
【CV】10分钟理解Focal loss数学原理与Pytorch代码
原文链接:https://amaarora.github.io/2020/06/29/FocalLoss.html
原文作者:Aman Arora
Focal loss 是一个在目标检测领域常用的损失函数。最近看到一篇博客,趁这个机会,学习和翻译一下,与大家一起交流和分享。
在这篇博客中,我们将会理解什么是Focal loss,并且什么时候应该使用它。同时我们会深入理解下其背后的数学原理与pytorch 实现.
什么是Focal loss,它是用来干嘛的? 为什么Focal loss有效,其中的原理是什么? Alpha and Gamma? 怎么在代码中实现它? Credits
什么是Focal loss,它是用来干嘛的?
在了解什么是Focal Loss以及有关它的所有详细信息之前,我们首先快速直观地了解Focal Loss的实际作用。Focal loss最早是 He et al 在论文 Focal Loss for Dense Object Detection 中实现的。
在这篇文章发表之前,对象检测实际上一直被认为是一个很难解决的问题,尤其是很难检测图像中的小尺寸对象。请参见下面的示例,与其他图片相比,摩托车的尺寸相对较小, 所以该模型无法很好地预测摩托车的存在。

因此,Focal loss在样本不平衡的情况下特别有用。特别是在“对象检测”的情况下,大多数像素通常都是背景,图像中只有很少数的像素具有我们感兴趣的对象。
这是经过Focal loss训练后同一模型对同样图片的预测。

那么为什么Focal loss有效,其中的原理是什么?
既然我们已经看到了“Focal loss”可以做什么的一个例子,接下来让我们尝试去理解为什么它可以起作用。下面是了解Focal loss的最重要的一张图:
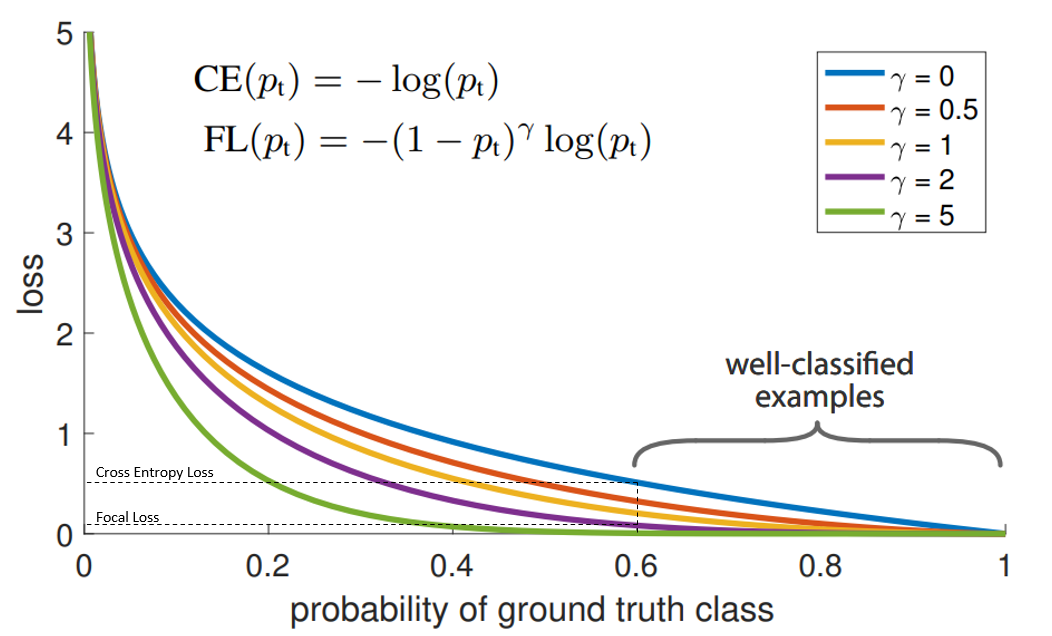
在上图中,“蓝”线代表交叉熵损失。X轴即“预测为真实标签的概率”(为简单起见,将其称为pt)。举例来说,假设模型预测某物是自行车的概率为0.6,而它确实是自行车, 在这种情况下的pt为0.6。而如果同样的情况下对象不是自行车。则pt为0.4,因为此处的真实标签是0,而对象不是自行车的概率为0.4(1-0.6)。
Y轴是给定pt后Focal loss和CE的loss的值。
从图像中可以看出,当模型预测为真实标签的概率为0.6左右时,交叉熵损失仍在0.5左右。因此,为了在训练过程中减少损失,我们的模型将必须以更高的概率来预测到真实标签。换句话说,交叉熵损失要求模型对自己的预测非常有信心。但这也同样会给模型表现带来负面影响。
深度学习模型会变得过度自信, 因此模型的泛化能力会下降.
这个模型过度自信的问题同样在另一篇出色的论文 Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with Dirichlet calibration 被强调过。
另外,作为重新思考计算机视觉的初始架构的一部分而引入的标签平滑是解决该问题的另一种方法。
Focal loss与上述解决方案不同。从比较Focal loss与CrossEntropy的图表可以看出,当使用γ> 1的Focal Loss可以减少“分类得好的样本”或者说“模型预测正确概率大”的样本的训练损失,而对于“难以分类的示例”,比如预测概率小于0.5的,则不会减小太多损失。因此,在数据类别不平衡的情况下,会让模型的注意力放在稀少的类别上,因为这些类别的样本见过的少,比较难分。
Focal loss的数学定义如下:
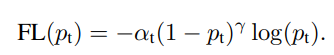
Alpha and Gamma?
那么在Focal loss 中的alpha和gamma是什么呢?我们会将alpha记为α,gamma记为γ。
我们可以这样来理解fig3
γ控制曲线的形状.γ的值越大, 好分类样本的loss就越小, 我们就可以把模型的注意力投向那些难分类的样本. 一个大的γ让获得小loss的样本范围扩大了.
同时,当γ=0时,这个表达式就退化成了Cross Entropy Loss,众所周知地

