
利用InfluxDB+Grafana搭建Flink on YARN作业监控大屏
点击上方蓝色字体,选择“设为星标”




前言
硬件参数
CPU:Intel E5 v4 12C/24T
内存:96GB
硬盘:500GB SSD * 2
网络:10Gbps
操作系统:CentOS 7.5 64-bit
InfluxDB 1.8
Grafana 6.7.4
安装与配置InfluxDB
yum localinstall安装,可以自动解决依赖关系。wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.0.x86_64.rpm
yum -y localinstall influxdb-1.8.0.x86_64.rpm安装完毕后,配置文件位于/etc/influxdb/influxdb.conf。具体配置项可参见官方文档,有一些需要注意的,列举如下。
元数据存储目录
[meta]
dir = "/data1/influxdb/meta"时序数据和write-ahead log存储目录
InfluxDB采用LSM Tree改良而来的TSM存储引擎,所以WAL、compaction等机制它都有。建议两种数据分盘存储,提高读写效率。
[data]
dir = "/data2/influxdb/data"
wal-dir = "/data1/influxdb/wal"并发及慢查询设置
写入超时write-timeout默认是10s,当数据量很大时可能比较紧张,可以改大点。
[coordinator]
write-timeout = "20s"
max-concurrent-queries = 0
query-timeout = "60s"
log-queries-after = "30s"保留策略设置
[retention]
enabled = true
check-interval = "60m"HTTP设置
HTTP日志没有太大必要,可以关掉。
[http]
enabled = true
bind-address = ":8086"
auth-enabled = false
log-enabled = false启动InfluxDB并建库
根据官方文档的说明,如果Linux使用的init系统是systemd,并且以服务方式启动InfluxDB(即service influxdb start),那么所有日志会固定打进/var/log/messages里,使用journalctl可以查看。但是这样不太方便,所以我们后台启动InfluxDB,并将日志做重定向,即:
nohup influxd -config /etc/influxdb/influxdb.conf > /var/log/influxdb/influxd.log 2>&1 &还可以对上述日志文件用logrotate做切割,不再赘述。
然后进入InfluxDB的Shell。默认没有用户名和密码,HTTP端口为8086。
~ influx
Connected to http://localhost:8086 version 1.8.0
InfluxDB shell version: 1.8.0
>创建Flink监控指标的数据库。
> CREATE DATABASE flink_metrics;
> SHOW DATABASES;
name: databases
name
----
_internal
flink_metricsInfluxDB自动生成的保留策略(retention policy)是保留所有历史数据。我们可以创建新的保留策略,使监控数据自动过期,防止硬盘爆掉。以下就在flink_metrics库上创建了一周的保留策略,并自动设为默认。
> CREATE RETENTION POLICY "one_week" ON "flink_metrics" DURATION 168h REPLICATION 1 DEFAULT;
>
> SHOW RETENTION POLICIES ON "flink_metrics";
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
one_week 168h0m0s 24h0m0s 1 true配置Flink Metrics Reporter
