
【NLP】文本分类还停留在BERT?对偶比学习框架也太强了
论文简介:对偶对比学习:如何将对比学习用于有监督文本分类
论文标题:Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
论文链接:https://arxiv.org/pdf/1905.09788.pdf
代码链接:https://github.com/hiyouga/dual-contrastive-learning
论文作者:{Qianben Chen}
论文摘要
对比学习在无监督环境下通过自我监督进行表征学习方面取得了显著的成功。然而,有效地使对比学习适应于监督学习任务在实践中仍然是一个挑战。在这项工作中,作者提出了一个对偶对比学习(DualCL)框架,在同一空间内同时学习输入样本的特征和分类器的参数。具体来说,DualCL将分类器的参数视为关联到不同标签的增强样本,然后利用其进行输入样本和增强样本之间的对比学习。对5个基准文本分类数据集及对应低资源版本数据集的实验研究表明,DualCL分类精度明显得到提高,并证实了DualCL能够实现样本判别表示的效果。
DualCL简介
表示法学习是当前深度学习的核心。在无监督学习的背景下,对比学习最近已被证明是获得下游任务的通用表征的有效方法。简单地说,无监督对比学习采用了一个损失函数,它迫使同一样本的不同“视角”的表示向量相似,而不同样本的表示向量则不同。最近对比学习的有效性方面被证明是由于同时实现了“对齐性”【alignment】和“一致性”【uniformity】。
对比学习方法也适用于监督表示学习 ,以往研究中也使用了类似的对比损失,基本原理是坚持同一类中样本的表示是相似的,不同类的样本表示是相似的。 清楚的。 然而,尽管取得了成功,但与无监督对比学习相比,这种方法的原则性似乎要差得多。 例如,表示的统一性不再有效; 也不是必需的,通俗来讲就是特征的在空间分布不再均匀,所以我们认为标准的监督对比学习方法对于监督表示学习来说并不自然。 另外存在一个事实就是,即这种对比学习方法的结果并没有直接给我们一个分类器,需要开发另一种分类算法来解决分类任务。
接下来我们讲讲DualCL提出的动机,作者为了旨在开发一种更自然的方法来实现在监督任务下的对比学习。作者关键动机是监督表示学习应该包括学习两种参数:一个是输入在适当的空间特征,用来满足分类任务需求,另一个是分类器的参数,或者作用于分类器空间的参数;我们将这个分类器称为的“one example”分类器。在这种观点下,自然将样本联想到两种参数:一个为维度为的,用来表示特征;一个是分类器参数,其中代表样本中分类总数。那么有监督的表示学习可以认为是为输入样本生成。
为了保证分类器对于特征有效,只需要保证与样本的标签保持对齐,可以通过softmax归一化的概率与交叉熵进行约束。除此之外,在对比学习方法可以用来强制对这些表示进行约束,具体来讲,我们将记为样本的真实标签对应分类器的理想参数,这里我们可以设计两种对比损失。第一个loss用来对比与多个,其中代表与样本不同类别的样本特征;第二个loss用来对比与多个,其中代表样本的不同类别对应分类器参数,作者将这种学习框架叫做dual contrastive learning(DualCL),对偶对比学习。
在对比学习基础之上,正如论文标题,DualCL可以认为是一种独特的数据增强方法。具体来说,对于每个样本,其的每一列都可以被视为“标签启发的输入表示”,或者是在特征空间中注入了标签信息的的增强视图。表1中说明了这种方法的强大之处,从左边的两个图片可以看出,标准的对比学习不能利用标签信息。相反,从右边的两个图来看,DualCL有效地利用标签信息对其类中的输入样本进行分类。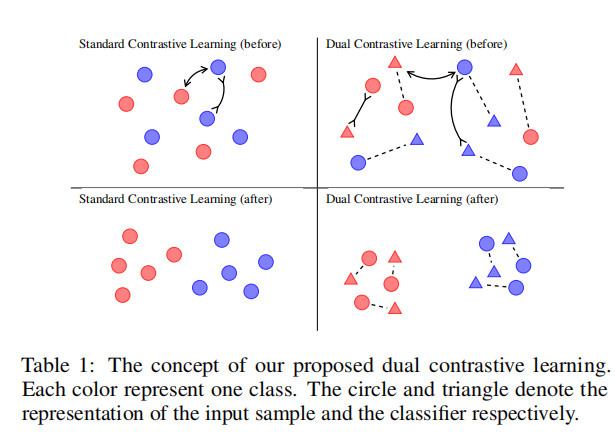
在论文实验中,作者在5个基准文本分类数据集上验证了DualCL的有效性。通过使用对偶比损失对预先训练好的语言模型(BERT和RoBERTa)进行微调,DualCL与现有的对比学习监督基线相比获得了最好的性能。作者还发现,DualCL提高了分类精度,特别是在低资源的场景下。此外通过可视化所学习的表征和注意力图,对DualCL给出了一些可解释性分析。
论文贡献可以总结如下:
1)提出了双对比学习(DualCL),自然地将对比损失与有监督任务相结合; 2)引入标签感知数据增强来获得输入样本的多个视图,用于DualCL的训练; 3)在5个基准文本分类数据集上实证验证了DualCL框架的有效性;
DualCL原理
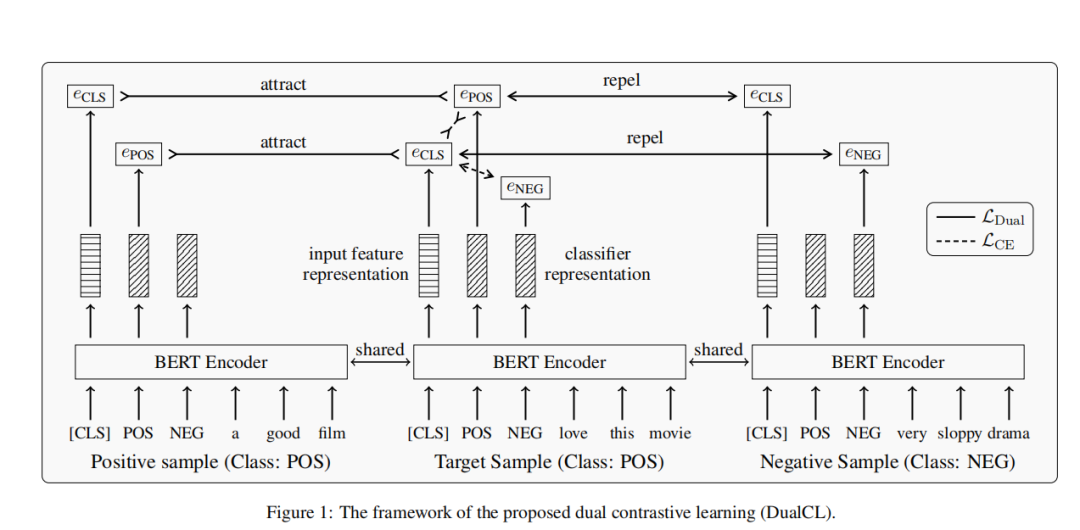 “对偶”表示有监督的对比学习方法目的就是:第一个是在适当空间中对分类任务的输入进行判别表示,第二个是构建监督任务的分类器,学习到分类器空间中分类器的参数。接下来我们看看DualCL的核心部分。
“对偶”表示有监督的对比学习方法目的就是:第一个是在适当空间中对分类任务的输入进行判别表示,第二个是构建监督任务的分类器,学习到分类器空间中分类器的参数。接下来我们看看DualCL的核心部分。
标签启发式的数据增强
为了获得训练样本的不同视图(views)表示,作者利用数据增强的思想来获得特征和分类器的表示。具体来讲就是将分类器每个类别的对应参数作为的独特表示,记为,称为标签感知输入表示,将标签信息注入到的,作为额外增强视图。
在实践中,将标签集合插入到输入序列,可以得到一个新的输入序列,然后通过PLMS(Bert或者Roberta)模型作为编码器,来获取输入序列的每个token特征,其中[CLS]特征作为样本的特征,插入的标签对应为标签启发的输入表示。标签的名称作为标记,形成序列,如“positive”、“negative”等。对于包含多个单词的标签,我们采用token特征的平均池化来获得具有标签感知的输入表示。这个操作和之前一篇论文很相似,大家可以有兴趣可以阅读:Bert还可以这么用:融合标签向量到BERT
对偶对比损失
利用输入样本的特征表示和分类器,DualCL作用就是将的softmax归一化概率与的标签对齐。将表示的某一列,对应于的真实标签索引,DualCL期望点积是最大化的。为了学习更好的和,DualCL利用不同训练样本之间的关系定义了对偶对比损失,如果与有相同的标签,那么试图最大化,而如果与有不同的标签,则最小化。
给定一个来自输入样本的锚点,是正样本集合,是负样本集合,关于z的对比损失可以定义如下: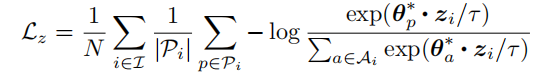
同理,给定一个来自输入样本的锚点,是正样本集合,是负样本集合,关于z的对比损失可以定义如下: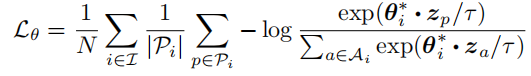
对偶比损失是上述两个对比损失项的组合:
对比训练和有监督预测