定义“ pt”如下,按照其真实意义:
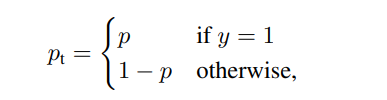
将上述两个式子合并,Cross Entropy Loss其实就变成了下式。

现在我们知道了γ的作用,那么α是干什么的呢?
除了Focal loss以外,另一种处理类别不均衡的方法是引入权重。给稀有类别以高权重,给统治地位的类或普通类以小权重。这些权重我们也可以用α表示。
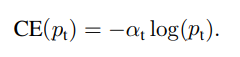
alpha-CE
加上了这些权重确实帮助处理了类别的 不均衡,focal loss的论文报道:
类间不均衡较大会导致,交叉熵损失在训练的时候收到影响。易分类的样本的分类错误的损失占了整体损失的绝大部分,并主导梯度。尽管α平衡了正面/负面例子的重要性,但它并未区分简单/困难例子。
作者想要解释的是:
尽管我们加上了α, 它也确实对不同的类别加上了不同的权重, 从而平衡了正负样本的重要性 ,但在大多数例子中,只做这个是不够的. 我们同样要做的是减少容易分类的样本分类错误的损失。因为不然的话,这些容易分类的样本就主导了我们的训练.
那么Focal loss 怎么处理的呢,它相对交叉熵加上了一个乘性的因子(1 − pt)**γ,从而像我们上面所讲的,降低了易分类样本区间内产生的loss。
再看下Focal loss的表达,是不是清晰了许多。
怎么在代码中实现呢?
这是Focal loss在Pytorch中的实现。
class WeightedFocalLoss(nn.Module):"Non weighted version of Focal Loss"def __init__(self, alpha=.25, gamma=2):super(WeightedFocalLoss, self).__init__()self.alpha = torch.tensor([alpha, 1-alpha]).cuda()self.gamma = gammadef forward(self, inputs, targets):BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')targets = targets.type(torch.long)at = self.alpha.gather(0, targets.data.view(-1))pt = torch.exp(-BCE_loss)F_loss = at*(1-pt)**self.gamma * BCE_lossreturn F_loss.mean()
如果你理解了alpha和gamma的意思,那么这个实现应该都能理解。同时,像文章中提到的一样,这里是对BCE进行因子的相乘。
Credits
贴上作者的 twitter ,当然如果大家有什么问题讨论,也可以在公众号留言。
fig-1andfig-2are from the Fastai 2018 course Lecture-09!
未完待续
今天给大家分享到这里,感谢大家的阅读和支持,我们会继续给大家分享我们的所思所想所学,希望大家都有收获!
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: