
京东开源FaceX-Zoo:PyTorch面部识别工具箱
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


近年来,基于深度学习的人脸识别取得了长足的进展。然而,实际的模型制作和深度人脸识别的进一步研究仍需要相应的公众支持。例如,人脸表示网络的生产需要一个模块化的训练方案,以考虑从各种最先进的骨干候选人和训练监督的现实世界的人脸识别需求的适当选择;对于性能分析和比较,标准和自动评估与一堆模型在多个基准将是一个理想的工具;此外,人脸识别在整体管道形态上的部署也受到了公众的欢迎。此外,还有一些新出现的挑战,如近期全球COVID-19大流行带来的蒙面人脸识别,在实际应用中越来越受到关注。一个可行且优雅的解决方案是构建一个易于使用的统一框架来满足上述需求。为此,作者引入了一个新的开源框架,命名为FaceX-Zoo,它是面向人脸识别的研发社区。采取高度模块化和可伸缩设计,FaceX-Zoo提供一个培训模块各种监督头和脊椎state-of-theart人脸识别,以及标准化评价模块使评价模型在大多数流行的基准只是通过编辑一个简单的配置。此外,还提供了一个简单但功能齐全的face SDK,用于验证和培训模型的主要应用。作者没有尽可能多地采用先前的技术,而是使FaceX-Zoo能够随着面部相关领域的发展而轻松地升级和扩展。
代码链接:https://github.com/JDAI-CV/FaceX-Zoo
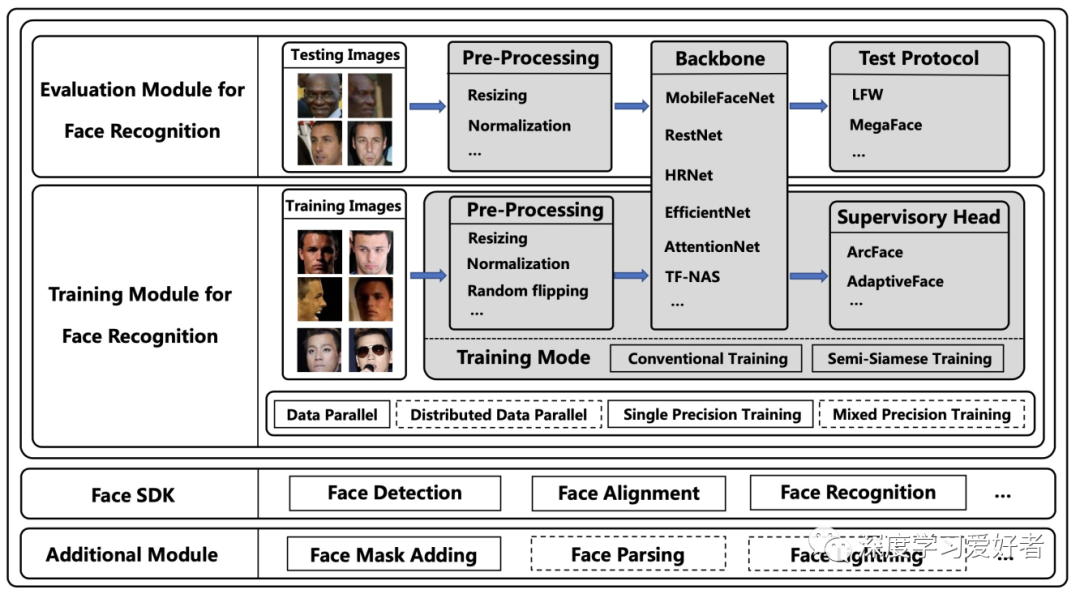
FaceX-Zoo的架构。实框中的模块是当前版本中已经提供的模块,虚线框中的模块将在后续版本中添加
上图巧妙地展示了FaceX-Zoo的总体架构。整个项目主要包括四个部分:培训模块、评估模块、附加模块和face SDK,其中前两个模块是本项目的核心部分。培训和评估模块包括预处理、培训模式、主干、监督负责人和测试协议等几个组成部分。作者将详细说明如下。
预处理:这个模块在将图像发送到网络之前完成图像的基本转换。对于训练,作者实现了常用的操作,如大小调整、归一化、随机裁剪、随机翻转、随机旋转等。可根据不同需求,灵活添加定制操作。对于评估,只使用大小调整和标准化。同样地,测试增强,如五种作物,水平翻转等,也可以通过自定义轻松添加到作者的框架中。
训练模式:将传统的人脸识别训练模式作为基线例程。具体来说,通过DataLoader对训练输入进行调度,然后将训练输入发送到骨干网进行前向传递,最后计算一个准则作为训练损失进行后向更新。此外,作者考虑了人脸识别中的一种实际情况,即使用浅分布数据[11]来训练网络。因此,作者整合了最近的训练策略,以促进浅面数据的训练。
骨干:利用骨干网提取人脸图像的特征。作者在FaceX-Zoo中提供了一系列最先进的骨干架构,如下所示。此外,只要修改配置文件并添加体系结构定义文件,就可以在PyTorch的支持下轻松定制任何其他体系结构选择:
MobileFaceNet:为移动设备上的应用程序提供一个高效的网络。
ResNet:一系列用于通用视觉任务的经典架构。
SE-ResNet:配备SE块的ResNet,重新校准通道的特征响应。
