
图谱讲义 | 第一讲-第3节-知识图谱的价值
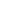
本讲义系列主要整理自浙江大学《知识图谱导论》(浙江省优秀研究生课程)的课程讲义。作为一门导论性质课程,该课程希望帮助初学者梳理知识图谱基本知识点和关键技术要素,帮助技术决策者建立知识图谱的整体视图和系统工程观,帮助前沿科研人员拓展创新视野和研究方向。
本次推文主要介绍讲义的“第一讲 知识图谱概论 第3节 知识图谱的价值”,更多相关内容请点击上方“话题”或文末“往期推荐”。

这一节我们介绍知识图谱的价值和应用。

知识图谱有什么用处呢?知识图谱源于互联网,所以第一个落地的应用当然也是互联网搜索引擎。前面我们已经介绍过,谷歌在2012年推出知识图谱支持的新搜索引擎时,提出的口号是“Things,not Strings!”。
Web的理想是链接万物,搜索引擎最终的理想是让我们能直接搜索万事万物,这是非常朴素而且简单的理念。知识图谱支持的事物级别而非文本级别的搜索,大幅度提升了用户的搜索体验,因此,当前所有的搜索引擎公司都把知识图谱作为基础数据,并成立独立部门来持续建设。

当前实现智能问答功能主要有三种形式,第一种是问答对,这种实现简单的建立问句和答句之间的匹配关系,优点是易于管理,缺点是无法支持精确回答。
第二种形式类似于Stanford的Squad竞赛这种形式,要求能够从大段文本中准确定位答案,这当然是我们终极期望的形式,但源于语言理解本身的困难比较难于完全实用。例如小米小爱的后台实现中,这种形式的问答仅仅能支持个位数百分比的问句。

例如在一个反恐场景中,需要定义恐怖分子、恐怖事件、高危区域等基本概念和它们之间的语义关系。PALANTIR再通过机器学习算法和自然语言处理技术从各种数据来源获取信息并灌入到这个Ontology中。
事实上,很多领域的大数据分析问题并不需要构建很复杂的算法模型,如果能根据分析的需要构建一个知识图谱,大部分大数据分析问题都可以转化为一个知识图谱上面的查询问题。当然有了图结构的数据,我们也可以更加容易的在知识图谱上叠加各种图算法,例如图嵌入算法、图神经网络等等。这些算法利用知识图谱中存在的关系进一步挖掘和推理未知的关系,从而大幅提升数据分析的深度和广度。
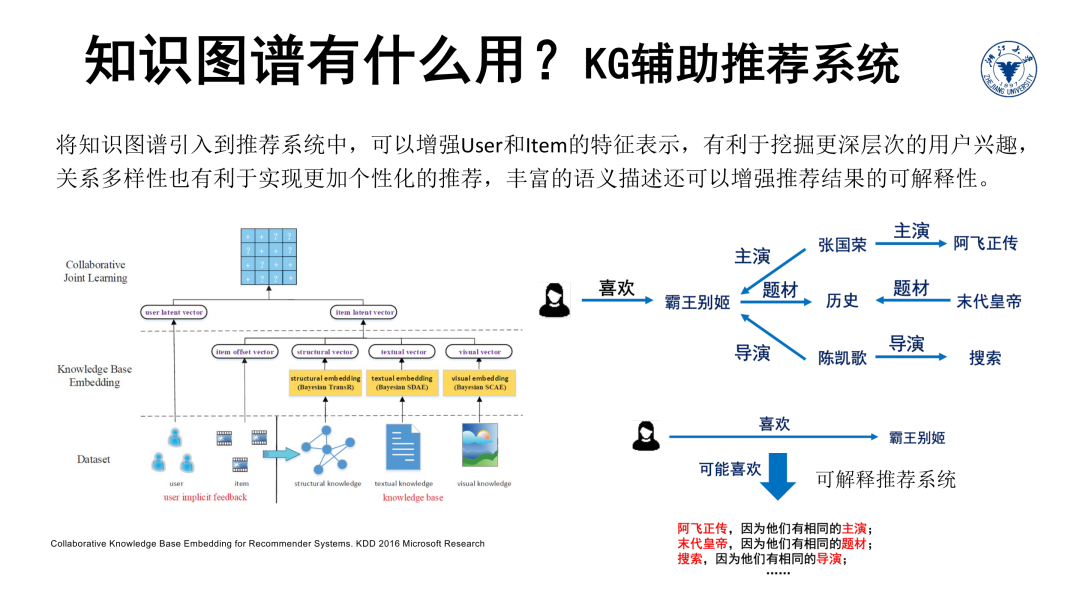
但我们发现机器基本和瞎猜差不多。这是因为单纯从句子的字面,不论你怎么统计、计算、匹配都没有关于Trophy和Suitcase的空间大小的信息,机器自然无法做出判断。我们人可以迅速地做出正确的判断,这是因为人在判断时引入了大脑中的常识知识,即:Trophy通常是被装入Suitcase携带的,所以Suitecase肯定要比Trophy大。在后面的课程中,我们会专门介绍在自然语言处理模型中植入知识图谱的方法。


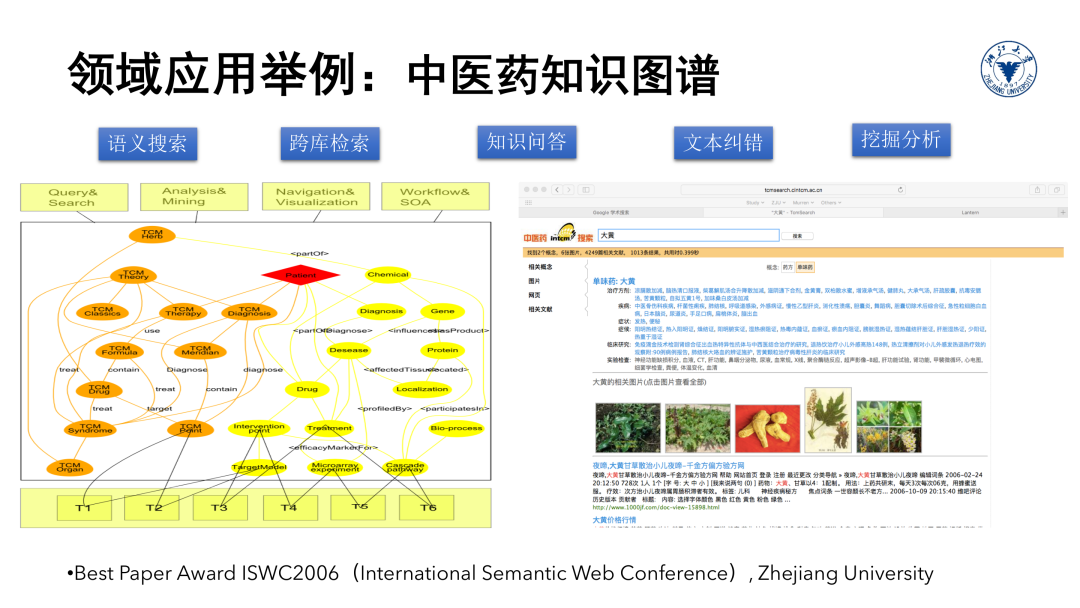
我们从2000年开始尝试将语义网技术引入到中医药领域,基本的想法是希望通过构建一个中间本体,把中医和西医的概念和数据关联起来,然后在此基础之上实现语义搜索、跨库检索、知识问答、文本纠错和集成挖掘分析等功能。
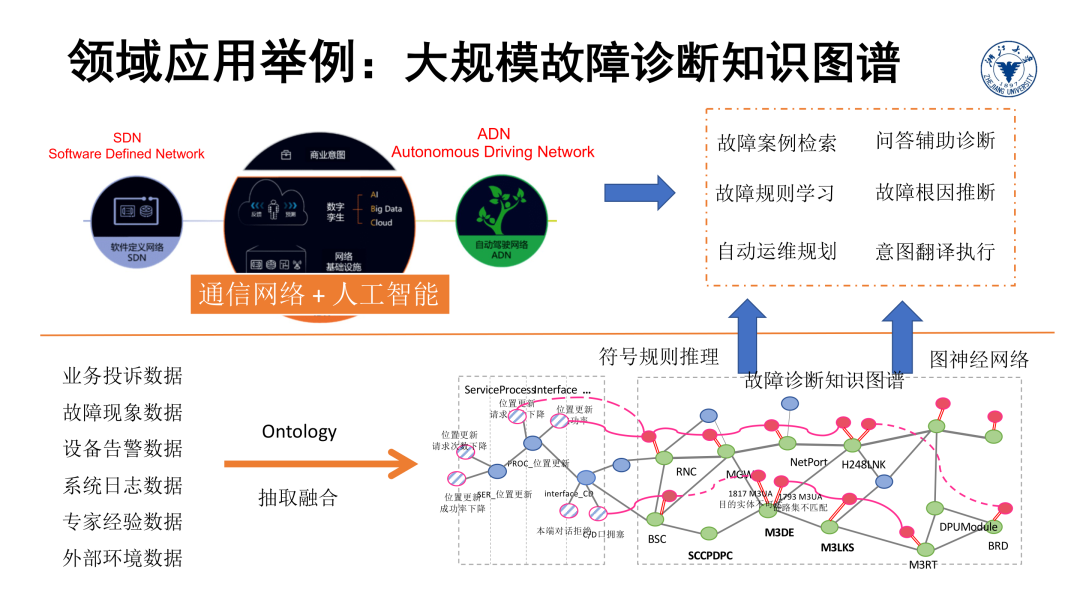
这个应用场景具有更一般化的通用性,给大型网络设备做诊断和维护类似于医生给病人看病,或者在金融场景中对股市异常做出根因判断等都和这个应用场景比较相似。知识图谱在这里起的主要作用是融合多来源的数据,并能基于知识图谱提供的推理能力实现高效率的决策分析功能。
