
ONNX 浅析:如何加速深度学习算法工程化?
点击左上方蓝字关注我们

AlphaGo击败围棋世界冠军李世石以来,关于人工智能和深度学习的研究呈现井喷之势。

这些框架都有相似之处,他们的输入是一个或者一组多维数据,数据经过多层运算单元之后输出运算结果。训练框架支持BackPropogation等训练方法,可以自动调整模型参数,用于算法设计。推理框架则是单纯只能用于模型推理运算,不能调整模型本身,用于算法部署落地。
01
Why ONNX?
笔者之前曾开发深度神经网络算法,当时选择的训练框架是Caffe,需要落地部署到Linux、iOS、Android等多个平台。Linux选择的是Nvidia的cuDNN;iOS选择的是CoreML;Android选择的是NNAPI,Caffe的模型描述格式是caffemodel。
它使用自定义的Protobuf (https://github.com/BVLC/caffe/tree/master/src/caffe/proto),但是显然,无论是cuDNN、CoreML、NNAPI都无法直接使用caffemodel,CoreML的模型描述使用另一种定义 (https://apple.github.io/coremltools/mlmodel/index.html),cuDNN和NNAPI都是low-level的推理引擎,需要使用者将这个模型组装起来。
对于CoreML来说,我们需要把caffemodel转为coremlmodel格式,对于 cuDNN和NNAPI,我们需要解析caffemodel,然后自己组装出完整的网络模型。这个过程繁琐而且容易出错,当时有强烈的冲动,希望定义一个统一的模型描述格式,所有的训练框架训练所得的网络模型,都是用这个格式来描述,在设备上部署推理时,相应的推理引擎支持解析这个统一的描述格式,直接完成部署落地,岂不美哉。
当然此事并不容易,要定义个统一的模型描述格式,不仅仅需要对机器学习技术有深入的理解,而且将之推广成为事实上的行业标准,更需要有很大的行业影响力,并不是如笔者这样的无名小卒可以为之。所幸已经有社区在做这个事情了,这就是Open Neural Network Exchange(ONNX)。
02
计算模型描述
ONNX的模型描述采用了Google的Protocol Buffer语言。最外层的结构是ModelProto,它的定义如下:
message ModelProto {int64 ir_version = 1;repeated OperatorSetIdProto opset_import = 8;string producer_name = 2;string producer_version = 3;string domain = 4;int64 model_version = 5;string doc_string = 6;GraphProto graph = 7;repeated StringStringEntryProto metadata_props = 14;repeated TrainingInfoProto training_info = 20;repeated FunctionProto functions = 25;}
比较重要的字段有:
lr_version : 当前的ONNX模型文件的版本,目前发布的最新版本为IR_VERSION_2019_3_18 = 6. 发布于2019年,版本7还在制定中。
opset_import: 当前的模型文件所依赖的算子domain和版本。
graph: 这个模型执行的运算图,这个是最重要的字段。
GraphProto的定义如下:
message GraphProto {repeated NodeProto node = 1;string name = 2; // namespace Graphrepeated TensorProto initializer = 5;repeated SparseTensorProto sparse_initializer = 15;string doc_string = 10;repeated ValueInfoProto input = 11;repeated ValueInfoProto output = 12;repeated ValueInfoProto value_info = 13;repeated TensorAnnotation quantization_annotation = 14;}
比较重要的字段有:
initializer : 模型的每一网络层的参数, 模型训练完成之后参数就被固定下来。
input : 模型的输入格式。
output : 模型的输出格式。
nodes : 定义了模型的所有运算模块, 依照推理的次序排布。
NodeProto的定义如下:
message NodeProto {repeated string input = 1; // namespace Valuerepeated string output = 2; // namespace Valuestring name = 3; // namespace Nodestring op_type = 4; // namespace Operatorstring domain = 7; // namespace Domainrepeated AttributeProto attribute = 5;string doc_string = 6;}
比较重要的字段有:
input : 输入参数的名字。
output : 输出参数的名字,这里需要留意的是,每一个网络层之间的连接使用输入和输出的名字来确立的。
op_type : 算子的类型。
attributes : 算子的属性, 其解析取决于算子的类型。
ONNX中最复杂的部分就是关于各种算子的描述,这也可以理解,构成神经网络的主体就是这些算子。attributes 就是算子的一组带名字的属性。
本文中,我们介绍一个在mobilenetv2-7.onnx使用最多的算子: conv。
卷积神经网络在语音,图像,视频等处理上获得了巨大成功. ONNX关于卷积网络层的属性定义主要有:
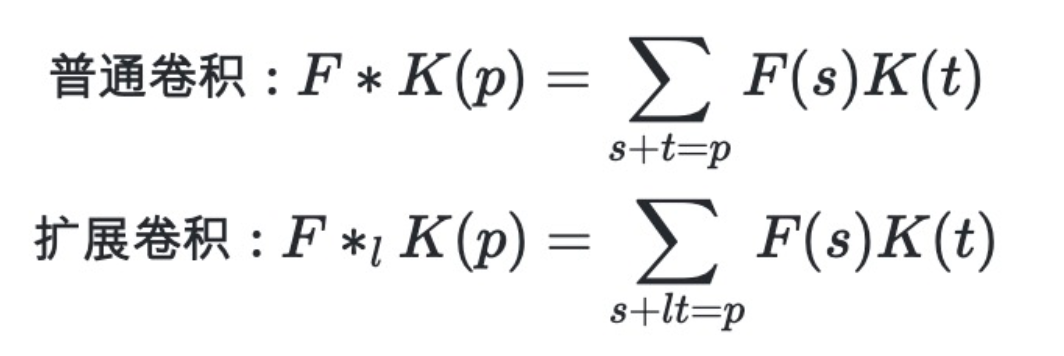
group: 分组卷积, 其定义见文献14. 默认为1, 即不分组。
kernel_shape: 定义了卷积核的大小。
pads: 定义了上下左右填充的像素数。
strides: 定义了卷积运算的步长。
03
ONNX的支持情况
各家的训练和推理框架还在继续发展,ONNX想成为行业标准显然还为时尚早,但是目前尚没有看到其他更好的通用模型描述格式,我们简单归纳一下现在的ONNX的支持情况(不完整):

参考文献
[2] TENSORFLOW: https://www.tensorflow.org/
[3] CNTK: https://github.com/Microsoft/CNTK
[4] PYTORCH: https://pytorch.org/
[5] TNN: https://github.com/Tencent/TNN
[6] MNN: https://github.com/alibaba/MNN
[7] CUDNN: https://developer.nvidia.com/zh-cn/cudnn
[8] TENSORRT: https://developer.nvidia.com/zh-cn/tensorrt
[9] COREML: https://developer.apple.com/documentation/coreml
[10] NCNN: https://github.com/Tencent/ncnn
[11] NNAPI: https://developer.android.com/ndk/guides/neuralnetworks
[12] Protocol Buffers: https://developers.google.com/protocol-buffers
[13] Dilated Convolutions https://arxiv.org/abs/1511.07122
[14] Dynamic Group Convolutions https://arxiv.org/abs/2007.04242
END