要考虑易失性
Push:指标推送 push-gateway,Promethus server 从 gateway 拉取,适用瞬时业务场景(定时任务)
| Service Mesh
我们前边讲的服务发现、熔断降级、安全、流量控制、可观察性等能力。这些通用能力在 Service Mesh 出现之前,由 Lib/Framework 通过一些切面的方式完成,这样就可以在开发层面上很容易地集成到我们的应用服务中。
但是并没有办法实现跨语言编程,有什么改动后,也需要重新编译重新发布服务。理论上应该有一个专门的层来干这事,于是出现了 Sidecar。
第一代 Service Mesh,像 Linkerd,后边又出现了第二代 Service Mesh,Istio,职责分明,分离出处数据面和控制面。
但是 Sidecar 作为代理层,避免不了性能损耗(CPU 序列化反序列化 UDS),所以 proxyless service mesh 重新被提起,和之前的 「RPC + 服务发现治理」区别是啥?
感觉这个名词营销味道略重。其实不能简单的 “Proxyless Service Mesh” 理解为 “一个简单的 RPC 框架,暴露了几个超时参数到配置中心来控制”,它重在统一协议、API。
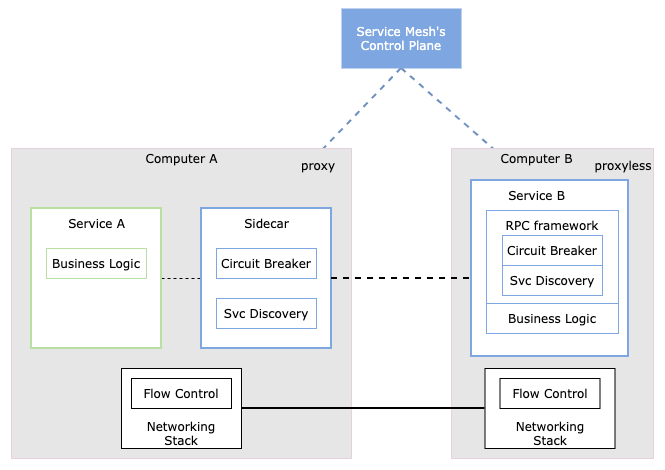

servicemesh 对于微服务基础设施的一种演进,但不代表他已经非常成熟了,相反像迁移成本高,甚至一些可用性设计还不如业务自己做那么灵活。
这些现实的问题还摆在面前,我觉得这也是属于技术进化的一种趋势,当一项技术足够成熟的时候,又回衍生出新的复杂度问题,从而又需要发展出新技术解决。
消息队列
也就是说:消息的发送者和接收者不需要同时与消息队列交互。消息会保存在队列中,直到接收者取回它。
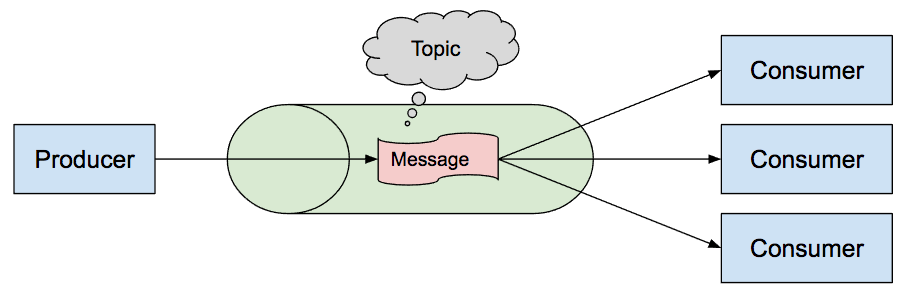