为了充分利用监督信号,DualCL还期望是一个很好的分类器。因此作者使用一个改进版本的交叉熵损失来最大化每个输入样本的:
最后,最小化这两个训练目标来训练编码器。这两个目标同时提高了特征的表示质量和分类器的表示质量。总体损失应为:
其中,是一个控制双对比损失项权重的超参数。
在分类过程中,我们使用训练好的编码器来生成输入句子的特征表示和分类器。这里的可以看作是一个“one-example”的分类器,例如,我们将的argmax结果作为模型预测:
图1说明了对偶对比学习的框架,其中是特征表示,和是分类器表示。在这个具体的例子中,我们假设具有“positive”类的目标样本作为锚点,并且有一个正样本具有相同的类标签,而有一个具有不同的类标签的负样本。对偶对比损失旨在同时将特征表示吸引到正样本之间的分类器表示上,并将特征表示排斥到负样本之间的分类器上。
表示之间的对偶性
对比损失采用点积函数作为表示之间相似性的度量,这就使得DualCL中的特征表示和分类器表示之间存在双重关系。在线性分类器中,输入特征与参数之间的关系也出现了类似的现象。然后我们可以将看作是一个线性分类器的参数,这样预先训练好的编码器就可以为每个输入样本生成一个线性分类器。因此,DualCL很自然地学习如何为每个输入样本生成一个线性分类器来执行分类任务。
实验设置
数据集
论文采用了SST-2、SUBJ、TREC、PC和CR四种数据集,数据集相关统计如下: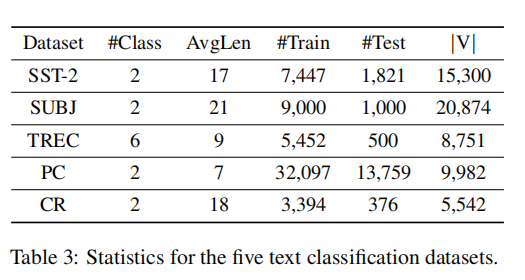
实验结果
从结果中可以看出,除了使用RoBERTa的TREC数据集外,同时使用BERT和RoBERTa编码器在几乎所有设置中都取得了最好的分类性能。与具有完整训练数据的CE+CL相比,DualCL对BERT和RoBERTa的平均改善率分别为0.46%和0.39%。此外,我们观察到,在10%的训练数据下,DualCL的性能明显大于CE+CL方法,在BERT和RoBERTa上分别高出0.74%和0.51%。同时,CE 和 CE+SCL 的性能无法超越 DualCL。 这是因为CE方法忽略了样本之间的关系,CE+SCL方法不能直接学习分类任务的分类器。
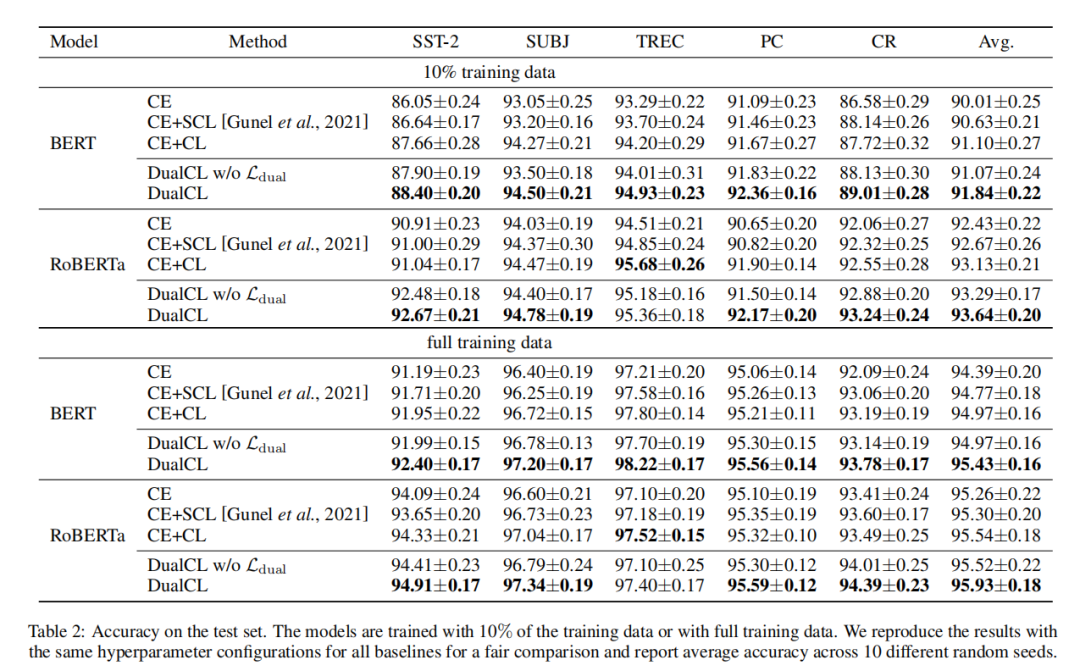 此外论文发现双重对比损失项有助于模型在所有五个数据集上实现更好的性能。 它表明利用样本之间的关系有助于模型在对比学习中学习更好的表示。
此外论文发现双重对比损失项有助于模型在所有五个数据集上实现更好的性能。 它表明利用样本之间的关系有助于模型在对比学习中学习更好的表示。

案例分析
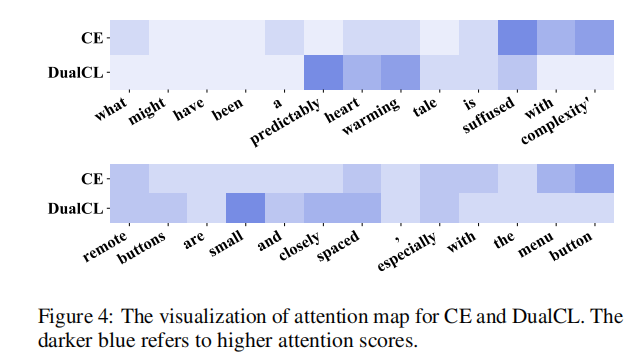
为了验证DualCL是否能够捕获信息特征,作者还计算了[CLS]标记的特征与句子中每个单词之间的注意得分。首先在整个训练集上微调RoBERTa编码器。然后我们计算特征之间的距离,并可视化图4中的注意图。结果表明,在对情绪进行分类时,所捕获的特征是不同的。上面的例子来自SST-2数据集,我们可以看到我们的模型更关注表达“积极”情绪的句子“predictably heart warming”。下面的例子来自CR数据集,我们可以看到我们的模型对表达“消极”情绪的句子更关注“small”。相反,CE方法没有集中于这些鉴别特征。结果表明DualCL能够成功地处理句子中的信息性关键词。
论文总结
在本研究中,从文本分类任务的角度,提出了一种对偶对比学习方法DualCL,来解决监督学习任务。 在DualCL中,作者使用PLMs同时学习两种表示形式。一个是输入示例的鉴别特征,另一个是该示例的分类器。我们引入了具有标签感知的数据增强功能来生成输入样本的不同视图,其中包含特征和分类器。然后设计了一个对偶对比损失,使分类器对输入特征有效。 对偶对比损失利用训练样本之间的监督信号来学习更好的表示,通过大量的实验验证了对偶对比学习的有效性。
核心代码
关于Dual-Contrastive-Learning实现,大家可以查看开源代码:
https://github.com/hiyouga/Dual-Contrastive-Learning/blob/main/main_polarity.py
def _contrast_loss(self, cls_feature, label_feature, labels):
normed_cls_feature = F.normalize(cls_feature, dim=-1)
normed_label_feature = F.normalize(label_feature, dim=-1)
list_con_loss = []
BS, LABEL_CLASS, HS = normed_label_feature.shape
normed_positive_label_feature = torch.gather(normed_label_feature, dim=1,
index=labels.reshape(-1, 1, 1).expand(-1, 1, HS)).squeeze(1) # (bs, 768)
if "1" in self.opt.contrast_mode:
loss1 = self._calculate_contrast_loss(normed_positive_label_feature, normed_cls_feature, labels)
list_con_loss.append(loss1)
if "2" in self.opt.contrast_mode:
loss2 = self._calculate_contrast_loss(normed_cls_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss2)
if "3" in self.opt.contrast_mode:
loss3 = self._calculate_contrast_loss(normed_positive_label_feature, normed_positive_label_feature, labels)
list_con_loss.append(loss3)
if "4" in self.opt.contrast_mode:
loss4 = self._calculate_contrast_loss(normed_cls_feature, normed_cls_feature, labels)
list_con_loss.append(loss4)
return list_con_loss
def _calculate_contrast_loss(self, anchor, target, labels, mu=1.0):