HRNet:深度高分辨率表示学习网络。
EfficientNet:一组在深度、宽度和分辨率之间扩展的架构。
GhostNet:一个旨在通过廉价操作生成更多特征地图的模型。
AttentionNet:一个由注意模块堆叠而成的网络,用来学习注意感知功能。
TF-NAS:由NAS搜索的一系列具有延迟约束的架构
监督:监控头定义为实现人脸准确识别的监控单点及其相应的计算模块。为了学习人脸识别的判别特征,通常对预测的logit进行一些具体的操作,如归一化、缩放、添加边距等,然后再发送到softmax层。作者在FaceX-Zoo中实现了一系列的softmaxstyle损失,如下:
AM-Softmax:在目标logit上增加余数保证金惩罚的附加保证金损失。
ArcFace:一个附加的角度边距损失,在目标角度上增加边距惩罚。
AdaCos:基于余弦的softmax损耗,超参数无和自适应缩放。
AdaM-Softmax:自适应margin loss,可以自适应地调整不同类别的margin。
CircleLoss:一个统一的公式,用类级标签和成对标签学习。
CurricularFace :一个损失函数,在不同的训练阶段,自适应地调整简单和困难样本的重要性。
MV-Softmax:一种损失函数,自适应地强调错误分类的特征向量,指导判别特征学习。NPCFace:一个损失函数,它强调对消极和积极难题的训练。
测试协议:有各种基准来衡量人脸识别模型的准确性。其中许多侧重于特定的人脸识别挑战,比如跨年龄、跨姿势和跨种族。其中常用的测试协议主要基于LFW[18]和megface[20]的基准。作者将这些协议集成到FaceX-Zoo中,使用简单,指令清晰,通过简单的配置,人们可以很容易地在单个或多个基准上测试他们的模型。此外,通过添加测试数据和解析测试对,可以方便地扩展额外的测试协议。值得注意的是,还提供了一个基于megface的蒙面人脸识别基准。
LFW:它包含了从网上收集的13,233张带有姿势、表情和照明变化的身份图像。作者提供了在这个经典基准上10倍交叉验证的平均精度。
CPLFW:包含3930个身份的11322张图像,侧重于跨姿态人脸验证。遵循官方协议,采用10倍交叉验证的平均精度。
CALFW:它包含了4022个身份的12174张图像,旨在跨年龄人脸验证。采用10倍交叉验证的平均精度。
AgeDB30:它包含了12240张图像,440个身份,每个测试对有30岁的年龄差距。作者提供了10倍交叉验证的平均准确性。
RFW:包含了11,430个身份的40,307幅图像,被提出用来测量人脸识别中潜在的种族偏见。RFW中有四个测试子集,分别为African, Asian, Caucasian和Indian,作者分别提供每个子集的平均准确率。
megface:它包含80个探测身份和100万个画廊干扰物,旨在评估大规模的人脸识别性能。作者提供了megface的k级识别准确性。
megface - mask:它包含与megface相同的探测身份和图库干扰物,而每个探测图像都由一个虚拟面具添加。该协议旨在评估大规模蒙面人脸识别的性能。