HA:自身的高可用性保障,避免消息队列的引入而影响整体服务的可用性 高吞吐:在面对海量数据写入能否保持一个相对稳定、高效的数据处理能力 功能丰富性:是否支持延迟消息、事务消息、死信队列、优先级队列等 消息广播:是否支持将消息广播给消费者组或者一组消费者 消息堆积能力:在数据量过大时,是否允许一定消息堆积到broker 数据持久性:数据持久化策略的采用,也决定着数据在宕机恢复后是否会丢失数据 重复消费:是否支持ack机制,在消费者未正确处理消息时,支持重新消费 消息顺序性:针对顺序消费的场景保证数据按写入时间的顺序性
| Redis
功能丰富性:只支持普通的消息类型 数据持久性:Pub/Sub 只提供缓冲区广播能力,不进行持久化,List/Stream 即使基于 aof 和 rdb 持久化策略,但是并没有事务性保障,在宕机恢复后还是存在丢失数据的可能性 消息堆积能力:List 随长度增大,内存不断增长;Pub/Sub 只在缓冲区内堆积,缓冲区满消费者强制下线;Stream 创建时可以指定队列最大长度,写满后剔除旧消息
| RabbitMQ vs Kafka vs RocketMQ
| Pulsar
设计上避免了 Kafka 遇到的功能丰富性、扩容等方面的问题,采用计算、存储分离的架构,broker 层只作为“API 接口层”,存储交给更专业的 bookeeper,由于 broker 层的无状态性,结合 Kubernetes 等非常方便的进行扩容。
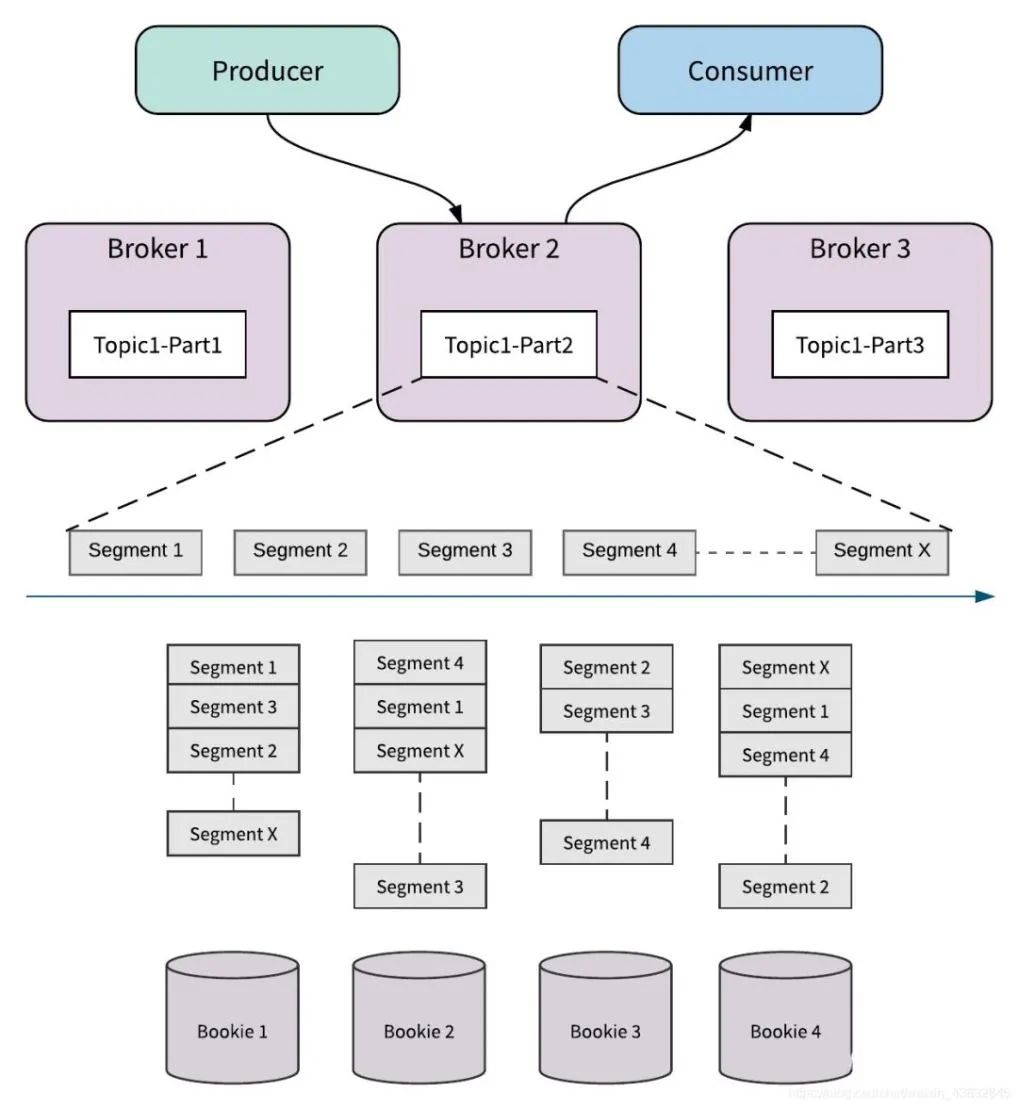
HA、高吞吐:和 Kafka 类似,通过多 partition 和选举机制功,除此之外,还支持丰富的跨地域复制能力 功能丰富性:可以支持秒级的延迟消息,以及独特的重试队列和私信队列 消息顺序性:为了实现 partition 消息的顺序性,和 Kafka 一样,都需要将消息写入到同一 broker,区别是 Kafka 会同时存储消息在该 broker,broker 和 partiton 绑定在一起,而 Pulsar 可以将消息分块(segment)后,更加均匀的分散到 bookeeper 节点上,broker 只需要记录映射关系即可,这样在资源扩容时,可以更加快速便捷
文章来源:https://c1n.cn/J3wve
转自:幽鬼,侵删