BS = len(labels)
with torch.no_grad():
labels = labels.reshape(-1, 1)
mask = torch.eq(labels, labels.T) # (bs, bs)
# compute temperature using mask
temperature_matrix = torch.where(mask == True, mu * torch.ones_like(mask),
1 / self.opt.temperature * torch.ones_like(mask)).to(self.opt.device)
# # mask-out self-contrast cases, 即自身对自身不考虑在内
# logits_mask = torch.scatter(
# torch.ones_like(mask),
# 1,
# torch.arange(BS).view(-1, 1).to(self.opt.device),
# 0
# )
# mask = mask * logits_mask
# compute logits
anchor_dot_target = torch.multiply(torch.matmul(anchor, target.T), temperature_matrix) # (bs, bs)
# for numerical stability
logits_max, _ = torch.max(anchor_dot_target, dim=1, keepdim=True)
logits = anchor_dot_target - logits_max.detach() # (bs, bs)
# compute log_prob
exp_logits = torch.exp(logits) # (bs, bs)
exp_logits = exp_logits - torch.diag_embed(torch.diag(exp_logits)) # 减去对角线元素,对自身不可以
log_prob = logits - torch.log(exp_logits.sum(dim=1, keepdim=True) + 1e-12) # (bs, bs)
# in case that mask.sum(1) has no zero
mask_sum = mask.sum(dim=1)
mask_sum = torch.where(mask_sum == 0, torch.ones_like(mask_sum), mask_sum)
# compute mean of log-likelihood over positive
mean_log_prob_pos = (mask * log_prob).sum(dim=1) / mask_sum.detach()
loss = - mean_log_prob_pos.mean()
return loss
参考资料
ICML 2020: 从Alignment 和 Uniformity的角度理解对比表征学习
https://blog.csdn.net/c2a2o2/article/details/117898108
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: