
基于实际业务场景下的Flume部署
点击上方蓝色字体,选择“设为星标”




有这样一个场景,我们要基于某个web服务实时持续收集用户行为数据;
再实施方案前,我们做了以下的准备工作 (不细说)
web服务端部署nginx,用于收集用户行为并有形成log (172.17.111.111)
我们数据平台是部署在Hadoop,数据最终固化到hdfs中 (172.22.222.17-19)
数据平台和产生行为日志的机器最好同一个机房,网络环境要保持良好 (废话)
最终方案和技术选型
采用flume服务收集日志
收集的日志目的地统一为kafka
sparkstreaming消费kafka数据并固化到hdfs (hive或者kudu等等)
flume采用分布式部署结构
-- 1.web端服务充当发送端
-- 2.大数据平台的agent组成集群充当接受端
-- 3.agent跟agent交互通过type=avro
部署flume服务
还有一种方式就是在所在web工程引入flume的log4j代码,但这样会与原有代码冲突,改动大不考虑
下载flume并解压 (web服务所在的机器 172.17.111.111)
#下载
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
#解压
tar -zxvf apache-flume-1.8.0-bin.tar.gz
#移到 /opt目录下
mv /home/apache-flume-1.8.0-bin /opt/flume-1.8.0修改配置文件
cd /opt/flume-1.8.0/conf
vi flume-conf.properties
#添加以下内容
#命名agent各元素
agent.sources=source1
agent.channels=channel1
#这里定义了三个sink,主要是为了把日志消息轮询发到这三个sink上面
#这三个sink分别又为大数据平台的flume agent
agent.sinks=sink1 sink2 sink3
#source1描述
agent.sources.source1.type=exec
#agent来源, 即日志位置
agent.sources.source1.command=tail -F /usr/local/nginx/logs/dev-biwx.belle.net.cn.log
agent.sources.source1.channels=channel1
#sink1描述, 用于被slave1(172.22.222.17) agent接受
agent.sinks.sink1.type=avro
agent.sinks.sink1.channel=channel1
agent.sinks.sink1.hostname=172.22.222.17
agent.sinks.sink1.port=10000
agent.sinks.sink1.connect-timeout=200000
#sink2描述, 用于被slave2(172.22.222.18) agent接受
agent.sinks.sink2.type=avro
agent.sinks.sink2.channel=channel1
agent.sinks.sink2.hostname=172.22.222.18
agent.sinks.sink2.port=10000
agent.sinks.sink2.connect-timeout=200000
#sink2描述, 用于被slave3(172.22.222.19) agent接受
agent.sinks.sink3.type=avro
agent.sinks.sink3.channel=channel1
agent.sinks.sink3.hostname=172.22.222.19
agent.sinks.sink3.port=10000
agent.sinks.sink3.connect-timeout=200000
#定义sinkgroup,消息轮询发到这个组内的agent
agent.sinkgroups = g1
agent.sinkgroups.g1.sinks=sink1 sink2 sink3
agent.sinkgroups.g1.processor.type = load_balance
agent.sinkgroups.g1.processor.selector = round_robin
#channel1描述
agent.channels.channel1.type = file
agent.channels.channel1.checkpointDir=/var/checkpoint
agent.channels.channel1.dataDirs=/var/tmp
agent.channels.channel1.capacity = 10000
agent.channels.channel1.transactionCapactiy = 100
#绑定 source 和 sink 到channel中
agent.sources.source1.channels = channel1
agent.sinks.sink1.channel = channel1
agent.sinks.sink2.channel = channel1
agent.sinks.sink3.channel = channel1
:wq!以上就是web端agent的配置,所有web节点配置都一样;暂时还不能启动,172.22.222.17-19端的agent还没启动;这时候启动会报错
配置接收端agent配置 (基于CDH)

以上是基于CDH看到的 flume 服务实例,注意角色组要不一样
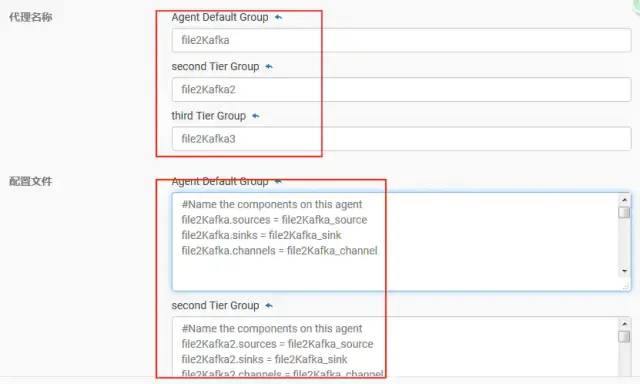
上述的配置文件都很简单,改一下ip和agent名字就好,以下为slave1例子
#Name the components on this agent
file2Kafka.sources = file2Kafka_source
file2Kafka.sinks = file2Kafka_sink
file2Kafka.channels = file2Kafka_channel
# Describe/configure the source
file2Kafka.sources.file2Kafka_source.type = avro
file2Kafka.sources.file2Kafka_source.bind = 172.22.222.17
file2Kafka.sources.file2Kafka_source.port= 10000
# Describe the sink, 目的地是kafka,注意主题为testnginx
file2Kafka.sinks.file2Kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink
file2Kafka.sinks.file2Kafka_sink.kafka.topic = testnginx
file2Kafka.sinks.file2Kafka_sink.kafka.bootstrap.servers = 172.22.222.17:9092,172.22.222.18:9092,172.22.222.20:9092
file2Kafka.sinks.file2Kafka_sink.kafka.flumeBatchSize = 20
# Use a channel which buffers events in memory
file2Kafka.channels.file2Kafka_channel.type = memory
file2Kafka.channels.file2Kafka_channel.capacity =100000
file2Kafka.channels.file2Kafka_channel.dataDirs=10000
# Bind the source and sink to the channel
file2Kafka.sources.file2Kafka_source.channels = file2Kafka_channel
file2Kafka.sources.file2Kafka_source2.channels = file2Kafka_channel
file2Kafka.sources.file2Kafka_source3.channels = file2Kafka_channel
file2Kafka.sinks.file2Kafka_sink.channel = file2Kafka_channel配置好,CDH启动flume服务,务必进入每个agent节点的日志目录查看日志,就算某个agent节点报错,CM界面也不会有提示
#以slave1为例子
cd /var/log/flume-ng
tailf flume-cmf-flume-AGENT-bi-slave1.log假如是以下信息代表正常启动

启动正常后,启动web端agent
./flume-ng agent --conf ../conf -f ../conf/flume-conf.properties --name agent -Dflume.root.logger=INFO,consoleweb端agent和CDH端agent都启动成功后,我们开始测试下
启动kafka模拟消费端
#在kafka所在broker机器中执行命令
./kafka-console-consumer.sh --bootstrap-server 172.22.222.20:9092,172.22.222.17:9092,172.22.222.18:9092 --topic testnginx --from-beginning在所在web服务前端页面操作

这时候在kafka就能看到用户点击行为,也正是nginx记录的内容
不断点击,kafka模拟消费端就能不断看到消息进来。
文章不错?点个【在看】吧! ?