Background:由于最近全球COVID- 19大流行,蒙面人脸识别已成为许多场景下的关键应用需求。然而,用于训练和评估的掩蔽人脸数据集很少。为了解决这个问题,作者授权了FaceX-Zoo的框架,通过名为FMA-3D (3D-based face mask Adding)的专门模块,在现有的人脸图像中添加虚拟面具。
FMA-3D:给定一个真正的戴面具的脸图像(图2 (a))和B non-masked脸图像(图2 (d)),作者合成一个写实的戴面具的脸图像的面具和面部区域B。首先,作者利用一个面具分割模型[23]从图像中提取面具区域(图2 (B)),然后映射纹理映射到UV空间真实感三维人脸重建方法PRNet[12](图2 (c))。对于图像B,作者采用与A相同的方法计算UV空间中的纹理贴图(图2(e))。接下来,作者在UV空间中混合蒙版纹理贴图和人脸纹理贴图,如图2(f)所示。最后,根据图像b的UV位置图绘制混合纹理图,合成出蒙面图像(图2(g))。图3为FMA-3D合成的更多蒙面图像。与基于2d和基于gan的方法相比,作者的方法在鲁棒性和保真性方面表现出了优异的性能,特别是对于大的头部姿态。
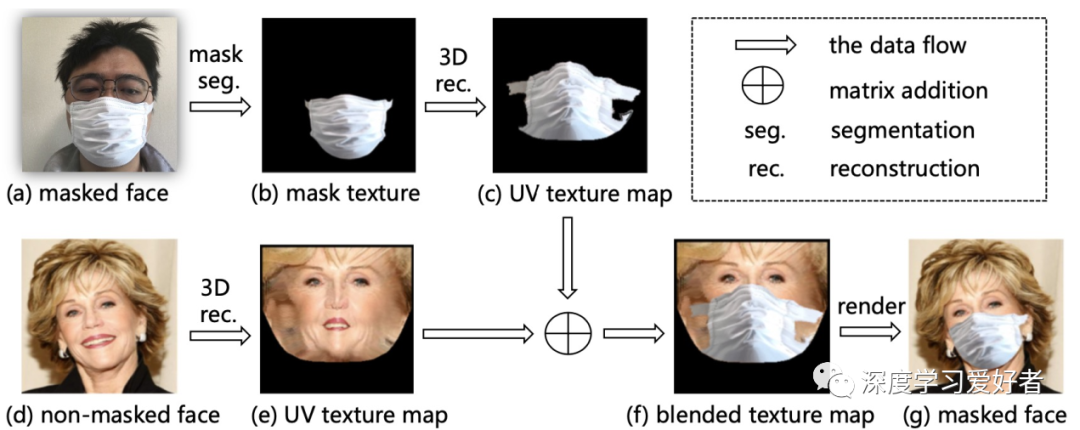
图2:在人脸图像上佩戴虚拟口罩的方法。蒙版模板可以根据输入的蒙版面从多种选择中采样

图3 上层:原始的未蒙面的人脸图像。下层:FMA-3D合成的蒙面人脸图像。
训练蒙面人脸识别模型。借助作者的FMA-3D,可以方便地从现有的非掩模数据集中合成大量的掩模人脸图像,如MS-Celeb-1M-v1c。由于现有的数据集已经有了ID标注,作者可以直接使用它们来训练人脸识别网络,而不需要额外的标注。训练方法可以是传统的常规或SST,以及训练头和骨干可以实例化与FaceXZoo集成的选择。注意,测试基准可以以相同的方式从非屏蔽版本扩展到屏蔽版本。
实验和结果:利用FMA-3D,作者将MS-Celeb1M-v1c的训练数据合成为其掩码版本MS-Celeb1M-v1c- mask。它包括MSCeleb1M-v1c中每个身份的原始人脸图像,以及与原始人脸对应的蒙面人脸图像。作者选择MobileFaceNet作为骨干,MV-Softmax作为监控头。该模型经过18个epochs的训练,批量大小为512。学习速率初始化为0:1,然后在epoch选择10, 13和16。为了对模型进行蒙面识别任务的评价,作者利用FMA-3D合成了基于megface的蒙面数据集,命名为megface -mask,其中包含了蒙面探针图像,保留了未蒙面画廊图像。如图4所示
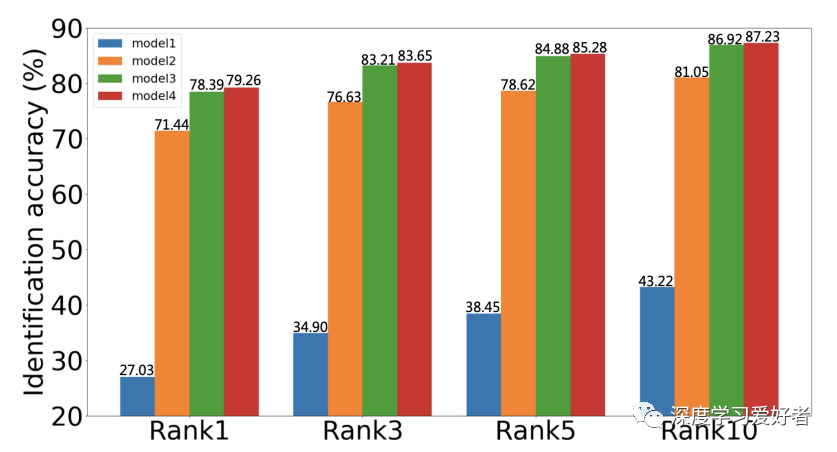
图4
在未来,作者将从广度、深度和效率三个方面对FaceX-Zoo进行改进。首先,将包含更多的附加模块,如face解析和face lightning,从而丰富FaceX-Zoo中的X功能。第二,随着深度学习技术的发展,骨干架构和监督负责人模块将不断得到补充。第三,通过分布式数据并行技术和混合精度训练来提高训练效率
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~