将$FLINK_HOME/opt下的flink-metrics-influxdb-
metrics.reporter.influxdb.class: org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host: bd-flink-mon-001
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink_metrics启动Flink on YARN作业,稍等片刻,就可以看到该库下产生了许多measurement——即等同于数据库中的表。InfluxDB没有显式建表的语句,执行INSERT语句时会自动建表。
> USE flink_metrics;
Using database flink_metrics
> SHOW MEASUREMENTS;
name: measurements
name
----
jobmanager_Status_JVM_CPU_Load
jobmanager_Status_JVM_CPU_Time
jobmanager_Status_JVM_ClassLoader_ClassesLoaded
jobmanager_Status_JVM_ClassLoader_ClassesUnloaded
jobmanager_Status_JVM_GarbageCollector_ConcurrentMarkSweep_Count
jobmanager_Status_JVM_GarbageCollector_ConcurrentMarkSweep_Time
jobmanager_Status_JVM_GarbageCollector_ParNew_Count
jobmanager_Status_JVM_GarbageCollector_ParNew_Time
jobmanager_Status_JVM_Memory_Direct_Count
jobmanager_Status_JVM_Memory_Direct_MemoryUsed
jobmanager_Status_JVM_Memory_Direct_TotalCapacity
jobmanager_Status_JVM_Memory_Heap_Committed
jobmanager_Status_JVM_Memory_Heap_Max
jobmanager_Status_JVM_Memory_Heap_Used
jobmanager_Status_JVM_Memory_Mapped_Count
jobmanager_Status_JVM_Memory_Mapped_MemoryUsed
jobmanager_Status_JVM_Memory_Mapped_TotalCapacity
jobmanager_Status_JVM_Memory_NonHeap_Committed
jobmanager_Status_JVM_Memory_NonHeap_Max
jobmanager_Status_JVM_Memory_NonHeap_Used
jobmanager_Status_JVM_Threads_Count
jobmanager_job_downtime
jobmanager_job_fullRestarts
......查询一下试试。注意InfluxDB中的一行数据称为一个point,point又包含time(时间戳)、tag(有索引字段)、field(无索引的值)。
> SELECT * FROM "taskmanager_job_task_operator_heartbeat-rate" LIMIT 1;
name: taskmanager_job_task_operator_heartbeat-rate
time host job_id job_name operator_id operator_name subtask_index task_attempt_id task_attempt_num task_id task_name tm_id value
---- ---- ------ -------- ----------- ------------- ------------- --------------- ---------------- ------- --------- ----- -----
1592324240887000000 ths-bigdata-flink-worker043 b23bec2afe87a3b4fa7e930824a8dff4 com.sht.bigdata.clickstream.job.AnalyticsAndOrderLogExtractor bff97a3c8e9f03115fa1e7908e04df21 Source: source_kafka_ms_order_done 6 52c07162c4344d43898dfd3be6d77ac3 0 bff97a3c8e9f03115fa1e7908e04df21 Source: source_kafka_ms_order_done -> order_flatMap_log_record container_e08_1589127619440_0062_01_000002 0time字段默认是以Unix时间戳显示的,如果想要可读的时间字符串,执行PRECISION rfc3339语句即可。
另外有一个小问题需要注意:
如果Flink的版本<=1.9,Flink报告的监控指标中有NaN和正负无穷,InfluxDB无法handle这些,就会在TaskManager日志中打印出大量报警信息,非常吵闹,详情可见FLINK-12579。解决方法也简单,就是找到Flink源码中flink-metrics-influxdb项目的POM文件,手动将influxdb-java依赖项的版本改高(如改成2.17),重新打包并替换掉$FLINK_HOME/lib目录下的同名文件。
安装启动Grafana
wget https://dl.grafana.com/oss/release/grafana-6.7.4-1.x86_64.rpm
yum -y localinstall grafana-6.7.4-1.x86_64.rpm
service grafana-server start浏览器访问3000端口就行了。
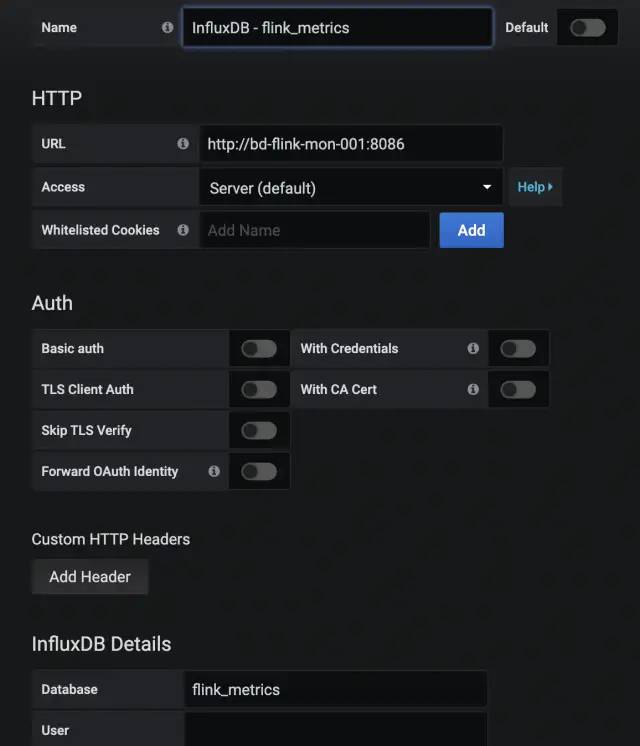
添加InfluxDB数据源
点击Configuration -> Data Sources -> Add data source添加InfluxDB数据源,截图如下。
Flink Metrics Dashboard示例
点击Create -> Dashboard -> Settings -> Variables,先添加两个变量:一是作业名称,二是TaskManager的ID,这两个字段经常用来分组。
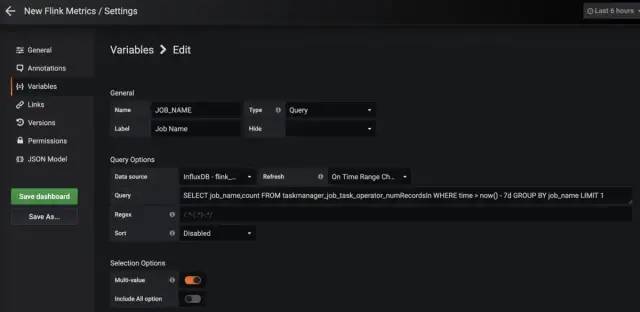
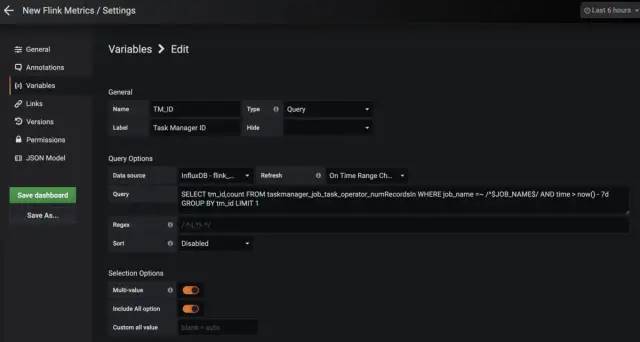
说个小tip,如果不想让不同时期启动的相同作业监控数据发生混淆,可以在指定Flink作业的名称时,加上一些其他的东西(如该作业的Maven profile名称以及启动时间)进行区分。
public static String getJobName(Class<?> clazz, Properties props) {
return StringUtils.join(Arrays.asList(
clazz.getCanonicalName(),
new LocalDateTime().toString("yyyyMMddHHmmss"),
props.getProperty("profile.id")
), '_');
}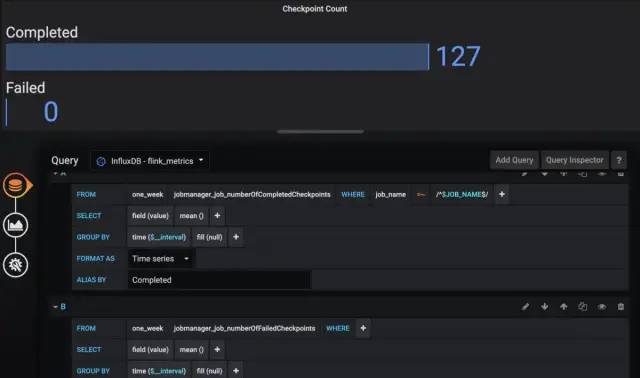
再举个栗子,以折线图按Source分组展示端到端延迟:
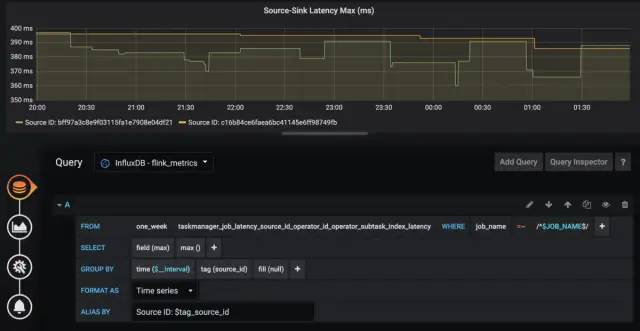
注意,端到端延迟的tag只有murmur hash过的算子ID(用uid()方法设定的),并没有算子名称,并且官方暂时不打算解决这个问题(见FLINK-8592),所以我们只能曲线救国,要么用最大值来表示,要么将作业中Sink算子的ID统一化。
文章不错?点个【在看】吧! ?