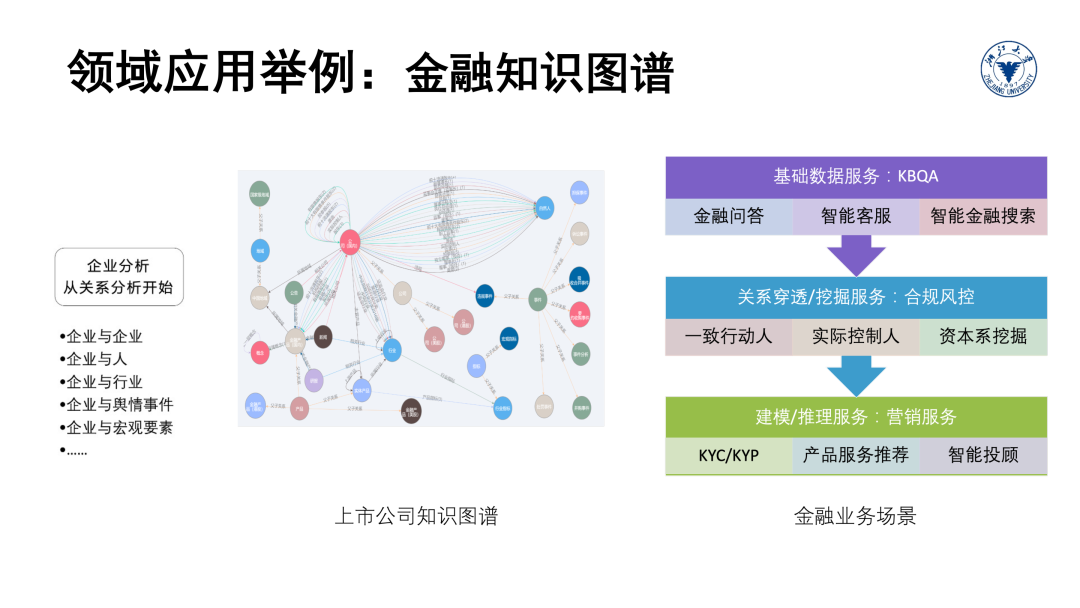


不论是语言理解和视觉理解,外源知识库的引入都可以有力的提升语义理解的深度和广度。知识图谱在医疗、金融、电商、通信等多个垂直领域都有着广泛的应用,并且每个领域都有其独特的实现和实践方式。
# AAAI2022 | KCL: 化学元素知识图谱指导下的分子图对比学习
# 浙大图谱讲义 | 第一讲-知识图谱概论 — 第2节-知识图谱的起源
# 浙大图谱讲义 | 第一讲-知识图谱概论 — 第1节-语言与知识
# OpenKG开源系列 | 轻量级知识图谱抽取开源工具OpenUE
# Expert Systems With Applications | 基于级联双向胶囊网络的鲁棒三元组知识抽取

浙江大学知识图谱创新研究团队
评论